当前位置:网站首页>机器学习理论之(7):核函数 Kernels —— 一种帮助 SVM 实现非线性化决策边界的方式
机器学习理论之(7):核函数 Kernels —— 一种帮助 SVM 实现非线性化决策边界的方式
2022-04-23 18:26:00 【暖仔会飞】
文章目录
关于 SVM 的原理和为什么 SVM 总是选用大的 margin 来决定决策边界,我在文章:
https://blog.csdn.net/qq_42902997/article/details/124310782
中给予了阐述,如果不明白的可以回顾一下
回顾SVM 的优化目标
C Σ i = 1 m y i c o s t 1 ( θ T x i ) + ( 1 − y i ) c o s t 0 ( θ T x i ) + 1 2 Σ j = 1 n θ j 2 ( 1 ) C\Sigma_{i=1}^m{y_i}cost_1(\theta^Tx_i)+(1-y_i)cost_0(\theta^Tx_i)+\frac{1}{2}\Sigma_{j=1}^n\theta_j^2~~~~~~~~~~(1) CΣi=1myicost1(θTxi)+(1−yi)cost0(θTxi)+21Σj=1nθj2 (1)
- 我们都知道 SVM 是一个线性分类器,那么面对下面这种线性不可分的场景:

- 如果要实现分类,那么绝对不可能使用线性分类器来实现,因此我们想要引入多项式来相当于构造更高阶的特征来达到最终非线性分类的目的。
- 看图中给出的这个公式;对于某一个样本的所有特征 x ⃗ = { x 1 , x 2 } \vec{x}=\{x_1,x_2\} x={
x1,x2};试图基于这些特征制造更加高阶的特征 x 1 x 2 , x 1 2 , x 2 2 x_1x_2, x_1^2, x_2^2 x1x2,x12,x22 等来构造一个非线性的决策边界:

- 那么沿着这个思路,我们用更加一般化的形式来表示,由于我们的目的是制造更加高阶的特征,所以我们采用 θ 0 + θ 1 f 1 + θ 2 f 2 + . . . + θ n f n \theta_0 + \theta_1f_1 + \theta_2f_2+...+\theta_nf_n θ0+θ1f1+θ2f2+...+θnfn 来表示我们的决策边界;其中 n n n 是我们最终使用的特征的数量; 而这些 f 1 , f 2 , . . . , f n f_1, f_2, ..., f_n f1,f2,...,fn 就是我们要使用的新的特征。
- 在上文的例子中, f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 , f 5 = x 2 2 , . . . f_1=x_1, f_2=x_2, f_3=x_1x_2, f_4=x_1^2,f_5=x_2^2, ... f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22,...
- 现在问题来了,如何保证我们这些 f 1 , . . . , f n f_1,...,f_n f1,...,fn 是有效的呢?
如何构造 f 1 , . . . , f n f_1,...,f_n f1,...,fn
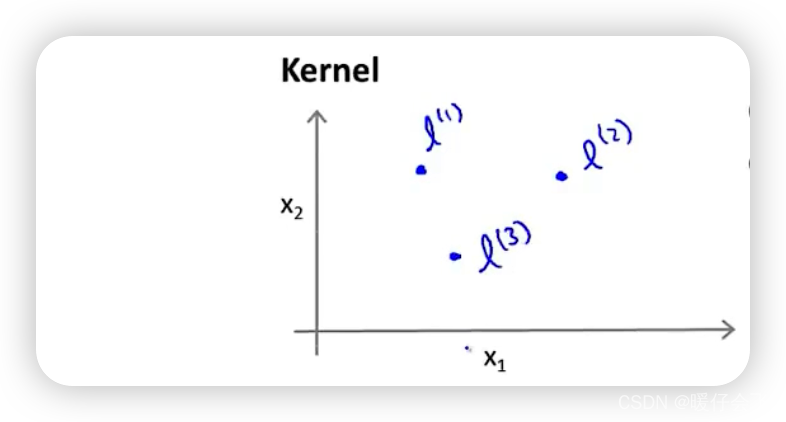
landmark & similarity
- 使用衡量当前样本点和一些 landmark(标记点)相似度的方式来生成 f 1 , . . . , f n f_1,...,f_n f1,...,fn。
还是使用上面提到的那个例子,对于每个样本点 x x x 使用两个特征来表示 x ⃗ = { x 1 , x 2 } \vec{x}=\{x_1,x_2\} x={ x1,x2},这个时候我们假设有 3 3 3 个不同的 landmarks(后文会详细解释 landmarks 是如何选定的)
接下来,我们分别衡量样本 x x x 和这三个 landmarks 的相似度作为 f 1 , . . . , f n f_1,...,f_n f1,...,fn 的定义过程:
- f 1 = s i m i l a r i t y ( x , l ( 1 ) ) f_1=similarity(x,l^{(1)}) f1=similarity(x,l(1))
- f 2 = s i m i l a r i t y ( x , l ( 2 ) ) f_2=similarity(x,l^{(2)}) f2=similarity(x,l(2))
- f 3 = s i m i l a r i t y ( x , l ( 3 ) ) f_3=similarity(x,l^{(3)}) f3=similarity(x,l(3))
而这个 s i m i l a r i t y similarity similarity 我们选用高斯核函数来定义(后面会做详细说明)
也就是说我们使用一个:
s i m i l a r i t y ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) similarity(x,z)=exp(-\frac{||x-z||^2}{2\sigma^2}) similarity(x,z)=exp(−2σ2∣∣x−z∣∣2)
因此,上面的 f 1 , . . f 3 f_1,..f_3 f1,..f3 可以被改造成:- f 1 = e x p ( − ∣ ∣ x − l ( 1 ) ∣ ∣ 2 2 σ 2 ) f_1=exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2}) f1=exp(−2σ2∣∣x−l(1)∣∣2)
- f 2 = e x p ( − ∣ ∣ x − l ( 2 ) ∣ ∣ 2 2 σ 2 ) f_2=exp(-\frac{||x-l^{(2)}||^2}{2\sigma^2}) f2=exp(−2σ2∣∣x−l(2)∣∣2)
- f 3 = e x p ( − ∣ ∣ x − l ( 3 ) ∣ ∣ 2 2 σ 2 ) f_3=exp(-\frac{||x-l^{(3)}||^2}{2\sigma^2}) f3=exp(−2σ2∣∣x−l(3)∣∣2)
Note: ∣ ∣ x − l ( 1 ) ∣ ∣ 2 = Σ i = 1 m ( x i − l i ) 2 ||x-l^{(1)}||^2=\Sigma_{i=1}^m(x_i-l_i)^2 ∣∣x−l(1)∣∣2=Σi=1m(xi−li)2 m m m 是一个样本 x x x 中使用的特征数量,在这里是 x 1 , x 2 x_1,x_2 x1,x2 两个特征所以 m = 2 m=2 m=2
可以看到,在这种函数的定义下,如果 x x x 和 l ( i ) l^{(i)} l(i) 非常相近,那么核函数的结果就会趋近于 f i ≈ e x p ( − 0 2 σ 2 ) ≈ 1 f_i\approx exp(-\frac{0}{2\sigma^2})\approx1 fi≈exp(−2σ20)≈1 ;相反,如果 x x x 和 l ( i ) l^{(i)} l(i) 比较远,那么结果就趋近于 0 0 0。
因此我们可以认为 f 1 , . . . , f n f_1,...,f_n f1,...,fn 分别衡量了 x x x 这个样本到这些 landmark 的相似程序(距离度量);而这些 f 1 , . . . , f n f_1,...,f_n f1,...,fn 成为了组成 x x x 这个样本的 n n n 个特征
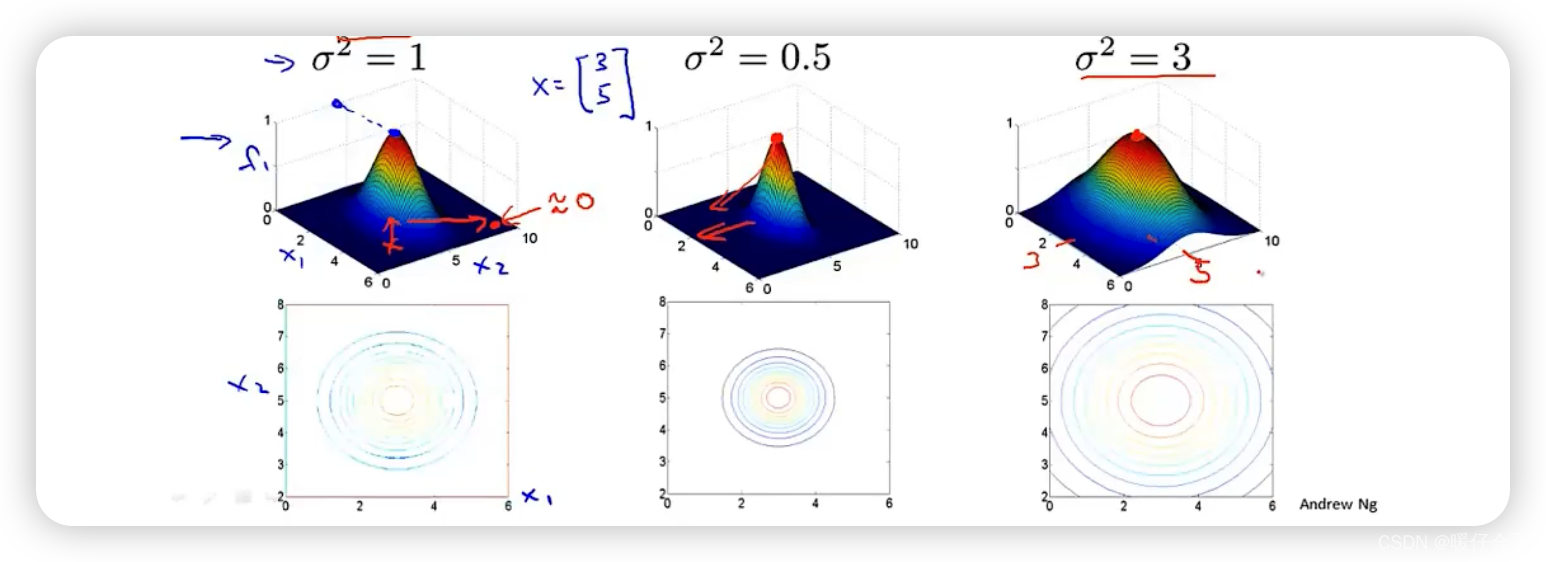
为了方便理解,我们将高斯核函数进行可视化
从图中也可以看出,当 l ( 1 ) l^{(1)} l(1) 在距离上越接近 x x x,那么其通过高斯核函数的结果就越接近这个图的中心,值就越接近 1 1 1;相反,如果越远则值越接近 0 0 0
我们也可以很简单的得出结论:高斯核函数的标准差 σ \sigma σ 的大小决定了分布的平滑程度,例如选用不同的 σ \sigma σ 分布不同:

如何产生非线性边界
- 假设我们已经通过求算得到了 θ 0 , θ 1 , . . . θ 3 \theta_0, \theta_1,...\theta_3 θ0,θ1,...θ3,他们的值分别如图所示:

- 如果这时候有一个样本 x x x 处于图中的位置:距离 l ( 1 ) l^{(1)} l(1) 很近,但是距离 l ( 2 ) , l ( 3 ) l^{(2)},l^{(3)} l(2),l(3) 很远,那么我们可以认为 f 1 ≈ 1 ; f 2 , f 3 ≈ 0 f_1\approx1; f_2, f_3\approx0 f1≈1;f2,f3≈0 通过带入公式求算,我们可以得到最终的预测结果是 > = 0 >=0 >=0 的,即正向样本。

- 如果此时还有一个样本 x x x,距离三个 l ( i ) l^{(i)} l(i) 都很远:我们根据同样的步骤可以求算出他的预测标签是 < 0 <0 <0 的,即负向样本。

- 如果样本量足够大,你会发现:这些样本最终的预测结果其实取决于所有的 landmarks,而因此产生的决策边界就会变成一个非线性的决策边界。位于红色边界内部的所有的样本都会被判断成正向样本,而位于红色边界外部的所有样本都会被判断成负向样本。

如何选取 landmarks
-
其实你可能已经想到了,我们完全可以使用这个数据集中的所有样本点 X = x ( 1 ) , x ( 2 ) , . . . , x ( n ) X={x^{(1)},x^{(2)},...,x^{(n)}} X=x(1),x(2),...,x(n) 来当做这些 landmarks l ( 1 ) = x ( 1 ) , l ( 2 ) = x ( 2 ) , . . . , l ( n ) = x ( n ) l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},...,l^{(n)}=x^{(n)} l(1)=x(1),l(2)=x(2),...,l(n)=x(n)
-
所以一个样本产生相似度的公式可以直接改写成如下形式:
- f 1 = e x p ( − ∣ ∣ x − x ( 1 ) ∣ ∣ 2 2 σ 2 ) f_1=exp(-\frac{||x-x^{(1)}||^2}{2\sigma^2}) f1=exp(−2σ2∣∣x−x(1)∣∣2)
- f 2 = e x p ( − ∣ ∣ x − x ( 2 ) ∣ ∣ 2 2 σ 2 ) f_2=exp(-\frac{||x-x^{(2)}||^2}{2\sigma^2}) f2=exp(−2σ2∣∣x−x(2)∣∣2)
- f 3 = e x p ( − ∣ ∣ x − x ( 3 ) ∣ ∣ 2 2 σ 2 ) f_3=exp(-\frac{||x-x^{(3)}||^2}{2\sigma^2}) f3=exp(−2σ2∣∣x−x(3)∣∣2)
.
.
. - f n = e x p ( − ∣ ∣ x − x ( n ) ∣ ∣ 2 2 σ 2 ) f_n=exp(-\frac{||x-x^{(n)}||^2}{2\sigma^2}) fn=exp(−2σ2∣∣x−x(n)∣∣2)
-
由此,每一个样本 x ( i ) x^{(i)} x(i) 的特征向量 x ( i ) ⃗ \vec{x^{(i)}} x(i) 由原本的 { x 1 ( i ) , x 2 ( i ) } \{x^{(i)}_1,x^{(i)}_2\} { x1(i),x2(i)} 变成了 f ( i ) ⃗ = { f 1 ( i ) , f 2 ( i ) , . . . , f n ( i ) } \vec{f^{(i)}}=\{f^{(i)}_1, f^{(i)}_2,..., f^{(i)}_n\} f(i)={ f1(i),f2(i),...,fn(i)};其实这里我们省略了截距特征 f 0 ( i ) f^{(i)}_0 f0(i),如果想加上也很简单, f ( i ) ⃗ = { f 0 ( i ) , f 1 ( i ) , f 2 ( i ) , . . . , f n ( i ) } \vec{f^{(i)}}=\{f^{(i)}_0, f^{(i)}_1, f^{(i)}_2,..., f^{(i)}_n\} f(i)={ f0(i),f1(i),f2(i),...,fn(i)}
-
同样要发生改变的,是跟这 n n n 维向量(如果算 f 0 f_0 f0 就是 n + 1 n+1 n+1 维)向量对应的 θ ⃗ = θ 0 , . . . , θ n \vec{\theta}={\theta_0,..., \theta_n} θ=θ0,...,θn
-
最终我们通过 θ T ⋅ f ⃗ = θ 0 f 0 + . . . + θ n f n > = 0 \theta^T \cdot \vec{f} = \theta_0f_0+...+\theta_nf_n>=0 θT⋅f=θ0f0+...+θnfn>=0 来预测一个正向样本。
SVM结合核函数
-
结合上面的内容,我们反过头来看 SVM 的目标函数,对于一个包含 m m m 个样本的数据集:
C Σ i = 1 m y i c o s t 1 ( θ T x ( i ) ) + ( 1 − y i ) c o s t 0 ( θ T x ( i ) ) + 1 2 Σ j = 1 n θ j 2 ( 1 ) C\Sigma_{i=1}^m{y_i}cost_1(\theta^Tx^{(i)})+(1-y_i)cost_0(\theta^Tx^{(i)})+\frac{1}{2}\Sigma_{j=1}^n\theta_j^2~~~~~~~~~~(1) CΣi=1myicost1(θTx(i))+(1−yi)cost0(θTx(i))+21Σj=1nθj2 (1) -
我们可以将这个优化目标改写为:
C Σ i = 1 m y i c o s t 1 ( θ T ⋅ f ( i ) ⃗ ) + ( 1 − y i ) c o s t 0 ( θ T ⋅ f ( i ) ⃗ ) + 1 2 Σ j = 1 n θ j 2 ( 2 ) C\Sigma_{i=1}^m{y_i}cost_1(\theta^T\cdot \vec{f^{(i)}})+(1-y_i)cost_0(\theta^T\cdot \vec{f^{(i)}})+\frac{1}{2}\Sigma_{j=1}^n\theta_j^2~~~~~~~~~~(2) CΣi=1myicost1(θT⋅f(i))+(1−yi)cost0(θT⋅f(i))+21Σj=1nθj2 (2) -
也就是将原本的 x x x 的特征向量转换成新的基于 f f f 的特征向量;现在样本的数量为 m m m。
-
于此同时,正则化部分的 n n n 原本代表的是一个样本 x ( i ) x^{(i)} x(i) 中的有效特征数,现在这个量也可以替换成 m m m了,因为有效的特征数量就是样本数量,所以公式再度被优化成:
C Σ i = 1 m y i c o s t 1 ( θ T ⋅ f ( i ) ⃗ ) + ( 1 − y i ) c o s t 0 ( θ T ⋅ f ( i ) ⃗ ) + 1 2 Σ j = 1 m θ j 2 ( 2 ) C\Sigma_{i=1}^m{y_i}cost_1(\theta^T\cdot \vec{f^{(i)}})+(1-y_i)cost_0(\theta^T\cdot \vec{f^{(i)}})+\frac{1}{2}\Sigma_{j=1}^m\theta_j^2~~~~~~~~~~(2) CΣi=1myicost1(θT⋅f(i))+(1−yi)cost0(θT⋅f(i))+21Σj=1mθj2 (2)
- 这里的 j = 1... m j=1...m j=1...m 不能包含截距的那个特征,也就是说正则化的这个部分,只能最多有 m m m 个项,因为截距特征不包含在正则化的优化中所以不能写成 j = 0... m j=0...m j=0...m。
- 所以正则项还可以写成 θ T ⋅ θ ( i g n o r i n g θ 0 ) \theta^T\cdot \theta ~~~(ignoring~~ \theta_0) θT⋅θ (ignoring θ0)
版权声明
本文为[暖仔会飞]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_42902997/article/details/124335937
边栏推荐
- Dock installation redis
- WiFi ap6212 driver transplantation and debugging analysis technical notes
- Robocode Tutorial 4 - robocode's game physics
- C language to achieve 2048 small game direction merging logic
- Pointers in rust: box, RC, cell, refcell
- Error reported when running tensorboard: valueerror: duplicate plugins for name projector, solution
- QT error: no matching member function for call to ‘connect‘
- Creation and use of QT dynamic link library
- Rust: shared variable in thread pool
- Cells in rust share variable pointers
猜你喜欢

