当前位置:网站首页>论文解读TransFG: A Transformer Architecture for Fine-grained Recognition
论文解读TransFG: A Transformer Architecture for Fine-grained Recognition
2022-08-11 05:25:00 【pontoon】
此篇文章是transformer在细粒度领域的应用。
问题:Transformer还未应用在图像细分类领域中
贡献点:1.vision transformer的输入把图像切分成patch,但是是没有overlap的,文章改成切分patch用overlap(这只能算个trick)
2.Part Selection Module
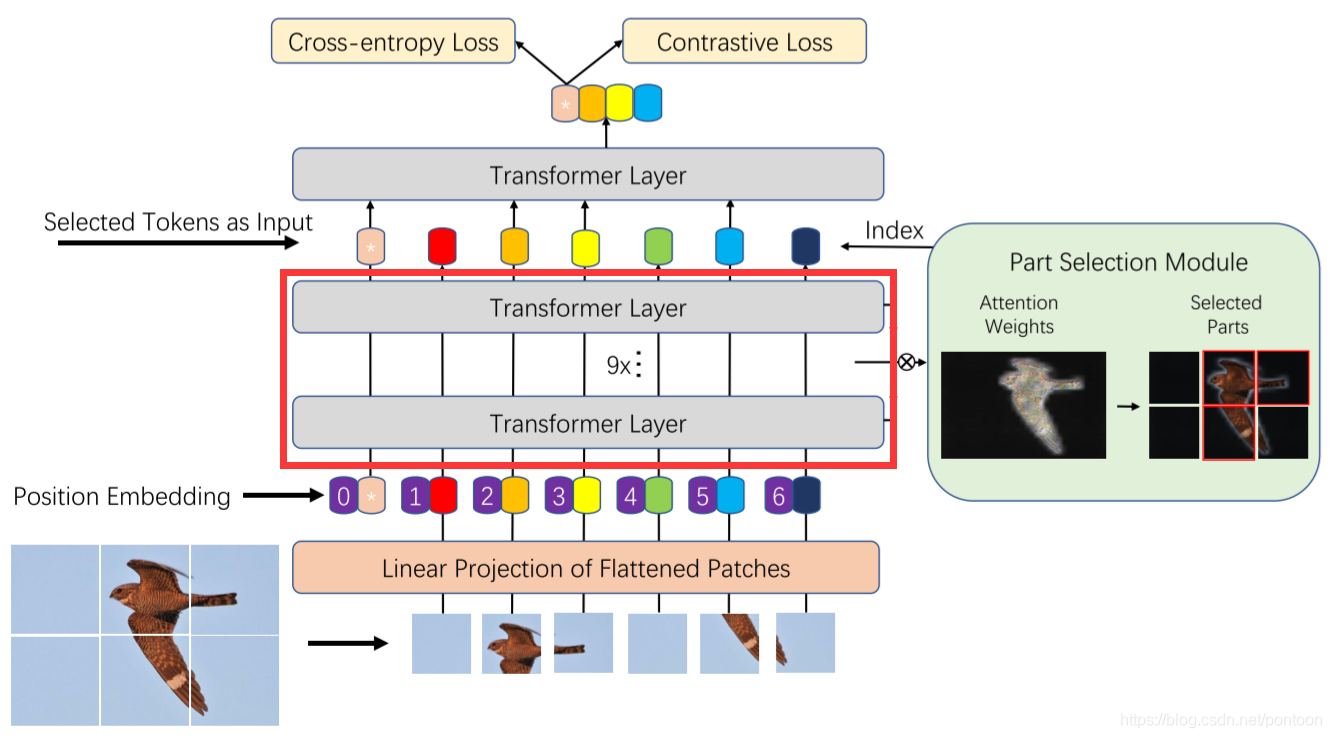
通俗讲就是最后一层的输入与vision transformer不同,即把最后一层前的所有层(红框所示)的权重累乘,再筛选出权重大的token拼接起来作为第L层的输入。
首先第L-1层的输出原本是这样的:
![]()
前面某层的权重如下:
![]()
其中下标l的取值范围为(1,2,...,L-1)
假设有K个self-attention head,那么每个head中的权重为:
![]()
其中上标i的取值范围为(0,1,...,K)
则对最后一层前面的所有层累乘权重:
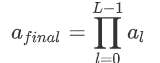
然后选择权重最大的A_k个token作为最后一层的输入。
所以经过处理后,其输入可表示为:
![]()
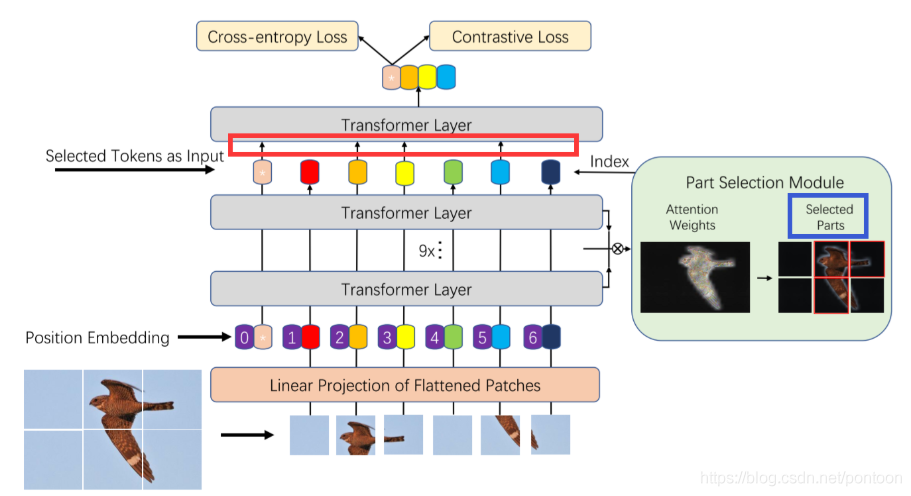
从模型架构上看,可以发现红框内带有箭头的token是被选中了的,也是经权重累乘后权值大的token,右侧蓝色框代表选中的token对应的patch。
3.Contrastive loss
