Enhancing Keyphrase Extraction from Academic Articles with their Reference Information
Overview
Dataset and code for paper "Enhancing Keyphrase Extraction from Academic Articles with their Reference Information".
The research content of this project is to analyze the impact of the introduction of reference title in scientific literature on the effect of keyword extraction. This project uses three datasets: SemEval-2010, PubMed and LIS-2000, which are located in the dataset folder. At the same time, we use two unsupervised methods: TF-IDF and TextRank, and three supervised learning methods: NaiveBayes, CRF and BiLSTM-CRF. The first four are traditional keywords extraction methods, located in the folder ML, and the last one is deep learning method, located in the folder DL.
Directory structure
Keyphrase_Extraction: Root directory
│ dl.bat: Batch commands to run deep learning model
│ ml.bat: Batch commands to run traditional models
│
├─Dataset: Store experimental datasets
│ SemEval-2010: Contains 244 scientific papers
│ PubMed: Contains 1316 scientific papers
│ LIS-2000: Contains 2000 scientific papers
│
├─DL: Store the source code of the deep learning model
│ │ build_path.py: Create file paths for saving preprocessed data
│ │ crf.py: Source code of CRF algorithm implementation(Use pytorch framework)
│ │ main.py: The main function of running the program
│ │ model.py: Source code of BiLSTM-CRF model
│ │ preprocess.py: Source code of preprocessing function
│ │ textrank.py: Source code of TextRank algorithm implementation.
│ │ tf_idf.py: Source code of TF-IDF algorithm implementation.
│ │ utils.py: Some auxiliary functions
│ ├─models: Parameter configuration of deep learning models
│ └─datas
│ tags: Label settings for sequence labeling
│
└─ML: Store the source code of the traditional models
│ build_path.py: Create file paths for saving preprocessed data
│ configs.py: Path configuration file
│ crf.py: Source code of CRF algorithm implementation(Use CRF++ Toolkit)
│ evaluate.py: Source code for result evaluation
│ naivebayes.py: Source code of naivebayes algorithm implementation(Use KEA-3.0 Toolkit)
│ preprocessing.py: Source code of preprocessing function
│ textrank.py: Source code of TextRank algorithm implementation
│ tf_idf.py: Source code of TF-IDF algorithm implementation
│ utils.py: Some auxiliary functions
├─CRF++: CRF++ Toolkit
└─KEA-3.0: KEA-3.0 Toolkit
Dataset Description
The dataset includes the following three json files:
Each line of the json file includes:
Quick Start
In order to facilitate the reproduction of the experimental results, the project uses bat batch command to run the program uniformly (only in Windows Environment). The dl.bat file is the batch command to run the deep learning model, and the ml.bat file is the batch command to run the traditional algorithm.
How does it work?
In the Windows environment, use the key combination Win + R and enter cmd to open the DOS command box, and switch to the project's root directory (Keyphrase_Extraction). Then input dl.bat, that is, run deep learning model to get the result of keyword extraction; Enter ml.bat to run traditional algorithm to get keywords Extract the results.
Experimental results
The following figures show that the influence of reference information on keyphrase extraction results of TF*IDF, TextRank, NB, CRF and BiLSTM-CRF.
