MoroccoAI Data Challenge (Edition #001)
This Reposotory is result of our work in the comepetiton organized by MoroccoAI in the context of the first MoroccoAI Data Challenge. For More Information, check the Kaggle Competetion page !
Automatic Number Plate Recognition (ANPR) in Morocco Licensed Vehicles
In Morocco, the number of registered vehicles doubled between 2000 and 2019. In 2019, a few months before lockdowns due to the Coronavirus Pandemic, 8 road fatalities were recorded per 10 000 registered vehicles. This rate is extremely high when compared with other IRTAD countries. The National Road Safety Agency (NARSA) established the road safety strategy 2017-26 with the main target to reduce the number of road deaths by 50% between 2015 and 2026 [1]. Law enforcement, speed limit enforcement and traffic control are one of most efficient measures taken by the authorities to achieve modern road user safety. Automatic Number Plate Recognition (ANPR) is used by the police around the world for law and speed limit enforcement and traffic control purposes, including to check if a vehicle is registered or licensed. It is also used as a method of cataloguing the movements of traffic by highways agencies. ANPR uses optical character recognition (OCR) to read vehicles’ license plates from images. This is very challenging for many reasons including non-standardized license plate formats, complex image acquisition scenes, camera conditions, environmental conditions, indoor/outdoor or day/night shots, etc. This data-challenge addresses the problem of ANPR in Morocco licensed vehicles. Based on a small training dataset of 450 labeled car images, the participants have to provide models able to accurately recognize the plate numbers of Morocco licensed vehicles.
Table of Contents
Dataset
The dataset is 654 jpg pictures of the front or back of vehicles showing the license plate. They are of different sizes and are mostly cars. The plate license follows Moroccan standard.
For each plate corresponds a string (series of numbers and latin characters) labeled manually. The plate strings could contain a series of numbers and latin letters of different length. Because letters in Morocco license plate standard are Arabic letters, we will consider the following transliteration: a <=> أ, b <=> ب, j <=> ج (jamaa), d <=> د , h <=> ه , waw <=> و, w <=> w (newly licensed cars), p <=> ش (police), fx <=> ق س (auxiliary forces), far <=> ق م م (royal army forces), m <=>المغرب, m <=>M. For example:
- the string “123ب45” have to be converted to “12345b”,
- the string “123و4567” to “1234567waw”,
- the string “12و4567” to “1234567waw”,
- the string “1234567ww” to “1234567ww”, (remain the same)
- the string “1234567far” to “1234567ق م م”,
- the string “1234567m” to “1234567المغرب",
- etc.
We offer the plate strings of 450 images (training set). The remaining 204 unlabeled images will be the test set. The participants are asked to provide the plate strings in the test set.

