当前位置:网站首页>【硬件架构的艺术】学习笔记(4)流水线的艺术
【硬件架构的艺术】学习笔记(4)流水线的艺术
2022-08-10 16:31:00 【Linest-5】
目录
写在前面
这个博客系列是对最近阅读的书籍《硬件架构的艺术》的部分内容的读书笔记,大部分的内容是摘抄书上的内容,小部分是自己的笔记,对书上部分知识点的理解以及拓展(红色标注)。
4. 流水线的艺术
4.1 介绍
对高速 ASIC 日益增长的需求使得越来越需要增加电路每个时钟周期的计算吞吐率。可以通过流水线提高 ASIC 在这方面的性能,但是也会带来系统延迟和面积的增加。
流水线通过在较长的组合逻辑路径中插入寄存器降低了组合逻辑的延迟,从而增加了时钟频率并提高了性能。
下图为插入流水线前的组合逻辑电路。
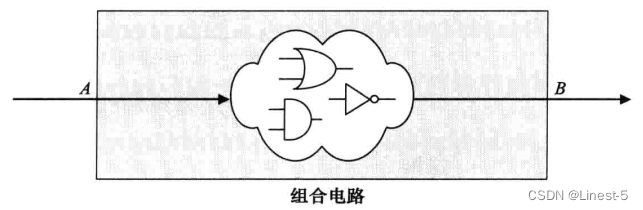
图中的组合路径延迟为 X 个时间单位(在 A 点和 B 点之间)。同样的路径在下图中通过插入三个寄存器被分割成多个小块,寄存器间的延迟为 Y 个时间单位,这里 Y
下图为插入流水线后的电路示意图。

在实际的设计中,在过长的组合逻辑用时序逻辑进行截断有助于提高时序,对提高整个系统的工作时钟频率有帮助,虽然会稍稍增加延时和资源消耗。
4.2 影响最大时钟频率的因素
时钟频率是数据流入系统后在输出端出现的速率。有许多因素都会影响流水线系统的最大时钟频率。首先,考虑图中所示的两条流水线阶段之间的理想路径。
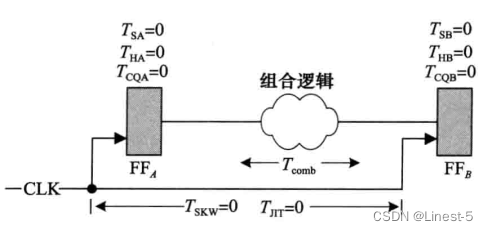
Tcomb:寄存器 A 和 B 间的组合延迟
TSA:寄存器 A 的建立时间
THA:寄存器 A 的保持时间
TCQA:寄存器 A 的时钟输出延迟
TSB:寄存器 B 的建立时间
THB:寄存器 B 的保持时间
TCQB:寄存器 B 的时钟输出延迟
对于没有任何抖动的理想时钟,时钟信号同时到达两个寄存器块,假设寄存器A时钟到输出的延迟(TCQA)为0,寄存器B的数据建立保持时间(分别为TSB和THB)也为0,最大时钟频率F是通过组合逻辑的最大路径延迟的倒数,即:
Fmax = 1/Tperiod= 1/Tcomb
在实际的电路中,有许多其他的因素也会对时钟频率产生影响,如时钟偏移和抖动。
4.2.1 时钟偏移
在实际电路中,由于存在线路上的传播延迟,寄存器B的时钟输人(参考上图)相对于寄存器 A 可能会有一些延迟。
这些传播延迟中的微小差别,会发生在复杂数字产品的整个时钟网络上,最后会对整系统时序产生无法接受的影响。这种现象也称为“ 时钟偏移”。
在相邻两个寄存器的时钟延迟大于这两个寄存器之间的数据路径延迟时,就会产生负时钟偏移。在这种情况下,先到的时钟会引起竞争条件。即在数据还未成功锁存时时钟就触发了寄存器。时钟偏移倾向于增加电路所能承受的最大时钟频率。
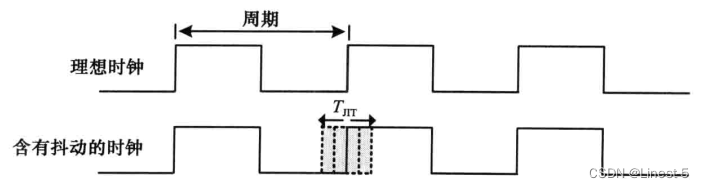
4.2.2 时钟抖动
到达电路中某一点的连续时钟边沿之间间隔的变化称为时钟抖动 tjit。
如下图所示,时钟抖动会影响时钟的占空比。让我们看看在实时电路中上述因素对最大时钟频率的影响。是典型的组合电路路径。粗体显示的路径(b、f、j、i、m、n和o)是两个寄存器之间最大延迟的路径。