Table 1: Keyphrase extraction performance of multiple corpora constructed using different logical structure texts on the dataset of SemEval-2010 
Table 2: Keyphrase extraction performance of multiple corpora constructed using different logical structure texts on the dataset of PubMed 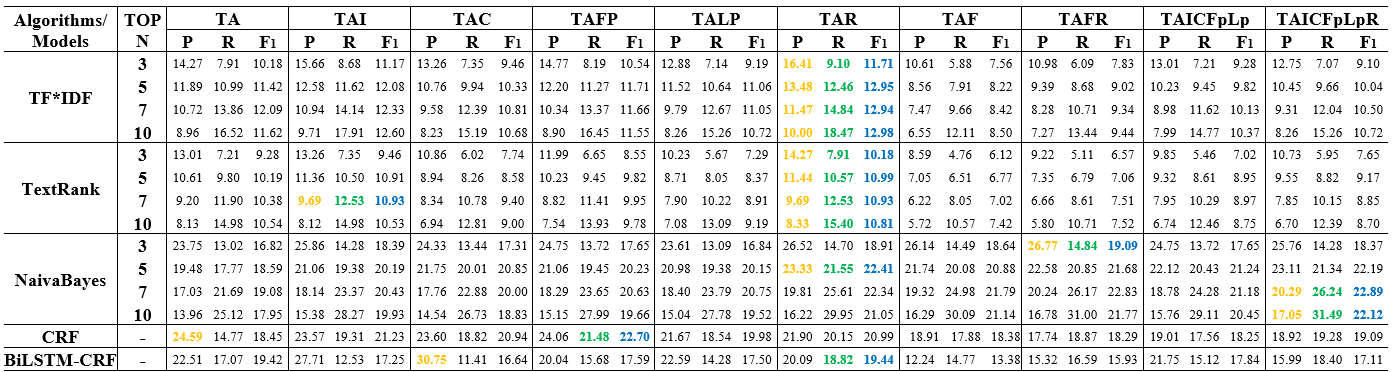
Table 3: Keyphrase extraction performance of multiple corpora constructed using different logical structure texts on the dataset of LIS-2000
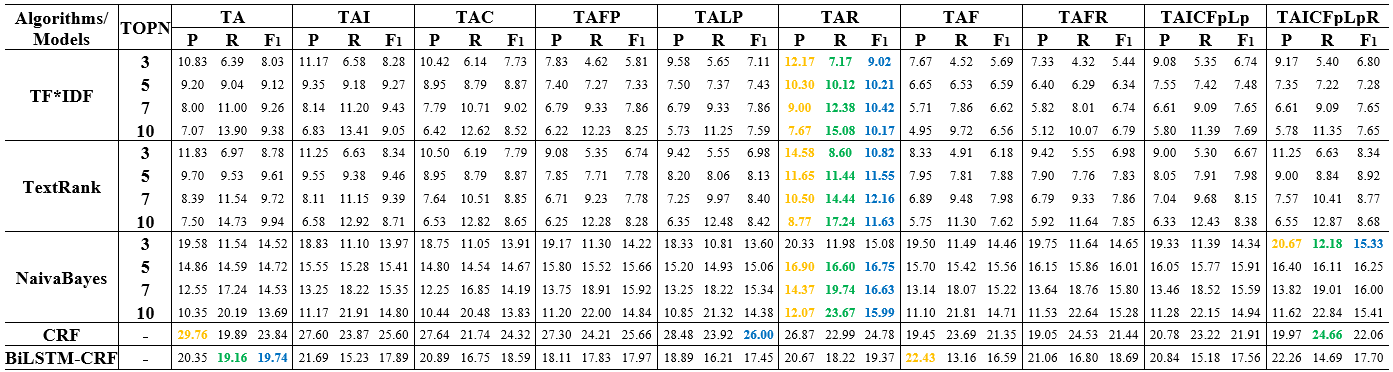
Note: The yellow, green and blue bold fonts in the table represent the largest of the P, R and F1 value obtained from different corpora using the same model, respectively.
Dependency packages
Before running this project, check that the following Python packages are included in your runtime environment.
Citation
Please cite the following paper if you use this codes and dataset in your work.
Chengzhi Zhang, Lei Zhao, Mengyuan Zhao, Yingyi Zhang. Enhancing Keyphrase Extraction from Academic Articles with their Reference Information. Scientometrics, 2021. (in press) [arXiv]

 29 Dec 02, 2022
29 Dec 02, 2022
 844 Dec 28, 2022
844 Dec 28, 2022
 0 Dec 13, 2021
0 Dec 13, 2021
 114 Dec 27, 2022
114 Dec 27, 2022
 1 Jan 20, 2022
1 Jan 20, 2022
 83 Dec 15, 2022
83 Dec 15, 2022
 175 Dec 30, 2022
175 Dec 30, 2022
 115 Dec 18, 2022
115 Dec 18, 2022
 2 Jan 09, 2022
2 Jan 09, 2022
 5.8k Jan 06, 2023
5.8k Jan 06, 2023
 4.7k Dec 29, 2022
4.7k Dec 29, 2022
 77 Nov 30, 2022
77 Nov 30, 2022
 62 Dec 10, 2022
62 Dec 10, 2022
 44 Dec 06, 2022
44 Dec 06, 2022
 423 Dec 07, 2022
423 Dec 07, 2022
 20 Oct 27, 2022
20 Oct 27, 2022
 14 Nov 28, 2022
14 Nov 28, 2022
 3 Jun 18, 2022
3 Jun 18, 2022
 3 Jan 21, 2022
3 Jan 21, 2022
 288 Nov 19, 2022
288 Nov 19, 2022