当前位置:网站首页>深度学习笔记 —— 物体检测和数据集 + 锚框
深度学习笔记 —— 物体检测和数据集 + 锚框
2022-04-23 04:53:00 【Whisper_yl】
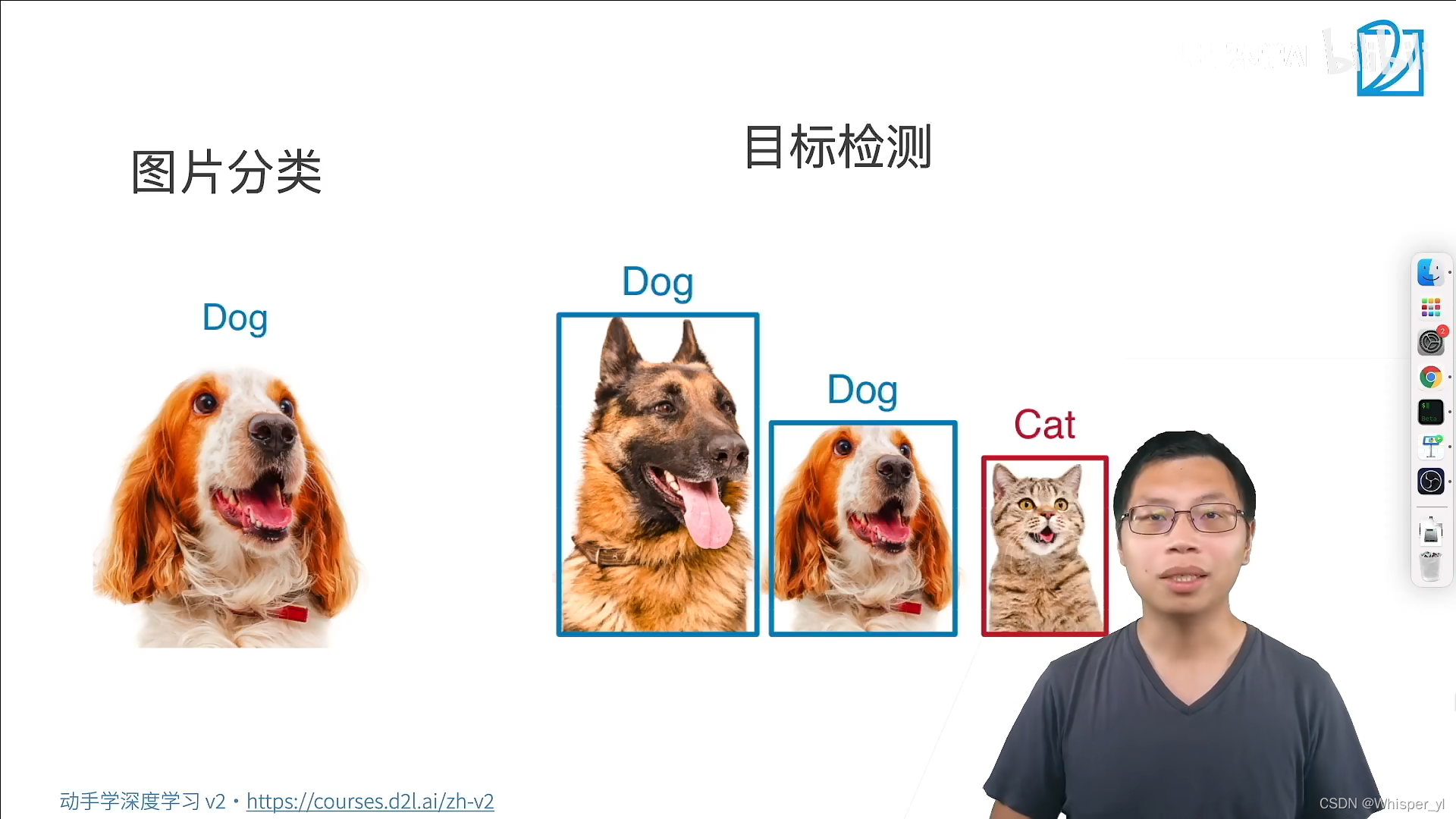
任务:识别我们所有感兴趣的物体,同时将每个物体的位置找出来



