当前位置:网站首页>快速了解集成学习
快速了解集成学习
2022-08-11 05:35:00 【Pr4da】
1.什么是集成学习
集成学习(ensemble learning)是一类机器学习框架,通过构建并结合多个学习器来完成学习任务。一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。结合策略主要有平均法、投票法和学习法等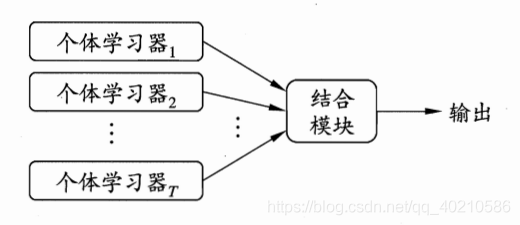
集成学习包含三个典型算法:Bagging、Staking和Boosting
2.Bagging算法
我们从很多的个体学习器中得到了不同效果的分类模型,那么怎么得到最终的模型呢?
- 平均
- 投票
a.Majority voting :少数服从多数(随机森林)
b.Weighted Majority Voting: 带加权的投票法(AdaBoost)(老板投票的权重和员工投票的权重是不一样的)
集成学习的前提是个体学习器得到的结果不能完全相同,这样才有意义,我们可以将每个个体学习器都使用不同的方法,例如SVM, KNN, DT, … 这是可行的,但是通常情况下个体学习器的模型应该相同。那么得到不同的学习结果的方法有:
1. 初始化参数不同
2. 不同的训练集
3. 不同特征集
比如有100个特征,我们只用其中的50个特征进行训练,可能有同学就会问,特征不是越多学习的效果越好吗?但是其实不是这样的,在集成学习中,我们希望个体学习机越弱越好(Weak learners)。越强的学习器,所消耗的资源也越多,也越容易造成过拟合。
为了得到不同的训练模型,但是又得到一个类似的分布。我们可以采用Bootstrap sample的采样方法(有放回的采样)。例如,我们有5个球,5个不同的颜色,每次取一个球,取完了放回去,那么取5次可能得到重复的样本,也有可能有的样本不被抽到,如下图。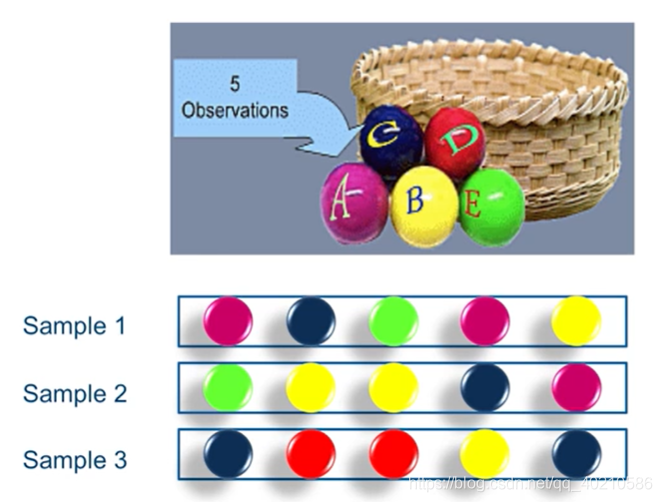
Bagging的集成学习方法非常简单,假设我们有一个数据集D,使用Bootstrap sample的方法取了k个数据子集:D1,D2,…,Dk。我们使用这k个子集分别训练一个分类器,最后会得到k个分类模型。我们将测试数据输入到这k个分类器,会得到k个分类结果,比如分类结果是0和1,那么这k个结果中谁占比最多,那么预测结果就是谁,这就是bagging方法。
3.Stacking算法
Boosting的方法是根据“少数服从”多数来决定的,这里执行的是“一人一票”的方式,但是在公司中,老板的票一般来说要比员工的票有分量,所以可以在投票上乘以一个权重。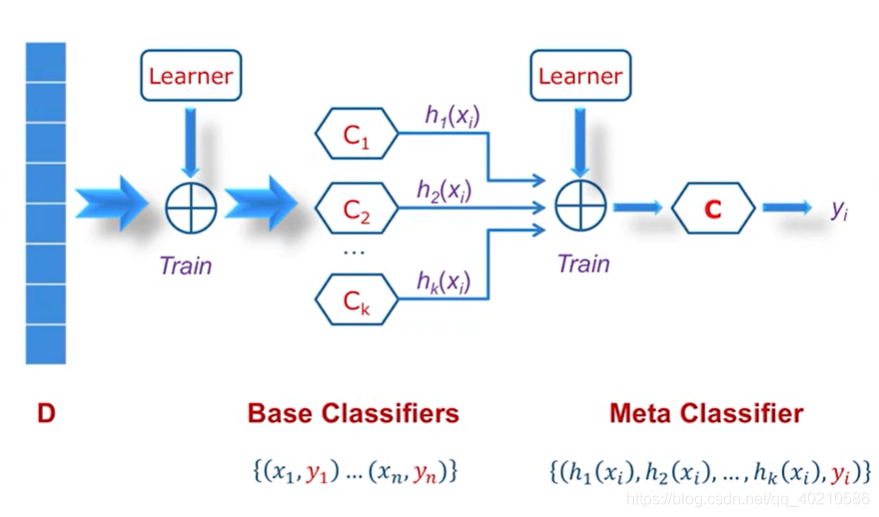
