当前位置:网站首页>Dancenn: overview of byte self-developed 100 billion scale file metadata storage system
Dancenn: overview of byte self-developed 100 billion scale file metadata storage system
2022-04-23 16:39:00 【Byte beat technical team】
Focus on Dry goods don't get lost
Background introduction
In a typical distributed file system , Catalog file metadata operation ( Including creating directories or files , rename , Modify permissions, etc ) It accounts for a large proportion of the entire file system operation , Therefore, metadata service plays an important role in the whole file system , With large-scale machine learning 、 Applications such as big data analysis and enterprise level data lake , The data scale of distributed file system has changed from PB Class to EB level , Most current distributed file systems ( Such as HDFS etc. ) Facing the challenge of metadata scalability .
With Google、Facebook and Microsoft And other companies have basically realized the ability to manage EB Level data scale distributed file system , The common architectural feature of these systems is that they rely on the ability of the underlying distributed database to realize the horizontal expansion of metadata performance , Such as Google Colossus be based on BigTable,Facebook be based on ZippyDB,Microsoft ADLSv2 be based on Table Storage, There are also some open source file systems, including CephFS and HopsFS And so on have basically realized the ability of horizontal expansion .
These file system implementations depend on the underlying distributed database , The degree of semantic support for file systems also varies , For example, most computing and analysis frameworks based on distributed file system rely on the underlying directory atom Rename Operation to provide atomic updates of data , and Tectonic and Colossus Because the underlying database does not support cross partition transactions, cross directory transactions are not guaranteed Rename The atomicity of , and ADLSv2 Support the atomic of any directory Rename.
DanceNN It is a directory tree meta information storage system developed by the company , Committed to solving the directory tree requirements of all distributed storage systems ( Including but not limited to HDFS,NAS etc. ), Greatly simplify the complexity of directory tree operation that the upper storage system depends on , Including but not limited to atoms Rename、 Recursive deletion, etc . Solve the scalability in the scenario of large-scale directory tree storage 、 performance 、 Problems such as global unified namespace between heterogeneous systems , Create the world's leading general distributed directory tree service .
At present DanceNN Has been online for the company ByteNAS, offline HDFS The two distributed file systems provide directory tree metadata services .
( This article mainly introduces the offline big data scenario HDFS Under the file system DanceNN Application , Consider space ,DanceNN stay ByteNAS The application of will be introduced in a subsequent series of articles , Coming soon )
Metadata evolution
byte HDFS The metadata system evolves in three stages :

NameNode
At first, the company used HDFS Native NameNode, Although a lot of optimization has been carried out , We still face the following problems :
Metadata ( Including the directory tree , Document and Block Copy, etc ) Full memory storage , The bearing capacity of a single machine is limited
be based on Java Language implementation , In large memory scenarios GC The pause time is relatively long , serious influence SLA
Use a global read-write lock , Poor read / write throughput
As the size of cluster data increases , The restart recovery time reaches the hour level
DanceNN v1
DanceNN v1 The design goal of is to solve the above NameNode Problems encountered .
The main design points include :
Re actualize HDFS Protocol layer , Store the metadata related to the directory tree file in RocksDB Storage engine , Provide 10 Multiple metadata bearer
Use C++ Realization , avoid GC problem , At the same time, use efficient data structure to organize memory Block Information , Reduce memory usage
Implement a fine-grained directory locking mechanism , Greatly improve the concurrency between different directory file operations
Request path is fully asynchronous , Support request priority processing
Focus on optimizing the block reporting and restarting the loading process , Reduce unavailable time
DanceNNv1 In the end in 2019 Complete the full volume launch in , The online effect basically achieves the design goal .
The following is a cluster with more than one billion files , Performance comparison after switching :

DanceNN v1 There are many technical challenges in development , For example, in order to ensure that the online process has no perception of the business , Support a variety of existing HDFS Client access , The back end needs to be fully compatible with the original Hadoop HDFS agreement .