import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
d2l.set_figsize()
img = d2l.plt.imread('./img/catdog.jpg')
d2l.plt.imshow(img)
plt.show()
# 定义在这两种表示之间进行转换的函数
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox, cat_bbox))
print(box_center_to_corner(box_corner_to_center(boxes)) == boxes)
# 将边界框在图中画出
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))
plt.show()import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
import matplotlib.pyplot as plt
# 下载数据集
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
# 读取香蕉检测数据集
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
# read_image把图片读到内存里面
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
# 创建一个自定义Dataset实例
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
# __init__把所有的数据读进来
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
# 读取第idx个样本
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
# 返回数据集的长度
def __len__(self):
return len(self.features)
# 为训练集和测试集返回两个数据加载器实例
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
# 读取一个小批量,并打印其中的图像和标签的形状
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
print(batch[0].shape, batch[1].shape)
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
plt.show()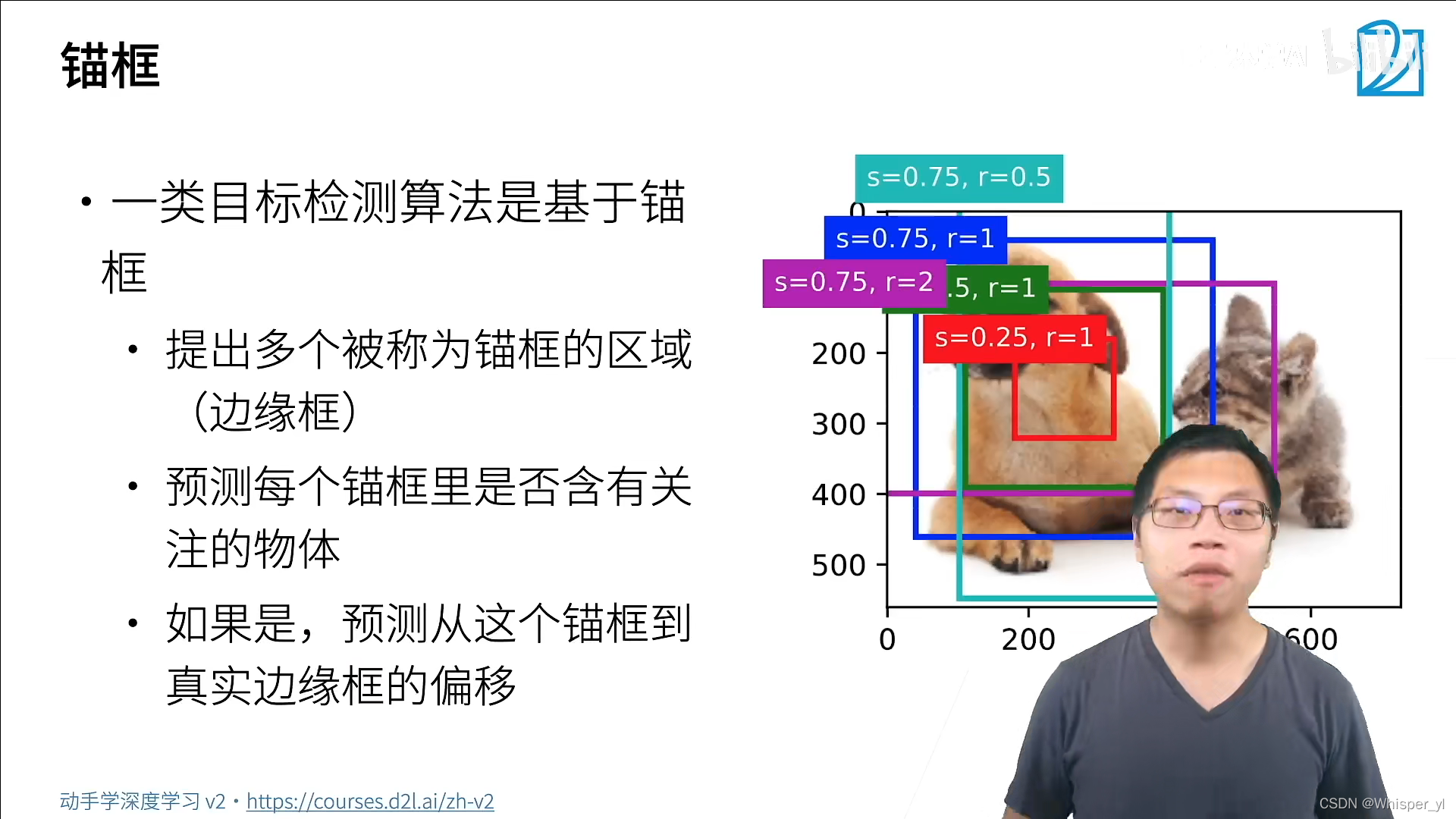
Bounding box(边缘框):一般是指真实位置。
锚框:算法对边框位置的猜测。
如果一个锚框中含有我们要关注的物体,接下来会基于这个锚框预测到真实边缘框是怎样移过去的。所以进行了两次预测:预测物体的类别和物体的位置。
还有一类算法是不需要生成锚框,直接去预测。