算一下从寄存器“bf" 到输出“o” 之间精确的组合延迟。

按照上图,两个寄存器之间的路径b、f、j、l、m、n、o的总延迟为:
TFF= TCQ + TAND + TINV + TNOR + Tstp + TSKW + TJIT
TFF= TCQ + Tcombo + Tstp + TSKW + TJIT
因此对于给定电路使用下面的公式来计算最大周期:
{TFF}max = {TCQ + Tcombo + Tstp + TSKW + TJIT}max
假设设计中所有触发器的延迟相等( 实际情况不可能这样),那么得到:
{TFF}max = TCQ + Tstp + TSKW + TJIT + {Tcombo}max
上面等式中的组合延迟部分可以通过添加多个触发器来减少,因此增加了电路操作的最大频率。这种减少流水线各阶段组合延迟的方法能显著提升电路的吞吐率。
因此在实际的设计当中,应避免过长的组合逻辑语句,因为这样不会导致整个系统最大工作时钟的减小,可以用时序逻辑去截断组合逻辑来提升时序。
4.3 流水线
流水线使用存储器件将时钟周期内关键路径(最大组合延迟的路径)分割开来。这减少了关键路径上各阶段延迟并使电路能以更高频率工作。流水线电路增加了各时钟阶段的计算能力,但是由于使用了存储器单元也增加了负载。让我们来看一下图中执行这种操作的电路: .
i = (a + b + c + d) + (e + f + g + h)
计算下图中两个触发器之间的延迟( 最大路径延迟)。

有前面计算得
{TFF}max = TCQ + Tstp + TSKW + TJIT + {Tcombo}max
这里{Tcombo}max = 3Taddr
所以最终的时钟周期为
{TFF}max = TCQ + Tstp + TSKW + TJIT + {3Taddr}
假设有下列约束值
TCQ= 4FO4
Tstp= 2FO4
TSKW + TJIT= 4FO4
Taddr = 10FO4
这里FO4指4个反向器延迟的扇出。
将这些值代入上式中,得到
{TFF}max= 4 + 2 + 4 + 3 x 10 = 40FO4
现在让我们看一下同样的电路插入两级流水后的样子。新的流水线电路如下图所示。第一级流水线寄存器(图中长方形)加在第一次加法操作之后,其他流水线寄存器加在各阶段直至加法器最终的输出被锁存住。

现在计算其延时:
{TFF}max = TCQ + Tstp + TSKW + TJIT + {Tcombo}max
因为此时 {Tcombo}max = 1Taddr
所以
{TFF}max = TCQ + Tstp + TSKW + TJIT + Taddr = 4 + 2 + 4 + 1 x 10 =20FO4
注意:在任何两个寄存器之间现在只存在一个加法器,而不再是三个加法器。
在使用7个流水化加法器实现8输人加法之后( 如图6.8所示),吞吐率( 每个周期的计算次数)增加至每个时钟周期计算一次8输人之和。总延迟为3个时钟周期。
与使用单加法器进行上述计算相比,7个加法器意味着至少7倍的面积和功耗开销。将电路并行化对功耗和面积的影响都很大。一般来说,使用并行电路进行同样的k次操作,比重复使用某一逻辑k次达到同样的效果在面积和功耗方面的开支更大,因为使用了更多的触发器和额外逻辑,导致了更多的连线。
读书笔记汇总
边栏推荐
猜你喜欢