Distributed DanceNN
all the time HDFS Is to use Federation Way to manage the directory tree , Set global Namespace Press path Mapping to multiple sets of metadata independent DanceNN v1 colony , Single group DanceNN v1 The cluster has a single machine bottleneck , Limited throughput and capacity , With the growth of the company's business data , Single group DanceNN v1 The cluster has reached its performance limit , You need to migrate data frequently between two clusters , In order to ensure data consistency, the upper layer business needs to stop writing during the migration process , It has a great impact on the business , And when the amount of data is large, the migration is relatively slow , These problems bring great operation and maintenance pressure to the whole system , Reduce the stability of the service .
Distributed The main design objectives of the version :
General directory tree service , Support multiple protocols, including HDFS,POSIX etc.
Single global Namespace
Capacity 、 Throughput supports horizontal expansion
High availability , The recovery time is within seconds
Including cross Directory Rename Wait for write operations to support transactions
High performance , be based on C++ Realization , rely on Brpc And other high-performance frameworks
Distributed DanceNN At present, it has HDFS The cluster goes online , Smooth migration of stock clusters is in progress .
File System Overview
Layered architecture
newest HDFS The implementation of distributed file system adopts hierarchical architecture , It mainly includes three layers :
The data layer : Used to store file contents , Handle Block Grade IO request
from DataNode Nodes provide services
Namespace layer : Responsible for the metadata related to the directory tree , Handle directory and file creation 、 Delete 、Rename And authentication
from Distributed DanceNN Clusters provide services
File block layer : Responsible for metadata related to documents 、 File with the Block Mapping and Block Copy location information , Process file creation and deletion , file Block Add requests for
One BSGroup Responsible for managing the metadata of some file blocks in the cluster , By multiple DanceBS Composition provides highly available services
adopt BSGroup Dynamic capacity expansion to adapt to cluster load , When a BSGroup When the performance limit is reached, the write can be controlled
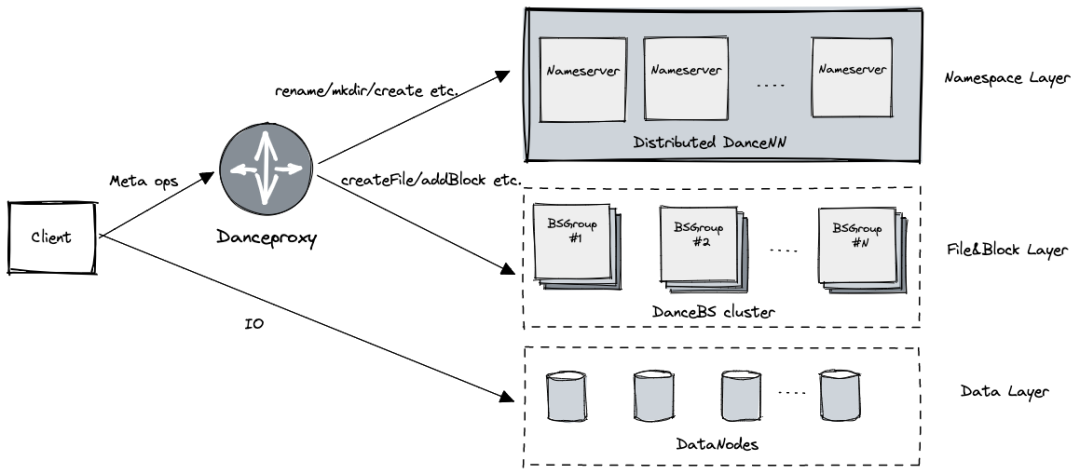
DanceProxy
C++ Realization , Based on high performance framework Brpc Realized Hadoop RPC agreement , Support high throughput , Seamless docking with existing HDFS Client.
Mainly responsible for HDFS Client Parsing of requests , After splitting , take Namespace Relevant requests are sent to DanceNN colony , Requests related to file blocks are routed to the corresponding BSGroup Handle , When all back-end requests reply, the response of the final client is generated .
DanceProxy Through a certain request routing strategy to achieve multiple groups BSGroup Load balancing .
DanceNN Interface
Distributed DanceNN The main interfaces provided for the file system are as follows :
class DanceNNClient {
public:
DanceNNClient() = default;
virtual ~DanceNNClient() = default;
// ...
// Create directories recursively, eg: MkDir /home/tiger.
ErrorCode MkDir(const MkDirReq& req);
// Delete a directory, eg: RmDir /home/tiger.
