当前位置:网站首页>Three schemes of SQL query across the table
Three schemes of SQL query across the table
2022-08-10 18:45:00 【dry road】
前言
A friend of mine asked me recently,如何进行sqlcross-database association query? 首先呢,我们知道mysql是不支持跨库连接的,但是老话说得好,只要思想不滑坡,Ideas are always more difficult than difficult!
PS:The problem lies here,Still can not solve what is?
After some thought I came up with three options for him,Although not perfect,But each leads the pack!
My connection plan,以postgreSql库为例.
方案一:Link multiple libraries,Execute the query synchronously
The specific idea is to connect multiple libraries separately in the code,After finding the required data in a library,通过关键字段,Synchronous execution goes to other libraries to query related data,Then perform the required data analysis or update!
优点
- 可以进行实时查询;
- The data can be modified on demand and the return value can be modified within the logical range;
- This scheme is generally used,Query data will be paginated query,Or the query conditions are precise,So the amount will be smaller,对服务器压力小;
- Server static analysis data,效率高;
缺点
- Not suitable for bulk data writing/查询,It will cause the database connection to time out or the obtained data flow to be too large, resulting in a large amount of server memory usage;
- 同步执行策略,Querying the database takes time proportional to the runtime;
代码执行
Some simple code logic,No one will understand it~~~
postgreSql.js
//链接多个数据库,并暴露
const pg = require('pg');
const sqlConfig = {
testOnePgSql: {
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.111",//数据库ip地址(Randomly written,Write your own libraryip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
//Super island merchants
testTwoPgSql: {
//测试数据库
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.112",//数据库ip地址(Randomly written,Write your own libraryip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
//Myrtle Merchant
testThreePgSql: {
//测试数据库
user: "postgres",
database: "admindb",
password: "123",
host: "192.168.1.113",//数据库ip地址(Randomly written,Write your own libraryip哈)
port: 5432, // 扩展属性
max: 20, // 连接池最大连接数
idleTimeoutMillis: 3000
},
};
const testOnePgSql = new pg.Pool(sqlConfig.banuPgSql);
const testTwoPgSql = new pg.Pool(sqlConfig.testTwoPgSql);
const testThreePgSql = new pg.Pool(sqlConfig.testThreePgSql);
module.exports = {
testOnePgSql,
testTwoPgSql,
testThreePgSql
};
复制代码封装查询pgsql方法
postgreSqlClass.js
let sqlMap = require('./postgreSql');
module.exports = {
/** *查询pgsql数据 * @param sqlSelect 查询语句 string * @param tenancy 商户id string */
select(sqlSelect, tenancy) {
//按需连接
let pool = sqlMap[tenancy];
return new Promise((resolve, reject) => {
pool.connect(async function (err, connection) {
if (err) {
// 结束会话
connection.release();
return reject(err);
}
let result = await pgQuery(sqlSelect, connection);
// 结束会话
connection.release();
return resolve(result);
});
});
}
};
/** * pgsql查询数据 * @param sqlQuery 查询语句 * @param connection pgSql连接后的connection * @returns {Promise<unknown>} */
async function pgQuery(sqlQuery, connection) {
return new Promise((resolve, reject) => {
connection.query(sqlQuery, (err, rows) => {
if (err) return reject(err);
return resolve(rows.rows || []);
});
});
}
复制代码Now proceed to the business module
test.js
"use strict";
//引入pg函数
let PGSQL = require("./postgreSqlClass");
exports.getUserList = async () => {
let sqlOneSelect = `${The first table query statement}`;
let userList = await PGSQL.select(sqlSelect, "testOnePgSql");
//获取对应two表的数据
//...逻辑
let sqlTwoSelect = `${The first table query statement}`;
let userListTwo = await PGSQL.select(sqlTwoSelect, "testTwoPgSql");
let result = [];
//Combine the data you want
//...逻辑
return result;
};
复制代码方案二:Add redundant tables in the main database,通过定时更新,Causes the query of the same database linked table
比如AThe library is the main database,B、CFor other add-on libraries,We need to combine the three librariesuserThe table performs data join table query; 具体思路为:
- 在A库存在user表,Redundant tables are created at this pointuser_two、user_three表,and corresponding fieldsB、C库的user表字段;
- 通过代码逻辑,进行定时任务,将B、C表,数据更新至A库user_two、user_three表;
- Data analysis is required/查询时,仅查询A库即可,但需要将A库的user、user_two、user_threeTables are available on demand;
优点
- Convert cross-table queries to same-table queries,The execution logic is simpler;
- It can perform big data analysis and big data query;
- Data can be preprocessed,Improve analysis speed;
缺点
- 定时更新,Not timely;
- The corresponding table needs to have the last update time field,Otherwise, there will be more synchronization data;
- 增加冗余表,It will cause the main table space occupancy rate to increase;
- 定时更新,It will cause a large amount of data to be written at a certain point in time/修改数据,Data reading may be affected,因此,Multi-node deployment is recommended(读写、只读);
Similar implementation scenarios
- T+1Time report display;
- The local area network database information is reported to the online database;
方案三:(极度不建议)dbLinkLink multiple libraries natively,Perform data analysis locally
具体思路:
- dblink就是我们在创建表的时候连接到我们的远程库,Then the data of the newly created table locally is the data of the mapped remote table.