Pigsty:开箱即用的开源数据库发行版
C语言各种符号如何使用

v-for指令:根据数据生成列表结构
从宠爱到嫌弃,蒸发1500亿后,这家明星企业为何陨落?
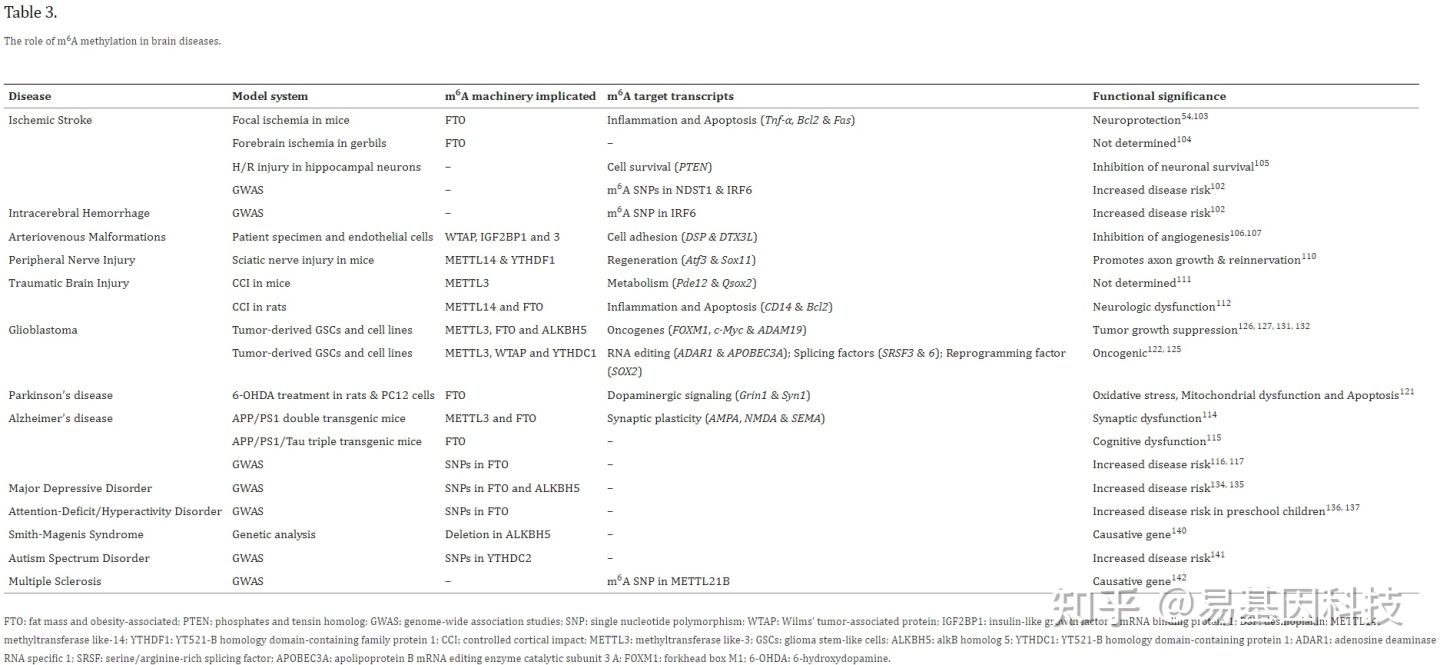
Yi Gene|In-depth review: epigenetic regulation of m6A RNA methylation in brain development and disease

MySQL的使用演示及操作,MySQL数据字符集的设置
找到一个超级神奇,百试百灵的解决 ModuleNotFoundError: No module named xxx 的方法

雷达人体存在感应器,人体感知控制应用,为客户提供真实的感知方案
v-show指令:切换元素的显示与隐藏

险资又做LP,一出手40亿
随机推荐
v-on补充:自定义参数传递和事件修饰符
【Windows】将排除项添加到安全中心以避免exe被系统自动删除
C专家编程 第10章 再论指针 10.6 使用指针从函数返回一个数组
需求骤降,成本激增,PC行业再次入冬
不爱生活的段子手不是好设计师|ONES 人物
Bitwarden:免费、开源的密码管理服务
C专家编程 第10章 再论指针 10.5 使用指针向函数传递一个多维数组
v-show指令:切换元素的显示与隐藏
FTXUI按键和ROS2 CLI组合使用笔记(turtlesim+teleop)
如何将jpg静图做成gif动图?教你1分钟快速合成gif
数据治理项目成功的要点,企业培养数据要把握好关键环节
异常处理的超详细讲解
Polling and the principle of webSocket and socket.io
阿里工作7年,肝到P8就剩这份学习笔记了,已助朋友拿到10个Offer
一种新的测试方法:视觉感知测试
易基因|深度综述:m6A RNA甲基化在大脑发育和疾病中的表观转录调控作用
Basic knowledge of software engineering--requirements analysis
在Istio中,到底怎么获取 Envoy 访问日志?
LeetCode-337. House Robber III
李斌带不动的长安新能源高端梦,华为和“宁王”能救吗?