ErrorCode RmDir(const RmDirReq& req);
// Change the name or location of a file or directory,
// eg: Rename /tmp/foobar.txt /home/tiger/foobar.txt.
ErrorCode Rename(const RenameReq& req);
// Create a file, eg: Create /tmp/foobar.txt.
ErrorCode Create(const CreateReq& req, CreateRsp* rsp);
// Delete a file, eg: Unlink /tmp/foobar.txt.
ErrorCode Unlink(const UnlinkReq& req, UnlinkRsp* rsp);
// Summarize a file or directory, eg: Du /home/tiger.
ErrorCode Du(const DuReq& req, DuRsp* rsp);
// Get status of a file or directory, eg: Stat /home/tiger/foobar.txt.
ErrorCode Stat(const StatReq& req, StatRsp* rsp);
// List directory contents, eg: Ls /home/tiger.
ErrorCode Ls(const LsReq& req, LsRsp* rsp);
// Create a symbolic link named link_path which contains the string target.
// eg: Symlink /home/foo.txt /home/bar.txt
ErrorCode Symlink(const SymlinkReq& req);
// Read value of a symbolic link.
ErrorCode ReadLink(const ReadLinkReq& req, ReadLinkRsp* rsp);
// Change permissions of a file or directory.
ErrorCode ChMod(const ChModReq& req);
// Change ownership of a file or directory.
ErrorCode ChOwn(const ChOwnReq& req);
// Change file last access and modification times.
ErrorCode UTimeNs(const UTimeNsReq& req, UTimeNsRsp* rsp);
// Set an extended attribute value.
ErrorCode SetXAttr(const SetXAttrReq& req, SetXAttrRsp* rsp);
// List extended attribute names.
ErrorCode GetXAttrs(const GetXAttrsReq& req, GetXAttrsRsp* rsp);
// remove an extended attribute.
ErrorCode RemoveXAttr(const RemoveXAttrReq& req,
RemoveXAttrRsp* rsp);
// ...
};DanceNN framework
Function is introduced
Distributed DanceNN Based on the underlying distributed transaction KV Store to build , Achieve capacity and throughput level expansion , The main function :
HDFS Efficient implementation of protocol layer
Service statelessness , Support high availability
Rapid expansion and contraction of service nodes
Provide high performance and low latency access
Yes Namespace Divide the subtree , Make full use of subtree Cache Locality
The cluster schedules the subtrees according to the load balancing policy
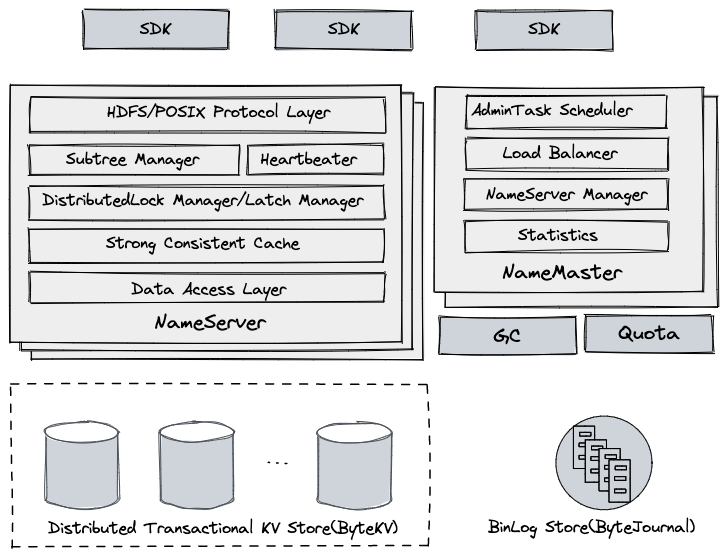
Module partition
SDK
Cache cluster subtree 、NameServer Location, etc , Parse the user request and route it to the back-end service node , If the service node's response to the request is illegal , May force SDK Refresh the corresponding cluster cache .