powerdesigner各种字体设置;preview字体设置;sql字体设置
How to restore MySQL database after win10 system is reinstalled (mysql-8.0.26-winx64. Zip)
Use of regular expressions in QT

QT add external font ttf
Imx6 debugging LVDS screen technical notes
Halo 开源项目学习(七):缓存机制

Installation du docker redis

Multifunctional toolbox wechat applet source code
Robocode tutorial 5 - enemy class
Win1远程出现“这可能是由于credssp加密oracle修正”解决办法
随机推荐
CISSP certified daily knowledge points (April 15, 2022)
Creation and use of QT dynamic link library
C language to achieve 2048 small game direction merging logic
In win10 system, all programs run as administrator by default
Docker 安装 Redis
powerdesigner各种字体设置;preview字体设置;sql字体设置
QT add external font ttf
Spark performance optimization guide
PowerDesigner various font settings; Preview font setting; SQL font settings
NVIDIA Jetson: GStreamer and openmax (GST OMX) plug-ins
QT error: no matching member function for call to ‘connect‘
CISSP certified daily knowledge points (April 12, 2022)
Software test summary
使用 bitnami/postgresql-repmgr 镜像快速设置 PostgreSQL HA
idea中安装YapiUpload 插件将api接口上传到yapi文档上
Rewrite four functions such as StrCmp in C language
多功能工具箱微信小程序源码
Pyppeter crawler
Log4j2 cross thread print traceid
QT excel operation summary