- 当我们创建一个以FEDERATED为存储引擎的表时,服务器在数据库目录只创建一个表定义文件.文件由表的名字开始,并有一个frm扩展名.无其它文件被创建,因为实际的数据在一个远程数据库上.这不同于为本地表工作的存储引擎的方式.
执行步骤:
- 1.如我现在本地要连接我的阿里云的sys_user表,So I need to build a table with the same fields locally,我取名叫sys_user_copy,并连接到远程库,建好后,我本地sys_user_copy的表里面的数据是映射远程的表的数据
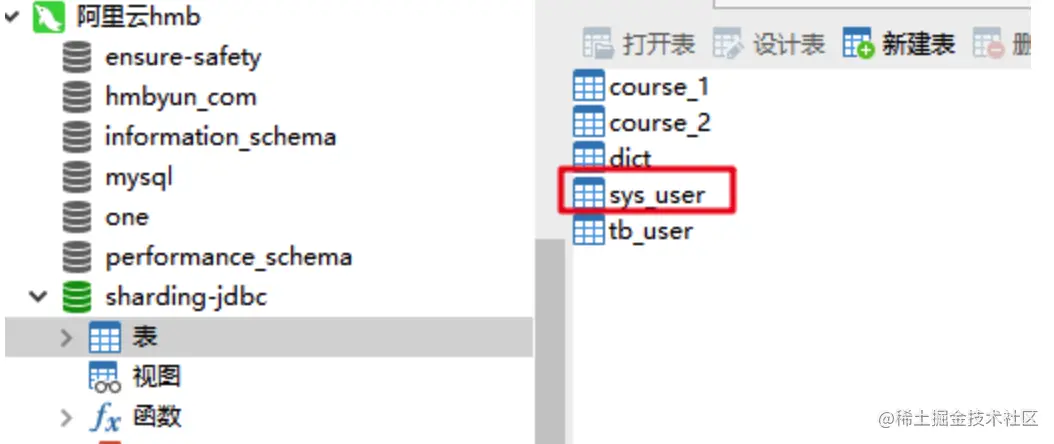

- 2.所以我关联查询,可以直接关联我本地sys_user_copy表从而查出来.改了本地的数据,远程的表数据也会跟着变