NameServer
As a service node , No state , Support horizontal scaling
HDFS/POSIX Protocol Layer: Handle client requests , Realized HDFS And other protocol layer semantics , Including path resolution , Permission to check , Delete, enter the recycle bin, etc
Subtree Manager: Manage the subtree assigned to the current node , Responsible for user request inspection , Subtree migration processing, etc
Heartbeater: After the process starts, it will automatically register with the cluster , Regularly send to NameMaster Update heartbeat and load information
DistributedLock Manager: be based on LockTable, For cross Directory Rename Request concurrency control
Latch Manager: Lock all path read-write requests , Reduce underlying transaction conflicts , Support Cache Concurrent access to
Strong Consistent Cache: Maintains the current node subtree dentry and inode Strong consistency Cache
Data Acess Layer: To the underlying KV The abstraction of the stored access interface , The read and write operations of the upper layer will be mapped to the lower layer KV Storage request
NameMaster
As a management node , No state , More than one , By selecting the master , The service is provided by the master node
AdminTask Scheduler: Background management related task scheduling and execution , Including subtree segmentation , Expansion, etc
Load Balancer: According to the cluster NameServer Load status , Load balancing through automatic subtree migration
NameServer Manager: monitor NameServer A healthy state , Perform corresponding downtime processing
Statistics: Through the consumption cluster change log , Collect statistics in real time and display
Distributed Transactional KV Store
Data storage layer , Use self-developed strong consistency KV The storage system ByteKV
Provide horizontal scalability
Support distributed transactions , Provide Snapshot Isolation level
Support multi machine room data disaster recovery
BinLog Store
BinLog Storage , Use self-developed low latency distributed logging system ByteJournal, Support Exactly Once semantics
From the bottom KV Extract the data change log in real time from the storage system , It is mainly used for PITR And real-time consumption of other components
GC(Garbage collector)
from BinLog Store Real time consumption change log , After reading the file and deleting the record , Issue a delete command to the file block service , Clean up user data in time
Quota
The directory claimed by the user , It will be full periodically 、 Real time incremental statistics of the total number of files and total space , Limit users to write after capacity overrun
Key design
Storage format
Generally, there are two schemes for metadata format based on distributed storage :
Scheme 1 is similar to Google Colossus, Take the full path as key, Metadata as value Storage , The advantages are :
Path resolution is very efficient , Directly requested by the user path From the bottom KV Store read correspondence inode The metadata of
The scan directory can be prefixed to KV Store for scanning
But it has the following disadvantages :
Cross directory Rename It's expensive , All files and directories in the directory need to be moved
Key The occupied space is relatively large
The other is similar to Facebook Tectonic Open source HopsFS, As parent directory inode id + Directory or file name as key, Metadata as value Storage , This advantage has :
Cross directory Rename Very light weight , Just modify the source and target nodes and their parent nodes
The scanning directory can also use the parent directory inode id Scan as a prefix
Disadvantages are :
Path resolution network latency is high , Need from Root Read the metadata of related nodes recursively until the target node
for example :
MkDir /tmp/foo/bar.txt, There are four dimensional metadata network access :/、/tmp、/tmp/fooand/tmp/foo/bar.txt
The smaller the level , The more obvious the access hotspot is , As a result, the underlying storage load is seriously unbalanced
for example : Read the root directory once for each request / Metadata
Consider cross Directory Rename Online clusters account for a high proportion of requests , And for large directories Rename The delay is uncontrollable ,DanceNN The second scheme is mainly adopted , The two disadvantages of scheme 2 are solved by the following subtree partition .
Subtree partition
DanceNN By putting the global Namespace Partition the subtree , The subtree is assigned a NameServer Instance maintenance subtree cache .
Subtree cache
Maintain a strong consistent cache of all directory and file metadata under this subtree
Cache items have certain elimination strategies, including LRU,TTL etc.
All request paths under this subtree can directly access the local cache , Misses need to be from the bottom KV Store to load and populate the cache
Specify the cache expiration date of all metadata in a directory by adding a version to the cache item , It is conducive to the rapid migration and cleaning of subtrees
Use subtree local cache , Path resolution and read requests can basically hit the cache , Reduce overall delay , It also avoids the hot issues of access close to the root node .
