Streaming Data Pipeline - Kafka + ELK Stack
Streaming weather data using Apache Kafka and Elastic Stack.
Data source: https://openweathermap.org/api
Objectives: Develop a streaming data pipeline to extract weather data from OpenWeather API using Apache Kafka, Logstash, Elasticserach and Kibana (Kafka + ELK Stack).
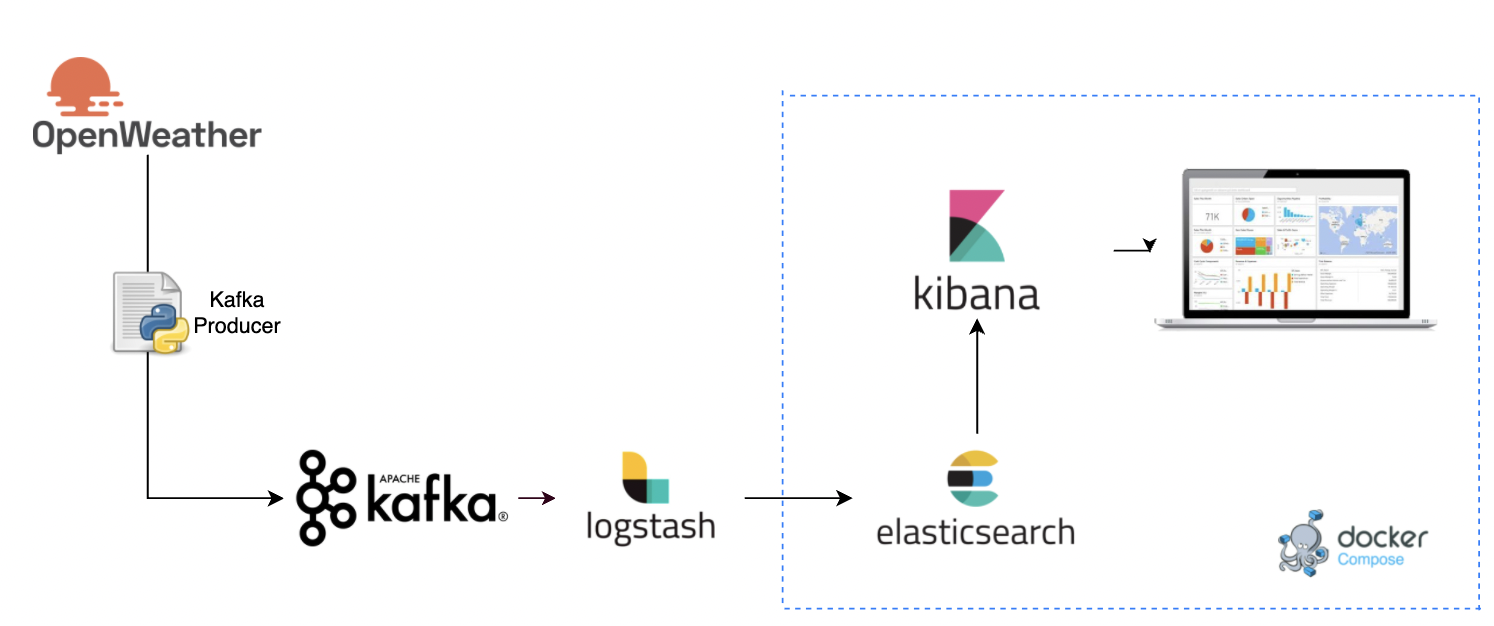
To summarize, Python was used to develop a Kakfa producer that requests weather data from OpenWeather API every minute and sends it as a message to Apache Kafka. Logstash, as a Kafka consumer, consumes the data and stores it into Elasticsearch. Kibana uses the data from Elasticsearch to display the dashboard.
Kibana Weather Dashboard

Steps:
bash elk/start_elastic_docker.shbash kafka/start_kafka_docker.sh- Create a topic using kafka manager:
localhost:9000
Logstash installed locally*
$LOGSTASH_HOME/bin/logstash -f $LOGSTASH_HOME/config/pipeline.conf
Before running Kafka Producer, is needed to set the API key inside the weather_api_key.ini file*
python3 weather_kfk_producer.py- Access Kibana:
localhost:5601 - Create an index pattern: must match with your index name inside
pipeline.conf - Develop your dashboard.

 193 Nov 29, 2022
193 Nov 29, 2022
 2 Dec 02, 2021
2 Dec 02, 2021
 1.2k Jan 07, 2023
1.2k Jan 07, 2023
 11 Dec 13, 2022
11 Dec 13, 2022
 1 Dec 08, 2021
1 Dec 08, 2021
 1 Nov 29, 2021
1 Nov 29, 2021
 44 Sep 28, 2022
44 Sep 28, 2022
 3.3k Jan 04, 2023
3.3k Jan 04, 2023
 293 Dec 29, 2022
293 Dec 29, 2022
 7.2k Dec 30, 2022
7.2k Dec 30, 2022
 9.9k Dec 31, 2022
9.9k Dec 31, 2022
 6 Nov 30, 2022
6 Nov 30, 2022
 48 Dec 21, 2022
48 Dec 21, 2022
 4.7k Jan 09, 2023
4.7k Jan 09, 2023
 19 Nov 24, 2022
19 Nov 24, 2022
 944 Dec 09, 2022
944 Dec 09, 2022
 6 Jun 07, 2022
6 Jun 07, 2022
 1 Oct 22, 2021
1 Oct 22, 2021
 16 Jun 09, 2022
16 Jun 09, 2022