Our Approach
Our approach was to use Object Detection to detect plate characters from images. We have chosen to build two models separately instead of using libraries directly like easyOCR or Tesseract due to its weaknesses in handling the variance in the shapes of Moroccan License plates. The first model was trained to detect the licence plate to be then cropped from the original image, which will be then passed into the second model that was trained to detect the characters.
-
Data acquisition and preparation
First we start by annotating the dataset on our own using a tool called LabelImg. Then we found that the dataset provided by MSDA Lab was publicly available and fits our approach, as they have prepared the annotation in the following form :
- A folder that contains the Original image and bounding boxes of plates with 2 format Pascal Voc Format and Yolo Darknet Format.
- And the other folder , contains only the licence plates and the characters bounding boxes with the same formats.
-
Library and Model Architecture
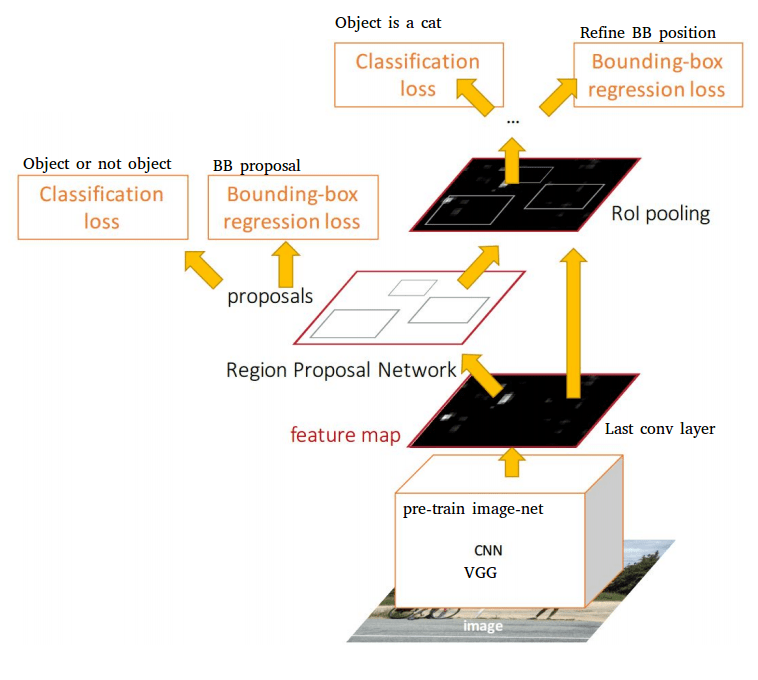
We have choose faster-rcnn model for both Object detection tasks, using library called detectron2 based on Pytorch and developed by FaceBook AI Research Laboratory (FAIR). A Faster R-CNN object detection network is composed of a feature extraction network which is typically a pretrained CNN, similar to what we had used for its predecessor. This is then followed by two subnetworks which are trainable. The first is a Region Proposal Network (RPN), which is, as its name suggests, used to generate object proposals and the second is used to predict the actual class of the object. So the primary differentiator for Faster R-CNN is the RPN which is inserted after the last convolutional layer. This is trained to produce region proposals directly without the need for any external mechanism like Selective Search. After this we use ROI pooling and an upstream classifier and bounding box regressor similar to Fast R-CNN.
-
Modeling
Training a first Faster-RCNN model only to detect licence plates.

And a second trained separately only to detect characters on cropped images of the licence plates.

The both models were pretrained on the COCO dataset, because we didn’t have enough data, therefor it would only make sense to take the advantage of transfer learning of models that were trained on such a rich dataset.
-
Post-Processing
Now we have a good model that can detect the majority of the characters in Licence Plates, the work is not done yet, because our model returns the boxes of detected characters, without taking the order in consideration. So we had to do a post-processing algorithm that can return the licence plate characters in the right order.- Split characters based on median of Y-Min of all detected characters boxes, by taking characters where their Y-Max is smaller than Median-Y-Mins into a string called top-characters, and those who have Y-Max greater than Median-Y-Mins will be in bottom_characters.
- Order characters in top and bottom list from left to right based on the X_Min of the detected Box of each character.


 4.6k Dec 30, 2022
4.6k Dec 30, 2022
 1 Nov 22, 2022
1 Nov 22, 2022
 3 Dec 29, 2022
3 Dec 29, 2022
 129 Jan 04, 2023
129 Jan 04, 2023
 131 Dec 31, 2022
131 Dec 31, 2022
 41 Dec 29, 2022
41 Dec 29, 2022
 5.3k Dec 28, 2022
5.3k Dec 28, 2022
 7 Oct 08, 2022
7 Oct 08, 2022
 11 Oct 29, 2022
11 Oct 29, 2022
 90 Dec 27, 2022
90 Dec 27, 2022
 170 Jan 03, 2023
170 Jan 03, 2023
 11 Oct 29, 2022
11 Oct 29, 2022
 5 Jul 13, 2022
5 Jul 13, 2022
 11 Dec 13, 2022
11 Dec 13, 2022
 7 Oct 27, 2022
7 Oct 27, 2022
 20 Oct 09, 2022
20 Oct 09, 2022
 1 Sep 01, 2022
1 Sep 01, 2022
 37 Dec 13, 2022
37 Dec 13, 2022
 6 Sep 11, 2022
6 Sep 11, 2022
 12 Dec 28, 2022
12 Dec 28, 2022