Path freeze
Migrate in subtree 、 Spanning subtree Rename And so on , In order to avoid requesting to read expired subtree cache , Relevant paths need to be frozen , During freezing, all operations under this path will be blocked , from SDK Responsible for retrying , The whole process is completed in sub second level
After the path is frozen, all cache entries in the directory will be set to expire
Frozen path information will be persisted to the bottom layer KV Storage , After restart, it will reload and refresh
Subtree management
Subtree management mainly consists of NameMaster be responsible for :
Support manual subtree splitting and subtree migration through administrator commands
Regularly monitor the load status of cluster nodes , Dynamically adjust the distribution of subtrees in clusters
Regularly count the access throughput of subtree , Provide subtree splitting suggestions , In the future, heuristic algorithms will be supported to select subtrees to complete splitting
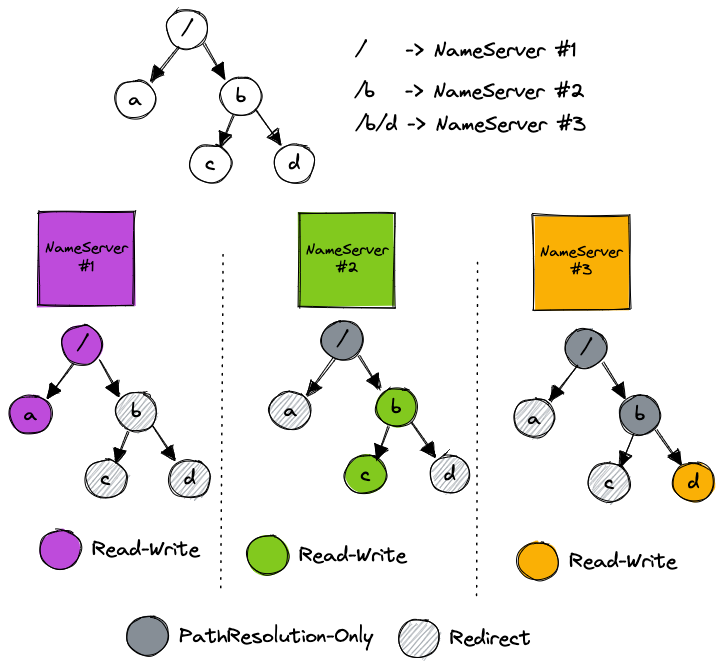
for instance , Here's the picture :
Catalog / Dispatch to NameServer #1, Catalog /b Dispatch to NameServer #2, Catalog /b/d Dispatch to NameServer #3
MkDir /aRequest to NameServer #1, Send to other NameServer Will fail to verify , Redirect error returned , Give Way SDK Refresh the cache and try againStat /b/dThe request will be sent to NameServer #3, Just read the local cache directlyChMod /bThe request will be sent to NameServer #2, to update b And persist the permission information of the directory , Yes NameServer #2 and NameServer #3 Conduct Cache Refresh , Finally, reply to the client
concurrency control
Bottom KV The storage system ByteKV Support for a single record Put、Delete and Get semantics , among Put Support CAS semantics , It also provides atomic writing interface for multiple records WriteBatch.
The client write operation usually involves the update of multiple files or directories , for example Create /tmp/foobar.txt Will update /tmp Of mtime Record 、 establish foobar.txt Records, etc. ,DanceNN The update of multiple records will be converted into ByteKV WriteBatch request , Ensure the atomicity of the whole operation .
Distributed lock management
although ByteKV To provide a transaction ACID Property and supports Snapshot Isolation level , However, for multiple concurrent write operations, if the underlying data changes are involved, there is no Overlap Words , There are still Write Skew abnormal , This may lead to the destruction of metadata integrity .
One example is concurrency Rename abnormal , Here's the picture :
Single Rename /a /b/d/e Operation or single Rename /b/d /a/c The operation is in line with expectations , But if both execute concurrently ( And can succeed ), Can cause Directory a,c,d,e There is a ring in the metadata of , It destroys the integrity of the directory tree structure .

We choose to use distributed locking mechanism to solve , Serial processing of concurrent requests that may cause exceptions , Based on the underlying KV Storage design Lock Table, Support locking metadata records , Provide durability 、 Horizontal expansion 、 Read-write lock 、 Lock timeout cleaning and idempotent functions .
