KgCLUE-bert4keras
基于“Seq2Seq+前缀树”的知识图谱问答
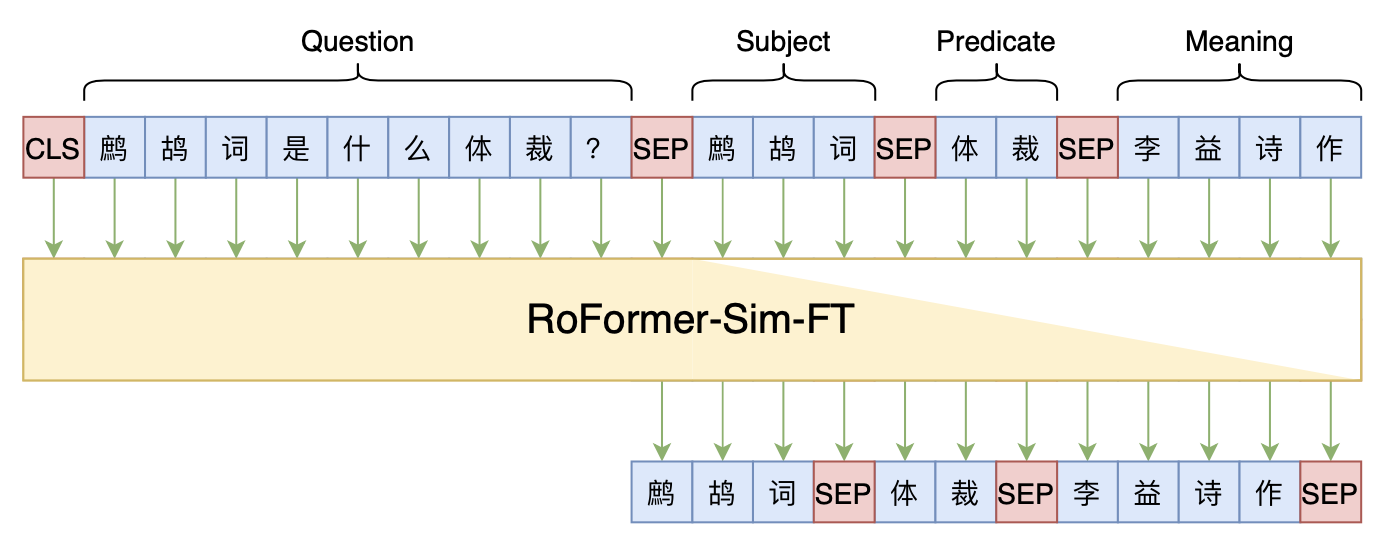
简介
环境
- 软件:bert4keras>=0.10.8
- 硬件:目前的结果是用一张Titan RTX(24G)跑出来的。
运行
- 第一次运行的时候,会给知识库构建前缀树,然后保存下来,这个过程大概需要30分钟左右;
- 如果是第二次运行,那么就会自动加载保存好的前缀树,这个过程大概需要5分钟左右;
- 保存下载的前缀树文件大概1.8G,加载到运行环境中,大概需要30G内存;
- 每个epoch的训练时间是很快的,反而是验证效果时间比较长,跑完训练和测试,大概需要1~2小时。
交流
QQ交流群:808623966,微信群请加机器人微信号spaces_ac_cn

 1 Nov 11, 2021
1 Nov 11, 2021
 44 Jul 28, 2022
44 Jul 28, 2022
 17 Dec 19, 2022
17 Dec 19, 2022
 1.2k Jan 08, 2023
1.2k Jan 08, 2023
 2 Oct 02, 2022
2 Oct 02, 2022
 6 Nov 10, 2022
6 Nov 10, 2022
 10 Jul 17, 2022
10 Jul 17, 2022
 24 Dec 29, 2022
24 Dec 29, 2022
 16 Mar 03, 2022
16 Mar 03, 2022
 1.4k Jan 04, 2023
1.4k Jan 04, 2023
 4 Feb 23, 2022
4 Feb 23, 2022
 760 Jan 03, 2023
760 Jan 03, 2023
 11 Oct 31, 2022
11 Oct 31, 2022
 28 Nov 10, 2022
28 Nov 10, 2022
 20 Dec 25, 2022
20 Dec 25, 2022
 6 Feb 10, 2022
6 Feb 10, 2022
 2 Feb 10, 2022
2 Feb 10, 2022
 201 Nov 09, 2022
201 Nov 09, 2022
 106 Dec 27, 2022
106 Dec 27, 2022
 342 Nov 21, 2022
342 Nov 21, 2022