当前位置:网站首页>Pytorch GPU模型推理时间探讨
Pytorch GPU模型推理时间探讨
2022-08-10 16:37:00 【pip install USART】
前言
最近对pytorch的模型推理(inference)时间产生了兴趣,于是想着写一个小程序来观察一下现象。遂以此文记之。
实验配置
主要思路:
- 创建多个不同规格的模型,每个模型只有一个简单的卷积层。
- 以卷积的各种不同参数作为模型的区别。
- 以随机数来生成一批数据,用***[B,C,W,H]***来表示。
- 每个模型进行100次推理,分10批次完成,记录这10批次的时间和平均时间。
硬件配置
影响一个模型的推理速度的硬件应该主要就是这些了,还有一个带宽问题。
显卡:RTX 2080ti
内存:16G 2666MHz
CPU:Intel i5-9400F
系统:win10
主板:忘了
实验结果
具体的网络规格这里就略去了,都是随便举的例子,没啥信息量。直接看结果吧。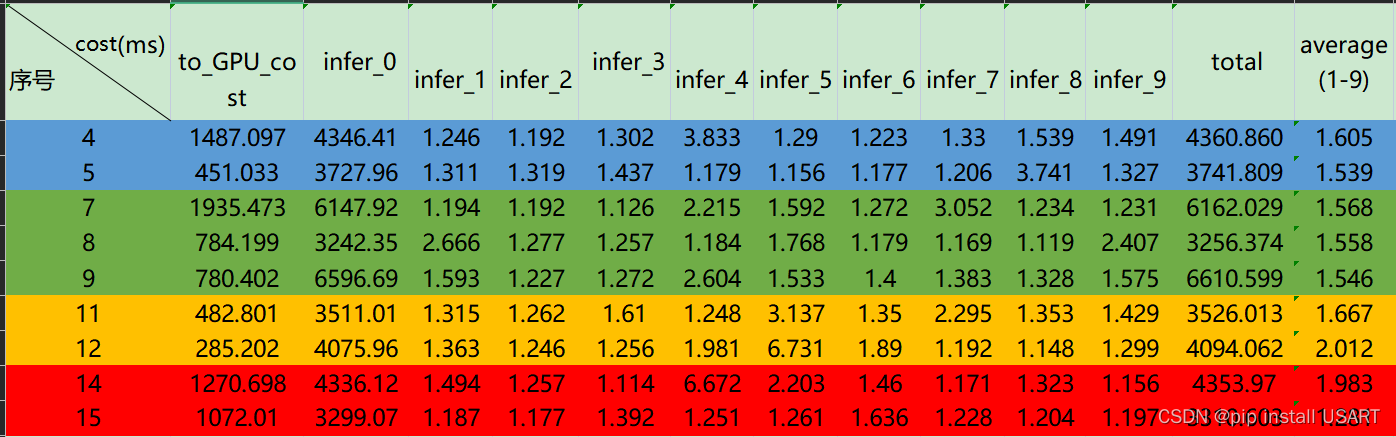
如上图所示,其中的序号表示模型序号,可以得到几个现象:
1.每个模型的每轮10次推理中,第一轮总是相对来说很慢的
2.这些模型的平均推理时间相差不大,也就是还没达到显卡的算力门槛。
3.平均推理时间相差不大的情况下,to_GPU_cost的区别较大。
解释与猜想
理论上每次推理时间应该是一样的,但就表格数据来看,1-9次的区别有些也很大。
这一现象可能是由于计时方法产生的,所用计时方法是time库的perf_counter方法,该方法是由CPU来执行的,而显卡计算后通知CPU,这之间还有通信差距。
每次的第一轮推理都很慢可能是因为GPU第一次做推理需要进行模型参数的初始化。
中间还有一个小插曲,一开始我是在一个py程序里多次调用testModel这个方法,不同的模型作为参数传递进去,但是发现只有第一次调用时(也就是第一个模型的第一轮10次推理)才会用那么多时间,于是我改了一下代码,将模型参数作为main的参数,重写了一个bat(windows的批处理文件)来依次执行多个模型。
暂时先记录到这里,目前已经有了初步的认识,等后续再进一步研究研究
边栏推荐
- LabView---双通道示波器(内含信号发生器)
- glui.h无法找到描述+解决+测试
- matsuri.icu 筛选单场直播中 指定用户的弹幕
- 超宽带uwb精准定位,厘米级室内定位技术,实时高精度方案应用
- 易基因|深度综述:m6A RNA甲基化在大脑发育和疾病中的表观转录调控作用
- Yi Gene|In-depth review: epigenetic regulation of m6A RNA methylation in brain development and disease
- Qt 绘图和绘图设备
- LeetCode-922. Sort Array By Parity II
- MySQL的使用演示及操作,MySQL数据字符集的设置
- 网页分析和一些基础题目
猜你喜欢





随机推荐
ahx文件转mav文件 工具分享及说明
CDF 图的含义
数据可视化:Metabase
阿里工作7年,肝到P8就剩这份学习笔记了,已助朋友拿到10个Offer
软件工程基础知识--需求分析
How to generate code using the Swift Package plugin
异常处理的超详细讲解
v-on补充:自定义参数传递和事件修饰符
家电巨头,不碰儿童生意
【QT VS项目名称修改】
一张图快速了解 Istio 的 EnvoyFilter
Lua--table操作
雷达存在感应器技术,实时感知控制应用,雷达人体探测方案
接口测试中,应不应该用数据库
rtsp 和 rtmp 推流(一)
Alluxio on Amazon EMR 集成实践
MySQL的使用演示及操作,MySQL数据字符集的设置
解决mpi4py导入报错ImportError: libmpi.so.40: cannot open shared object file: No such file or directory
如何将jpg图片变成gif?教你一分钟图片合成gif的方法
在Istio中,到底怎么获取 Envoy 访问日志?