Latch management
In order to support concurrent access and update of the internal cache of the subtree , Maintain strong consistency of cache , The cache items involved in the operation will be locked (Latch), for example :Create /home/tiger/foobar.txt, Will be right first tiger and foobar.txt Add and write the corresponding cache item Latch, Then update ;Stat /home/tiger Would be right tiger Cache item add read Latch, Read again .
In order to improve the overall performance of the service, many optimizations have been made , Here are two important optimizations :
Create and delete a large number of files in the hot Directory
for example : Some businesses are like large MapReduce The task will create thousands of directories or files in the same directory at once .
Generally speaking, creating a file or directory according to the semantics of the file system will update the metadata related to the parent directory ( Such as HDFS The protocol updates the of the parent directory mtime,POSIX Request to update parent directory mtime,nlink etc. ), This leads to serious transaction conflict between the operation of creating files in the same directory and the update of metadata of the parent directory , In addition, the bottom layer KV The storage system is a multi room deployment , The machine room delay is higher , Further reduce the concurrency of these operations .
DanceNN For operations such as creation and deletion under the hotspot directory, only add reading latch, Then put it in a ExecutionQueue in , By a light weight Bthread The coroutine performs background asynchronous serial processing , Combine these requests into a certain size Batch Sent to the underlying KV Storage , This avoids underlying transaction conflicts , Increase throughput by dozens of times .
Mutual blocking between requests
Some scenarios may cause the update request of the directory to block other requests under the directory , for example :
SetXAttr /home/tiger and Stat /home/tiger/foobar.txt Cannot execute concurrently , Because the first one is right tiger Cache entry write Latch, Later request to read tiger Metadata cache entries will be blocked .
DanceNN Use similar Read-Write-Commit Lock Realize to Latch Conduct management , Every Latch Yes Read、Write and Commit Three types of , among Read-Read、Read-Write Requests can be concurrent ,Write-Write、Any-Commit Request mutual exclusion .
Based on this implementation , The above two requests can be executed concurrently under the condition of ensuring data consistency .
Request idempotent
When the client fails due to timeout or network failure , Retrying will cause the same request to arrive Server many times . Some requests, such as Create perhaps Unlink Is a non idempotent request , For such operations , Need to be in Server End identification to ensure that it is processed only once .
In a stand-alone scenario , We usually use a memory Hash Table to handle retry requests ,Hash Tabular key by {ClientId, CallId},value by {State, Response}, When requested A After arrival , We'll insert {Inprocess State} To Hash surface ; After this , If you retry the request B arrival , Will directly block the request B, Wait for the second request A Wake up after successful execution B. When A After successful execution , We will {Finished State, Response} writes Hash Watch and wake up B,B You will see the updated Finished Respond to the client after status .
Allied DanceNN The write request will be at the bottom WriteBatch Add one to the request Request Record , This ensures that subsequent retry requests will have transactions at the bottom CAS Failure , After the upper layer finds it, it will read the Request Record the direct response client . in addition , When to delete Request What about the records , We will set a relatively long time for the record TTL, It can be ensured that the record is in TTL After that, it must have been processed .
Performance testing
Pressure test environment :
DanceNN Use 1 platform NameServer, Distributed KV The storage system uses 100+ Station data node , Three machine rooms and five copies are deployed (2 + 2 + 1), Cross machine room delay 2-3ms about , Client pass NNThroughputBenchmark The metadata pressure test script uses single thread and..., respectively 6K Thread concurrent pressure measurement .
