当前位置:网站首页>Etcd Kubernetes 集群稳定性:LIST 请求源码分析、性能评估与大规模基础服务部署调优
Etcd Kubernetes 集群稳定性:LIST 请求源码分析、性能评估与大规模基础服务部署调优
2022-08-10 15:40:00 【富士康质检员张全蛋】
对于非结构化的数据存储系统来说,LIST 操作通常都是非常重量级的,不仅占用大量的 磁盘 IO、网络带宽和 CPU,而且会影响同时间段的其他请求(尤其是响应延迟要求极高的 选主请求),是集群稳定性的一大杀手。
例如,对于 Ceph 对象存储来说,每个 LIST bucket 请求都需要去多个磁盘中捞出这个 bucket 的全部数据;不仅自身很慢,还影响了同一时间段内的其他普通读写请求,因为 IO 是共享的,导致响应延迟上升乃至超时。如果 bucket 内的对象非常多(例如用作 harbor/docker-registry 的存储后端),LIST 操作甚至都无法在常规时间内完成( 因而依赖 LIST bucket 操作的 registry GC 也就跑不起来)。
又如 KV 存储 etcd。相比于 Ceph,一个实际 etcd 集群存储的数据量可能很小(几个 ~ 几十个 GB),甚至足够缓存到内存中。但与 Ceph 不同的是,它的并发请求数量可能会高几个量级,比如它是一个 ~4000 nodes 的 k8s 集群的 etcd。单个 LIST 请求可能只需要 返回几十 MB 到上 GB 的流量,但并发请求一多,etcd 显然也扛不住,所以最好在前面有 一层缓存,这就是 apiserver 的功能(之一)。K8s 的 LIST 请求大部分都应该被 apiserver 挡住,从它的本地缓存提供服务,但如果使用不当,就会跳过缓存直接到达 etcd,有很大的稳定性风险。
本文深入研究 k8s apiserver/etcd 的 LIST 操作处理逻辑和性能瓶颈,并提供一些基础服务的 LIST 压力测试、 部署和调优建议,提升大规模 K8s 集群的稳定性。
kube-apiserver LIST 请求处理逻辑:

1 引言
1.1 K8s 架构:环形层次视图
从架构层次和组件依赖角度,可以将一个 K8s 集群和一台 Linux 主机做如下类比:

Fig 1. Anology: a Linux host and a Kubernetes cluster
对于 K8s 集群,从内到外的几个组件和功能:
- etcd:持久化 KV 存储,集群资源(pods/services/networkpolicies/…)的唯一的权威数据(状态)源;
- apiserver:从 etcd 读取(
List Watch)全量数据,并缓存在内存中;无状态服务,可水平扩展; - 各种基础服务(e.g.
kubelet、*-agent、*-operator):连接 apiserver,获取(List/ListWatch)各自需要的数据; - 集群内的 workloads:在 1 和 2 正常的情况下由 3 来创建、管理和 reconcile,例如 kubelet 创建 pod、cilium 配置网络和安全策略。
1.2 apiserver/etcd 角色
以上可以看到,系统路径中存在两级 List/ListWatch(但数据是同一份):
- apiserver List/ListWatch etcd
- 基础服务 List/ListWatch apiserver
因此,从最简形式上来说,apiserver 就是挡在 etcd 前面的一个代理(proxy),
+--------+ +---------------+ +------------+
| Client | -----------> | Proxy (cache) | --------------> | Data store |
+--------+ +---------------+ +------------+
infra services apiserver etcd
- 绝大部分情况下,apiserver 直接从本地缓存提供服务(因为它缓存了集群全量数据);
某些特殊情况,例如,
- 客户端明确要求从 etcd 读数据(追求最高的数据准确性),
- apiserver 本地缓存还没建好
apiserver 就只能将请求转发给 etcd —— 这里就要特别注意了 —— 客户端 LIST 参数设置不当也可能会走到这个逻辑。
1.3 apiserver/etcd List 开销
1.3.1 请求举例
考虑下面几个 LIST 操作:
LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0这里同时传了两个参数,但
resourceVersion=0会导致 apiserver 忽略limit=500, 所以客户端拿到的是全量 ciliumendpoints 数据。一种资源的全量数据可能是比较大的,需要考虑清楚是否真的需要全量数据。 后文会介绍定量测量与分析方法。
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1这个请求是获取
node1上的所有 pods(%3D是=的转义)。根据 nodename 做过滤,给人的感觉可能是数据量不太大,但其实背后要比看上去复杂:
- 首先,这里没有指定 resourceVersion=0,导致 apiserver 跳过缓存,直接去 etcd 读数据;
- 其次,etcd 只是 KV 存储,没有按 label/field 过滤功能(只处理
limit/continue), - 所以,apiserver 是从 etcd 拉全量数据,然后在内存做过滤,开销也是很大的,后文有代码分析。
这种行为是要避免的,除非对数据准确性有极高要求,特意要绕过 apiserver 缓存。
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0跟 2 的区别是加上了
resourceVersion=0,因此 apiserver 会从缓存读数据,性能会有量级的提升。但要注意,虽然实际上返回给客户端的可能只有几百 KB 到上百 MB(取决于 node 上 pod 的数量、pod 上 label 的多少等因素), 但 apiserver 需要处理的数据量可能是几个 GB。 后面会有定量分析。
以上可以看到,不同的 LIST 操作产生的影响是不一样的,而客户端看到数据还有可能只是 apiserver/etcd 处理数据的很小一部分。如果基础服务大规模启动或重启, 就极有可能把控制平面打爆。
边栏推荐
猜你喜欢