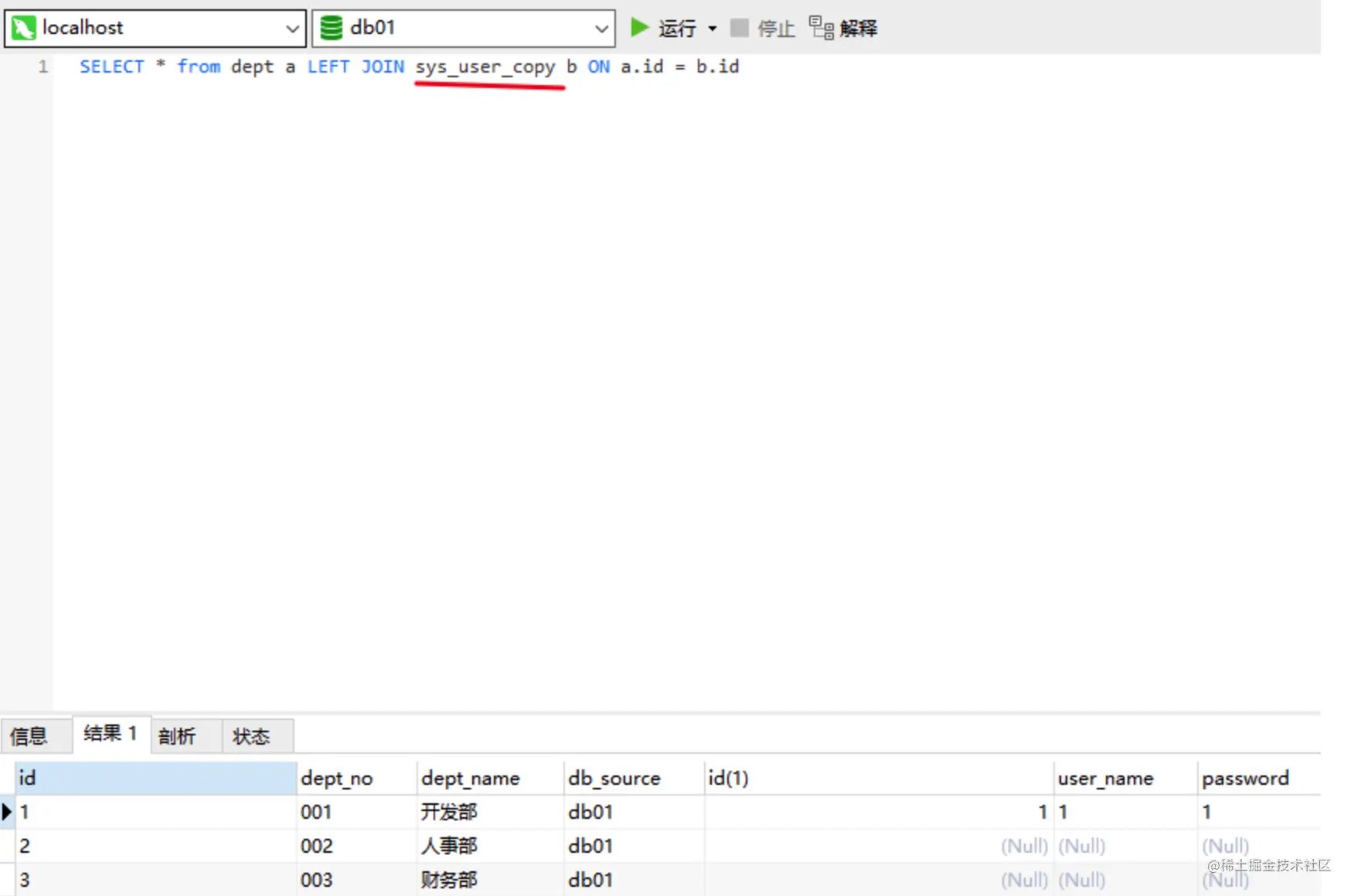

- **开启FEDERATED引擎,**show engines
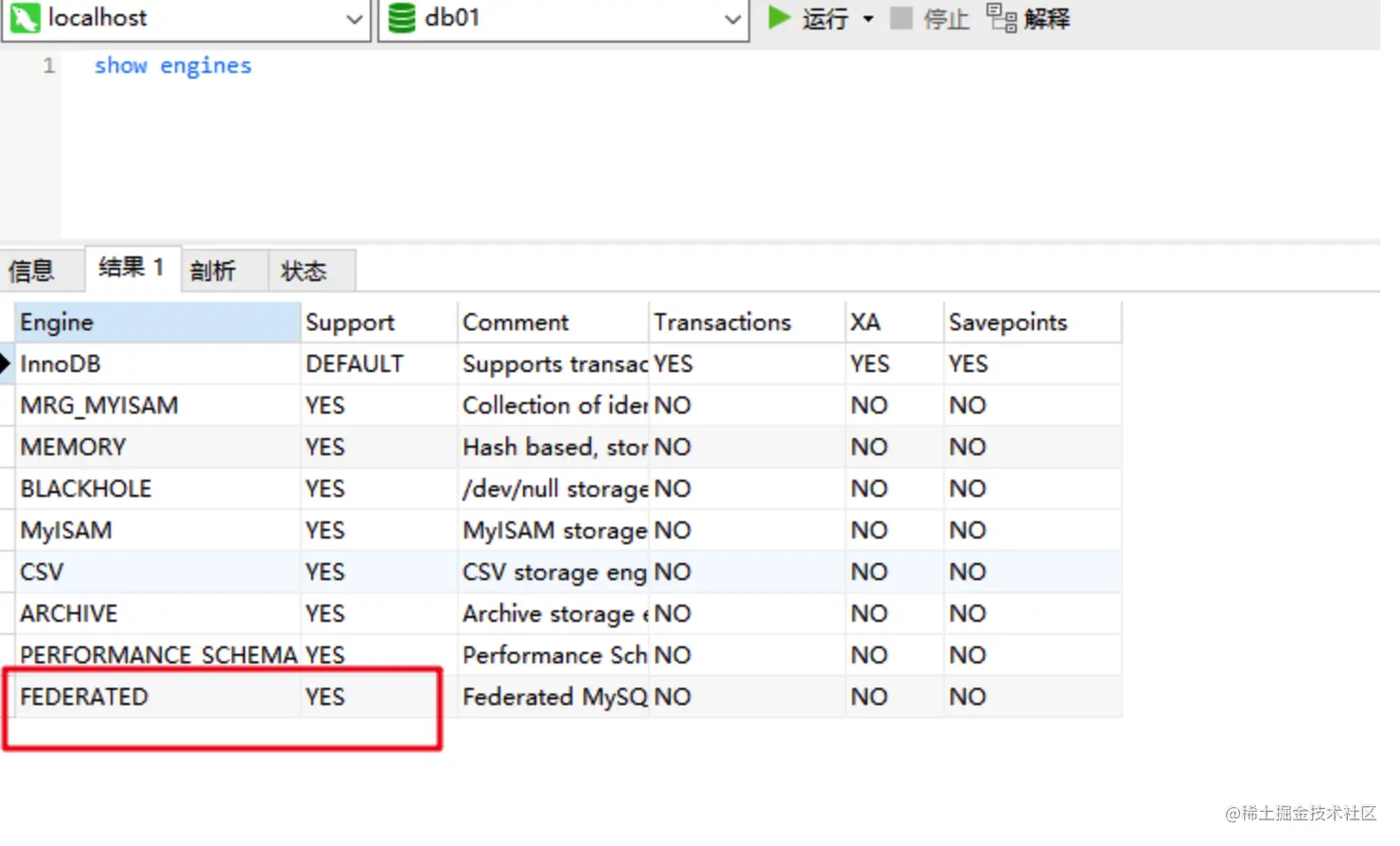
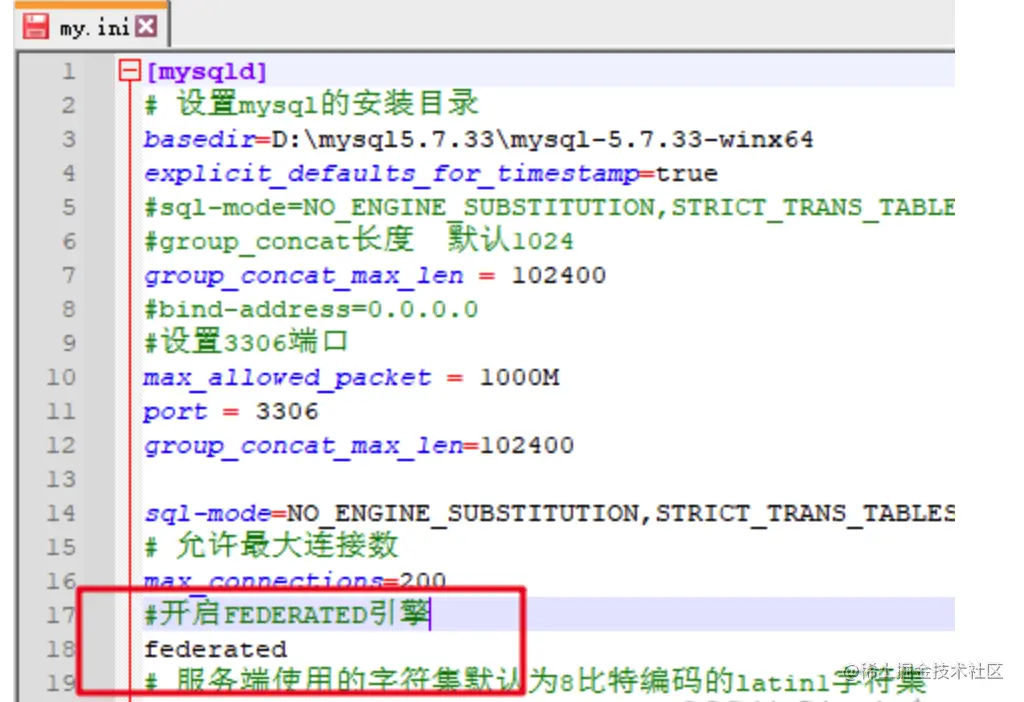
改完重启服务,就变成yes了.