Intercept partial delay and throughput data as follows :
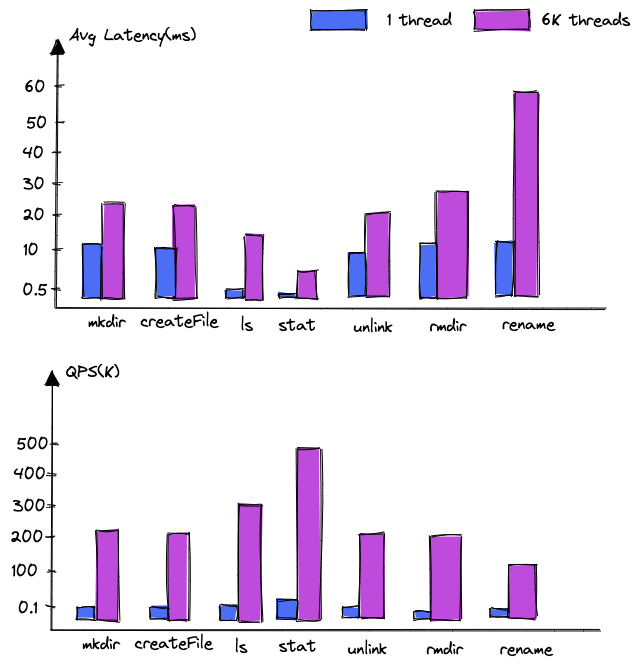
The test results show that :
Read throughput : A single NameServer Support read request 500K, With NameServer The throughput can increase linearly with the increase of the number ;
Write throughput : At present, it depends on the bottom KV Write transaction performance of storage , With the bottom KV The increase of node data can also achieve linear growth .
Join us
With the continuous development of byte beating , The availability of the business to the underlying distributed file system 、 The requirements of performance and scalability are also higher and higher , Welcome to distributed storage 、 File system and NFS/POSIX/HDFS Students interested in File protocol and other technologies join us , Based on cutting-edge technology in the industry ( Such as new storage media ) Build the next generation of large-scale distributed file system .
Contact email :[email protected]
Reference material
Colossus under the hood: a peek into Google’s scalable storage system
Facebook’s Tectonic Filesystem: Efficiency from Exascale
HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases
Azure Data Lake Storage Gen2
Ceph: A Scalable, High-Performance Distributed File System
LocoFS: A Loosely-Coupled Metadata Service for Distributed File Systems
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/Benchmarking.html#NNThroughputBenchmark
https://en.wikipedia.org/wiki/Snapshot_isolation
https://github.com/apache/incubator-brpc
Byte hopping self research strong consistent online KV & Table storage practices - Part 1
版权声明
本文为[Byte beat technical team]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231631516134.html
边栏推荐
- MySQL master-slave synchronization pit avoidance version tutorial
- MySql主从复制
- English | day15, 16 x sentence true research daily sentence (clause disconnection, modification)
- LVM and disk quota
- Using JSON server to create server requests locally
- Phpstudy V8, a commonly used software for station construction 1 graphic installation tutorial (Windows version) super detailed
- Best practice of cloud migration in education industry: Haiyun Jiexun uses hypermotion cloud migration products to implement progressive migration for a university in Beijing, with a success rate of 1
- Selenium IDE and XPath installation of chrome plug-in
- The solution of not displaying a whole line when the total value needs to be set to 0 in sail software
- 建站常用软件PhpStudy V8.1图文安装教程(Windows版)超详细
猜你喜欢

Research and Practice on business system migration of a government cloud project
Disk management and file system
磁盘管理与文件系统
第十天 异常机制

299. Number guessing game
Ali developed three sides, and the interviewer's set of combined punches made me confused on the spot
loggie 源码分析 source file 模块主干分析
Gartner publie une étude sur les nouvelles technologies: un aperçu du métacosme
Sail soft implements a radio button, which can uniformly set the selection status of other radio buttons
Creation of RAID disk array and RAID5
随机推荐
The first line and the last two lines are frozen when paging
05 Lua 控制结构
Nacos detailed explanation, something
Change the icon size of PLSQL toolbar
Dlib of face recognition framework
Database dbvisualizer Pro reported file error, resulting in data connection failure
MySql主从复制
Findstr is not an internal or external command workaround
How to choose the wireless gooseneck anchor microphone and handheld microphone scheme
Install MySQL on MAC
Phpstudy V8, a commonly used software for station construction 1 graphic installation tutorial (Windows version) super detailed
loggie 源码分析 source file 模块主干分析
About JMeter startup flash back
Report FCRA test question set and answers (11 wrong questions)
05 Lua control structure
英语 | Day15、16 x 句句真研每日一句(从句断开、修饰)
NVIDIA graphics card driver error
Use case labeling mechanism of robot framework
Questions about disaster recovery? Click here
深入了解3D模型相关知识(建模、材质贴图、UV、法线),置换贴图、凹凸贴图与法线贴图的区别