随机推荐
uniapp使用scroll-view,设置横向,内容重叠的问题解决
JVM学习——2——内存加载过程(类加载器)
【每日一题】【leetcode】25. 数组-旋转数组的最小数字
cmake记录
Ameya360成为稳先微电子中国区域授权代理!
TestLink Export Use Case Transformation Tool
scala 10种函数高级应用
一个 ABAP 开发的新浪微博语义情感分析工具
一文让你快速了解大小端概念!
【FreeRTOS】13 动态内存管理
二维费用的背包问题 ← 模板题
Detailed understanding of all built-in functions (Part 2)
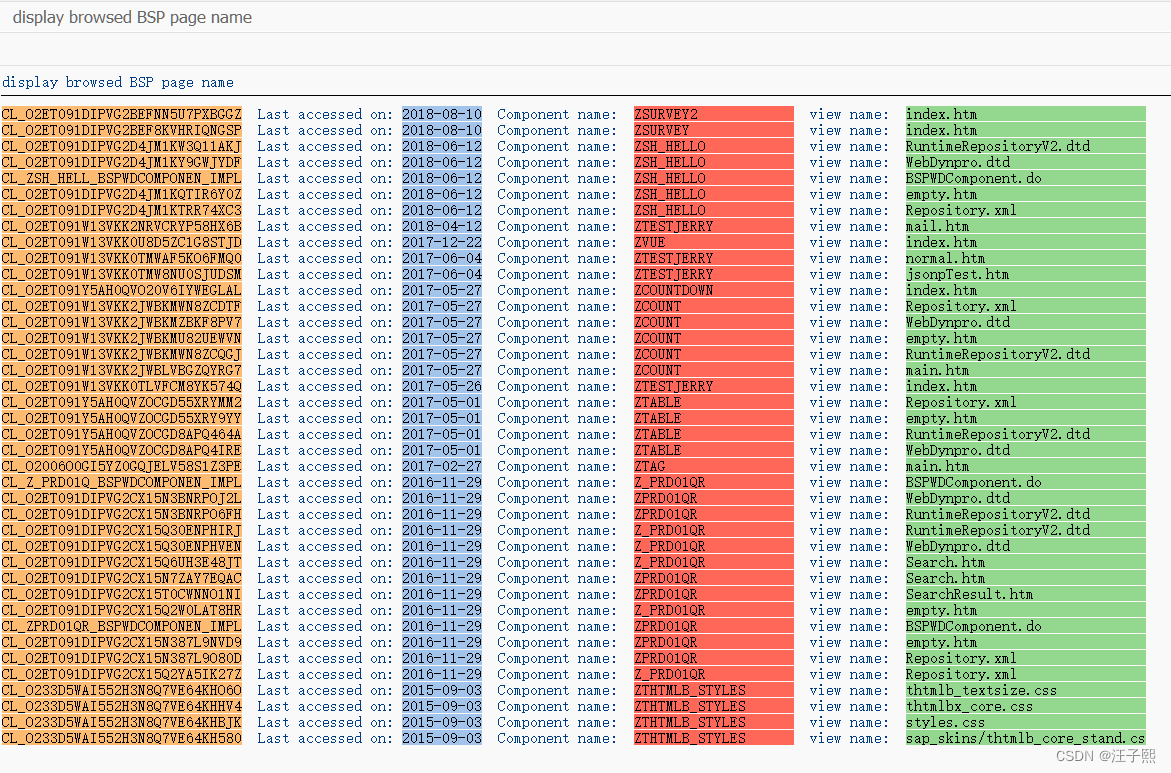
An ABAP tool that can print the browsing history of a user in the system for BSP applications
网络工程师的背包(EDC总结推荐)
storage of data in memory
力扣+牛客--刷题记录
数据治理项目成功的要点,企业培养数据要把握好关键环节
Recommend a few had better use the MySQL open source client, collection!
IPC:Interrupts and Signals
[Letter from Wu Enda] The development of reinforcement learning!