负类样本:只有背景的框。
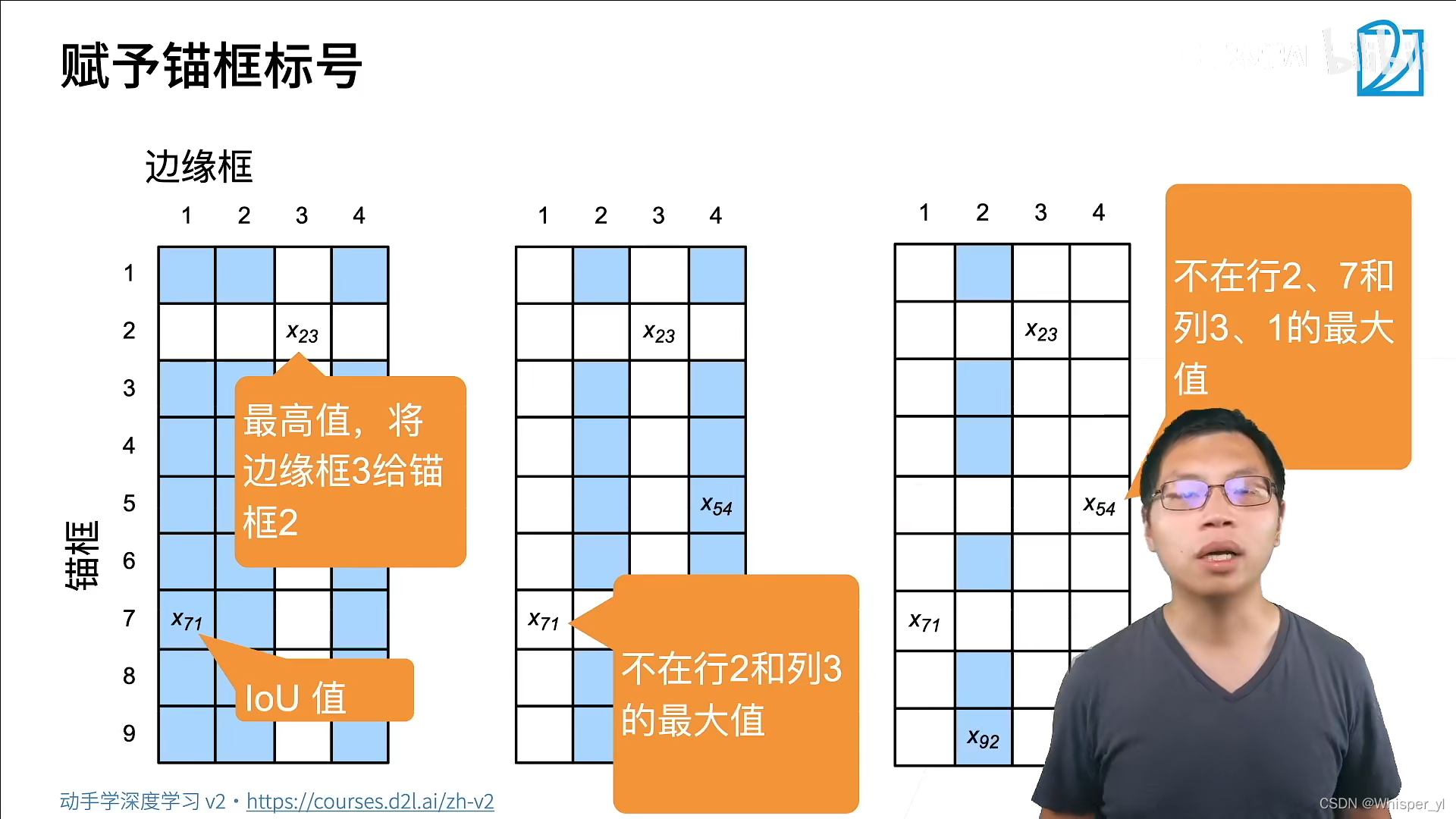 依次找矩阵中的最大值,将锚框与边框元关联起来,当所有的边缘框都分配完之后,剩下的锚框可以看一下跟哪个边框的IoU值比较大,就分配给它。
依次找矩阵中的最大值,将锚框与边框元关联起来,当所有的边缘框都分配完之后,剩下的锚框可以看一下跟哪个边框的IoU值比较大,就分配给它。