- 4 建表时加上连接
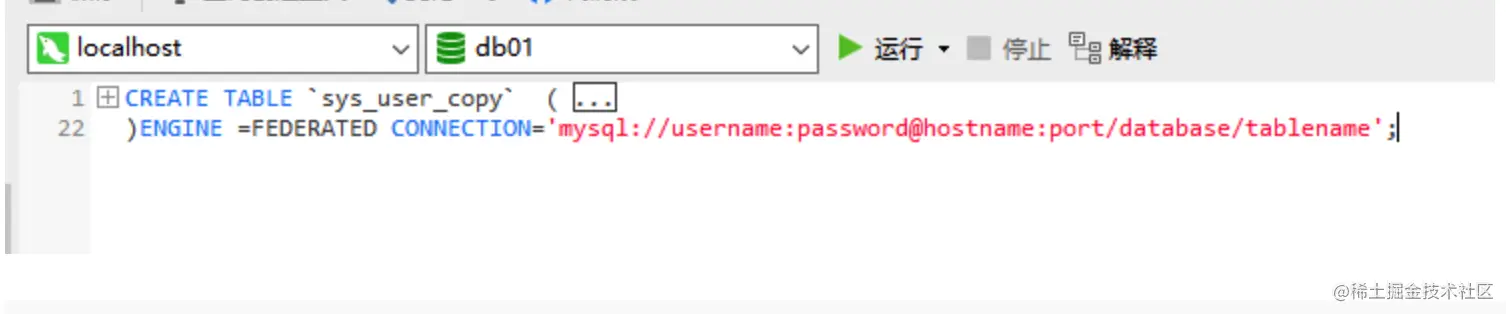
CREATE TABLE (......)
ENGINE =FEDERATED CONNECTION='mysql://username:[email protected]:port/database/tablename'
复制代码优点
- 不需要程序员介入,不需要开发
- Quick results,If you just want to query some data
缺点
- 本地表结构必须与远程表完全一样
- 不支持事务
- 不支持表结构修改
- 删除本地表,远程表不会删除
- 远程服务器必须是一个MySQL服务器
- Database data is not written locally,Essentially a soft link,Querying a large amount of data can cause the local memory to fill up,Because it is querying data from multiple databases to local memory,Then do the calculations in memory,此时时间复杂度为O(N^2),空间复杂度也为O(N^2);500条数据,The corresponding local time complexity is 25W,时间复杂度为25W;
可用于:Data import between two libraries,不涉及计算,即A导入B,不进行查询A\BDo a computational writeC;
The idea of Scheme 3 is drawn from the following article blog.csdn.net/qq_48721706…
结语
好的算法,It is also based on a good execution plan,所以,Three programs can be used as needed!
最后,If you have any other good solutions,Welcome to discuss with me~~~
边栏推荐
猜你喜欢






随机推荐
海思HI3516DV300开发资料
Toronto Research Chemicals BTK甜味剂配方丨D-Abequose
FPGA工程师面试试题集锦61~70
CSV(Comma-Separate-Values)逗号分隔值文件
Keil5退出仿真调试卡死的解决办法
HarmonyOS自动化测试框架—Hypium
报告详解影响英特尔10/11/12代酷睿处理器的ÆPIC Leak安全漏洞
postgis空间数据导入及可视化
【接入指南 之 直接接入】手把手教你快速上手接入HONOR Connect平台(下)
flex使用align-content无效
c语言进阶篇:柔性数组
组合模式
Interface test advanced interface script using -apipost (pre/post execution script)
Consul Introduction and Installation
兼具外观、性能、屏幕!华硕灵耀X 14火热抢购中
pyspark列合并为一行
【图像分割】基于元胞自动机实现图像分割附matlab代码
Interview Question 04.12. Summation Path-dfs+Auxiliary Array Method
redis.exceptions.DataError: Invalid input of type: ‘dict‘. Convert to a byte, string or number first
Flexsim 发生器设置label和颜色