作者说细粒度领域不同类别之间的特征很相似,因此单纯用交叉熵损失来学习特征是不够的,在交叉熵损失后加了新的Contrastive loss,这个损失里引入了余弦相似度(用来估计两个向量的相似情况),向量越相似余弦相似度越大。
作者提出此loss function的目的是缩小不同类别“分类token”的相似程度,最大化相同“分类token”的相似程度,通俗说就是不同类的尽量不相似,同类的尽量相似。Contrastive loss其公式如下:
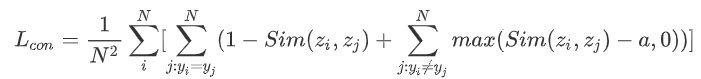
其中a是人为设定的常量。
所以总体函数为:
![]()
实验:
在细分类的几个数据集上与CNN和ViT进行比较,为SOTA
边栏推荐
猜你喜欢




随机推荐
解决jupyter中import torch出错问题
推出 Space Marketplace 测试版 | 新发布
Hardhat Recognition System - Solving Regulatory Conundrums
openlayer中实现截图框截图的功能
华为IOT平台温度过高时自动关闭设备场景试用
Introduction of safety helmet wearing recognition system
10 个超好用的 DataGrip 快捷键,快加入收藏! | 实用技巧
自定义形状seekbar学习--方向盘view
promise.all 学习(多个promise对象回调)
Kotlin 增量编译的新方式 | 技术解析
STM32-库函数-SetSysClock(void)函数解析-正点原子探索者
网络七层结构(讲人话)
CMT2380F32模块开发11-RTC例程
弱监督语义分割CLIMS(CVPR2022)
我心仪的数据集—目标检测为主
梅科尔工作室-PR第三次培训笔记(效果与转场及插件使用)
mAPH - Waymo dataset
The selection points you need to know about the helmet identification system
SearchGuard证书配置
端口的作用