当前位置:网站首页>机器学习笔记:t-SNE
机器学习笔记:t-SNE
2022-08-10 20:24:00 【UQI-LIUWJ】
0 前言
- t-SNE(t-Distributed Stochastic Neighbor Embedding)
- 是一种非常常用的数据降维,常用于数据可视化
- t-SNE/SNE的基本原理是:
- 在高维空间构建一个概率分布拟合高维样本点间的相对位置关系
- 在低维空间,也构建 一个概率分布,拟合低维样本点之间的位置关系
- 通过学习,调整低维数据点,令两个分布接近
1 SNE 随机邻域嵌入 ( Stochastic Neighbor Embedding )

(类似于softmax)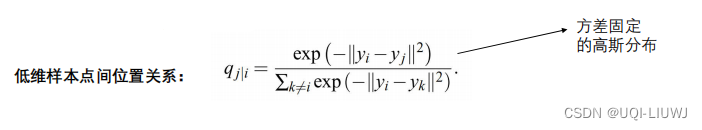
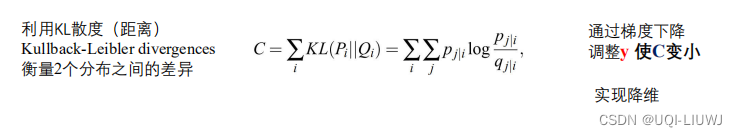
- 如果低维映射点yi和yj成功正确地建模了高维数据点xi和xj之间的相似性,则条件概率pj|i和qj|i将相等。
受这一观察结果的启发,SNE的目标是找到一种低维数据表示法,以最小化pj|i和qj|i之间的分布距离(两个条件分布接近)
1.1 SNE主要缺点
1.1.1 距离不对称
不难发现
是不等的(分母不一样) ,这就导致了i—>j和j—>i的距离不对称。【与实际情况不符】

 是不等的(分母不一样) ,这就导致了i—>j和j—>i的距离不对称。【与实际情况不符】
是不等的(分母不一样) ,这就导致了i—>j和j—>i的距离不对称。【与实际情况不符】改进的方法是使用联合概率而不是条件概率

在实际问题中,计算所有的 需要太多的计算复杂度,于是实际应用中,一般是:
需要太多的计算复杂度,于是实际应用中,一般是:
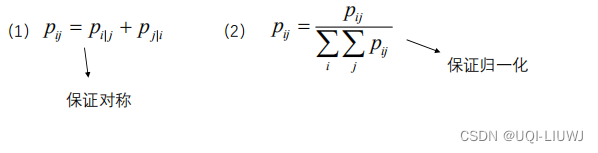
1.1.2 拥挤体现
从高维到低维进行转换的过程中,低维点的距离无法建模高维点之间的位置关系,使得高维空间中距离较大的点对,在低维空间距离会变得较小比如原来红绿点之间距离很远,降维之后距离就很近了


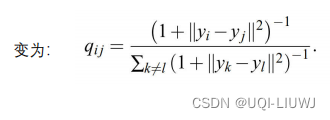

2 T-SNE


2.1 σ的求法
最naive的方法就是随机设置了。
更有效地方法如下:
我们把
看成高斯分布,那么σ就类似于标准差
根据高斯分布的性质,我们知道,在
(k是一个常数)的区间内,概率是比较大的。
所以我们根据xi周围临近点的数量,来增减σ

 (k是一个常数)的区间内,概率是比较大的。
(k是一个常数)的区间内,概率是比较大的。
那么,如何对σ进行定量的约束呢,我们设置一个固定的参数perlexity,表示分布的熵。