对类预测的值(softmax值)

第二步中大于θ?小于θ的一般是其他类的锚框。

import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
torch.set_printoptions(2) # 精简输出精度
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:]))) \
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
img = d2l.plt.imread('./img/catdog.jpg')
h, w = img.shape[:2]
# 返回的锚框变量Y的形状
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
print(Y.shape)
# 访问以(250, 250)为中心的第一个锚框
boxes = Y.reshape(h, w, 5, 4)
print(boxes[250, 250, 0, :])
# 显示以图像中一个像素为中心的所有锚框
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
# 以(250, 250)为中心的所有锚框
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])
plt.show()
# 交并比(IoU)
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
# 将真实边界框分配给锚框
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = box_iou(anchors, ground_truth)
# 对于每个锚框,分配的真实边界框的张量
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# 根据阈值,决定是否分配真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= 0.5).reshape(-1)
box_j = indices[max_ious >= 0.5]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
# 标记类和偏移
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
# 将类标签和分配的边界框坐标初始化为零
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# 使用真实边界框来标记锚框的类别。
# 如果一个锚框没有被分配,我们标记其为背景(值为零)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# 偏移量转换
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
# 在图像中绘制这些ground truth边界框和锚框
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])
plt.show()
# 根据狗和猫的真实边界框,标注这些锚框的分类和偏移量
labels = multibox_target(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))
print(labels[2])
print(labels[1])
print(labels[0])
# 应用逆偏移变换来返回预测的边界框坐标
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox
# 按降序对置信度进行排序并返回其索引
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
# 将非极大值抑制应用于预测边界框
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
# 将上述算法应用到一个带有四个锚框的具体示例中
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
# 在图像上绘制这些预测边界框和置信度
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
print(output)
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
plt.show()版权声明
本文为[Whisper_yl]所创,转载请带上原文链接,感谢
https://blog.csdn.net/LightInDarkness/article/details/124260745
边栏推荐
- leetcode001--返回和为target的数组元素的下标
- [WinUI3]编写一个仿Explorer文件管理器
- [WinUI3]編寫一個仿Explorer文件管理器
- List remove an element
- Unity攝像頭跟隨鼠標旋轉
- 【数据库】MySQL基本操作(基操~)
- MySQL -- execution process and principle of a statement
- New terminal play method: script guidance independent of technology stack
- La caméra Unity tourne avec la souris
- [winui3] Écrivez une copie du gestionnaire de fichiers Explorer
猜你喜欢
![Luogu p1858 [multi person knapsack] (knapsack seeking the top k optimal solution)](/img/2e/3313e563ac4f54057e359941a45098.png)
Luogu p1858 [multi person knapsack] (knapsack seeking the top k optimal solution)
Installation and deployment of Flink and wordcount test