Stacking的算法前面和Bagging算法一样,得到了不同的投票结果:c1, c2, c3,….,我们可以在这些结果上乘上一个权重,再用一个分类器进行训练,得到一个预测结果,第二个分类器可以是神经网络,svm等。
4.Boosting算法
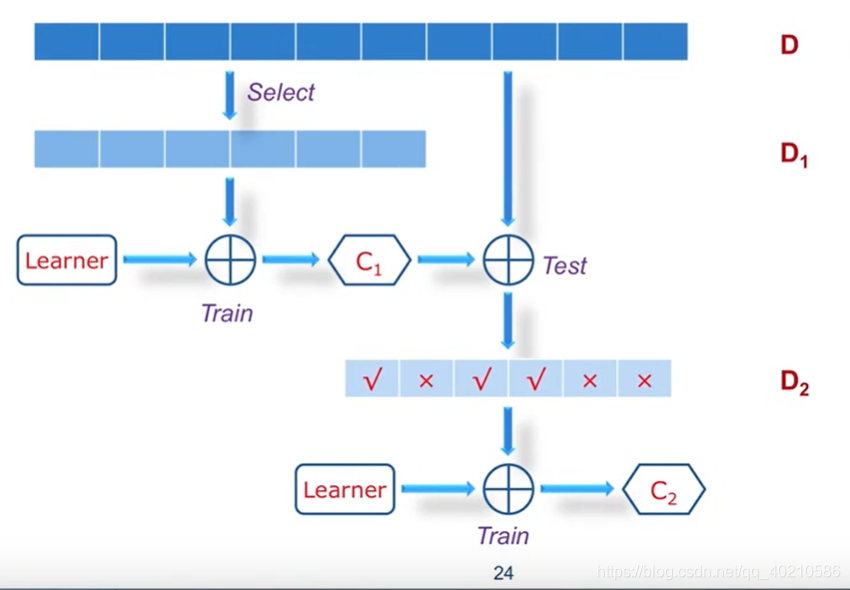

Boosting的思想就是针对预测错的样本,再进行训练。但是这样做还不够,我们用C1和C2同时预测D,有的预测为0,有的预测为1怎么办?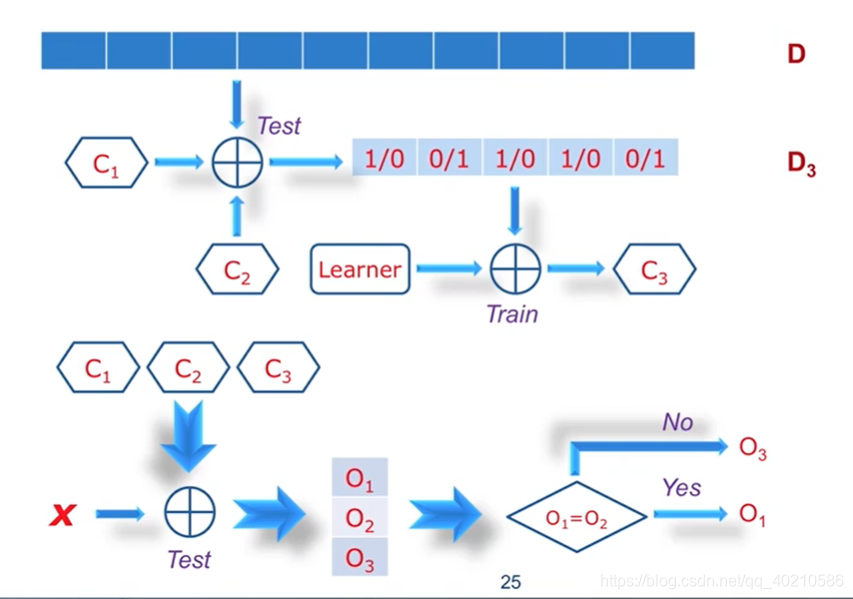
在前面的基础上,我们还进行如下操作:
Bagging算法可能有几百上千个分类器,而Boosting算法三个就可以了(也可以50个)。在训练样本过程中我们也可以给数据集D中样本被选中的可能性加权,如果总是预测正确,那我就不需要再考虑该样本了,我们应当把重点放在有争议的样本上。
边栏推荐
猜你喜欢

随机推荐
ansible批量安装zabbix-agent
MySQL之函数
查看CPU和其他硬件温度的软件
SECURITY DAY01(监控概述 、 Zabbix基础 、 Zabbix监控服 )
SECURITY DAY04( Prometheus服务器 、 Prometheus被监控端 、 Grafana 、 监控数据库)
八股文之并发编程
No threat of science and technology - TVD vulnerability information daily - 2022-7-21
Map Reduce
SECURITY DAY04 (Prometheus server, Prometheus monitored terminal, Grafana, monitoring database)
window7开启远程桌面功能
HCIP BGP neighbor building, federation, and aggregation experiments
HCIP-BGP的选路实验
pytorch下tensorboard可视化深坑
OA项目之项目简介&会议发布
HCIA实验
Top20括号匹配
CLUSTER DAY03( Ceph概述 、 部署Ceph集群 、 Ceph块存储)
SECURITY DAY06 ( iptables firewall, filter table control, extended matching, typical application of nat table)
slurm集群搭建
HCIP实验(pap、chap、HDLC、MGRE、RIP)