其中
不难发现熵(perplexity)和σi成正比,所以我们可用类似于二分查找法来确定σi
边栏推荐
猜你喜欢
Tf ferritin particles contain cisplatin / oxaliplatin / doxorubicin / methotrexate MTX / paclitaxel PTX and other drugs
(10) Sequence and deserialization of image data
 [email protected])纳米酶"/>
[email protected])纳米酶"/>血红素-金纳米颗粒(Heme-AuNP)复合纳米酶|金纳米颗粒核多孔空心碳纳米球壳([email protected])纳米酶
Colocate Join :ClickHouse的一种高性能分布式join查询模型
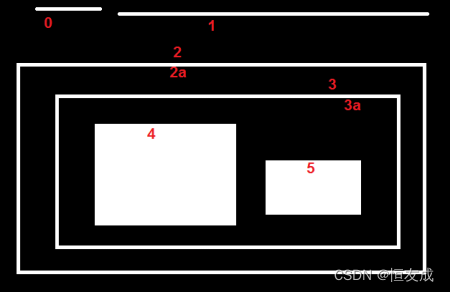
(十二) findContours函数的hierarchy详解
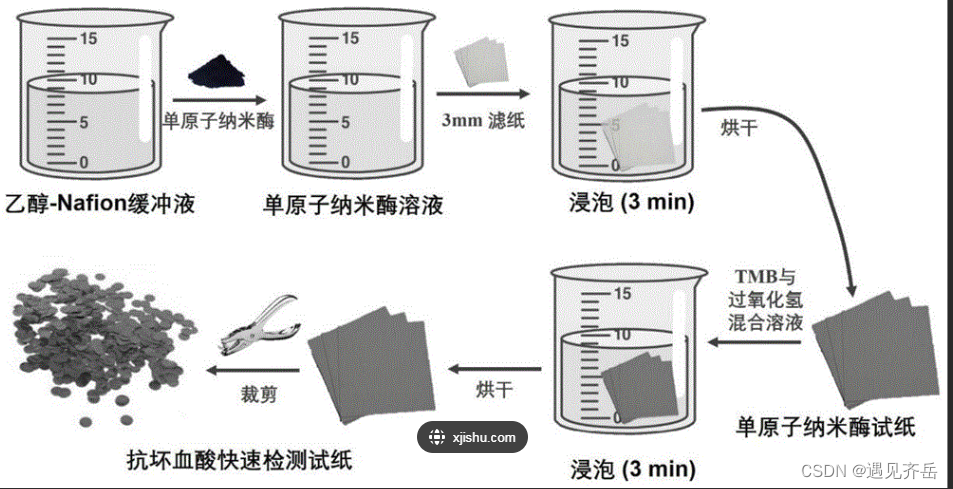 [email protected] NPs纳米酶|碳纳米管负载铂颗粒纳米酶|白血病拮抗多肽修饰的FeOPtPEG复合纳米酶"/>
[email protected] NPs纳米酶|碳纳米管负载铂颗粒纳米酶|白血病拮抗多肽修饰的FeOPtPEG复合纳米酶"/>Pt/CeO2单原子纳米酶|[email protected] NPs纳米酶|碳纳米管负载铂颗粒纳米酶|白血病拮抗多肽修饰的FeOPtPEG复合纳米酶
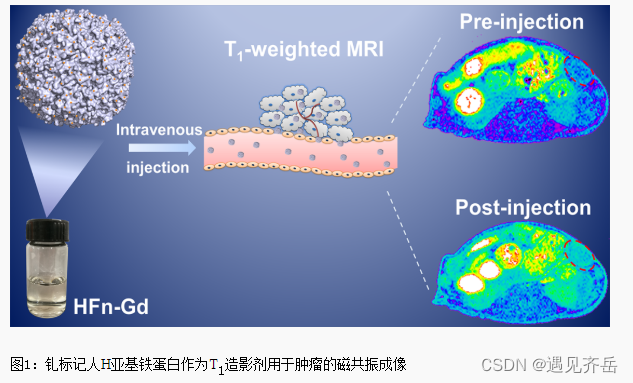
铁蛋白颗粒Tf包载多肽/凝集素/细胞色素C/超氧化物歧化酶/多柔比星(定制服务)
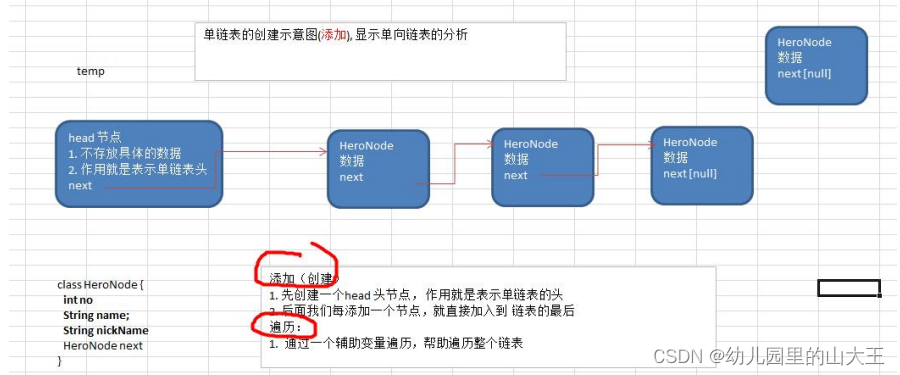
线性结构----链表
深度学习实战教程(一):感知器

Demis Hassabis:AI 的强大,超乎我们的想象
随机推荐
TDD、FDD是什么意思?
设备管理中数据聚类处理
UnitTest中的Path must be within the project 问题
转铁蛋白(TF)修饰紫杉醇(PTX)脂质体(TF-PTX-LP)|转铁蛋白(Tf)修饰姜黄素脂质体
[SemiDrive source code analysis] [MailBox inter-core communication] 52 - DCF Notify implementation principle analysis and code combat
链表应用----约瑟夫问题
The most complete GIS related software in history (CAD, FME, ArcGIS, ArcGISPro)
铁蛋白颗粒负载雷替曲塞/培美曲塞/磺胺地索辛/金刚烷(科研试剂)
mysql踩坑----case when then用法
血红素-金纳米颗粒(Heme-AuNP)复合纳米酶|金纳米颗粒核多孔空心碳纳米球壳([email protected])纳米酶
“蔚来杯“2022牛客暑期多校训练营7 F
win10 xbox录屏功能不能录声音怎么办
线性结构----链表
手把手教你Charles抓包工具使用
报错:runtime error: reference binding to null pointer of type ‘std::vector<int, std::allocator<int>>‘
【图像分类】2017-MobileNetV1 CVPR
爱丁堡大学最新《因果机器学习: 医疗健康与精准医疗应用》2022综述
《分布式微服务电商》专题(一)-项目简介
双 TL431 级联振荡器
【SemiDrive源码分析】【MailBox核间通信】51 - DCF_IPCC_Property实现原理分析 及 代码实战