Teach you how to build the ruoyi system by Tencent cloud
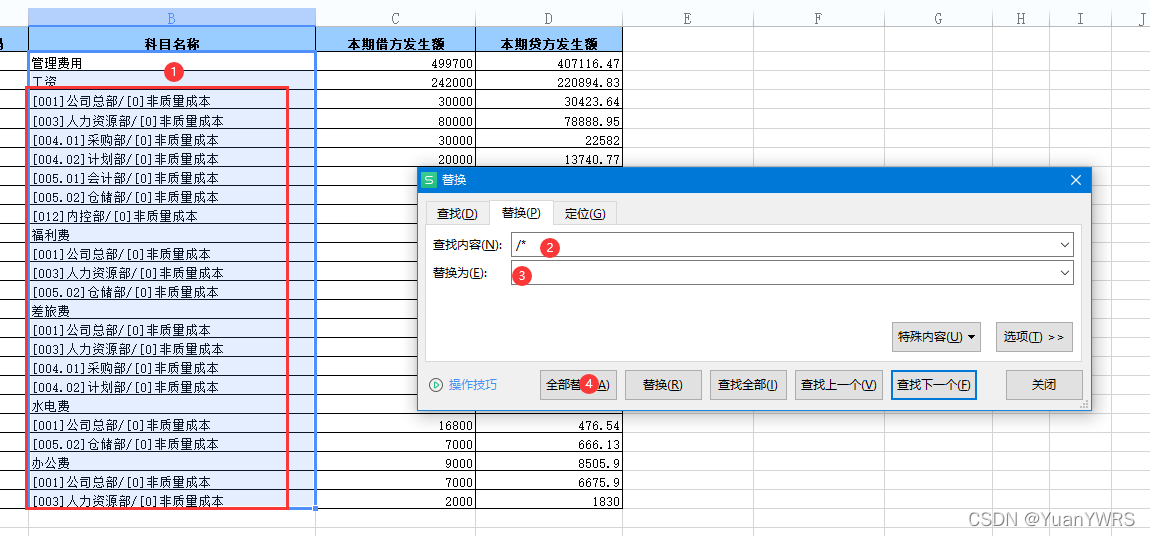
Excel uses the functions of replacement, sorting and filling to comprehensively sort out financial data

Flink's important basics
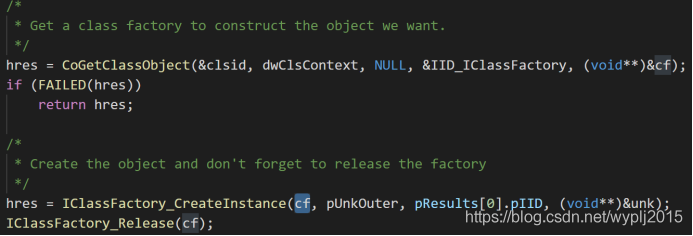
COM in wine (2) -- basic code analysis
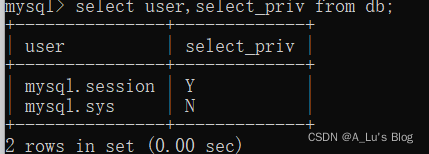
【数据库】MySQL基本操作(基操~)

Record the ThreadPoolExecutor main thread waiting for sub threads

Innovation training (VI) routing

Download PDF from HowNet (I don't want to use CAJViewer anymore!!!)
随机推荐
No such file or directory problem while executing shell
Eight misunderstandings that should be avoided in data visualization
C# List字段排序含有数字和字符
Spark small case - RDD, broadcast
The object needs to add additional attributes. There is no need to add attributes in the entity. The required information is returned
Luogu p1858 [multi person knapsack] (knapsack seeking the top k optimal solution)
Innovation training (VII) FBV view & CBV view
Code007 -- determine whether the string in parentheses matches
敏捷实践 | 提高小组可预测性的敏捷指标
独立站运营 | FaceBook营销神器——聊天机器人ManyChat
Pixel 5 5g unlocking tutorial (including unlocking BL, installing edxposed and root)
[database] MySQL single table query
PIP3 installation requests Library - the most complete pit sorting
POI export message list (including pictures)
Druid -- JDBC tool class case
简单的拖拽物体到物品栏
Innovation training (10)
[WinUI3]编写一个仿Explorer文件管理器
Simply drag objects to the item bar
Painless upgrade of pixel series