当前位置:网站首页>TiSpark 原理之下推丨TiDB 工具分享
TiSpark 原理之下推丨TiDB 工具分享
2022-08-11 11:21:00 【InfoQ】
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它通过 Spark 提供的拓展机制与内置的 TiKV Client Java,在 Spark 之上直连 TiKV 进行读写,具有事务性读取、事务性写入与删除等能力。其中在事务性读取中基于 Spark Extension 实现了下推(详情可见
TiSpark 用户指南
)。
为了帮助读者更好地理解、运用 TiSpark,本文将详细介绍 TiSpark 中下推相关的知识,包括 Spark 中的下推含义,实现原理,及其拓展接口、TiSpark 下推策略和下推支持列表。
本文作者:
施宇航
,PingCAP 研发工程师。
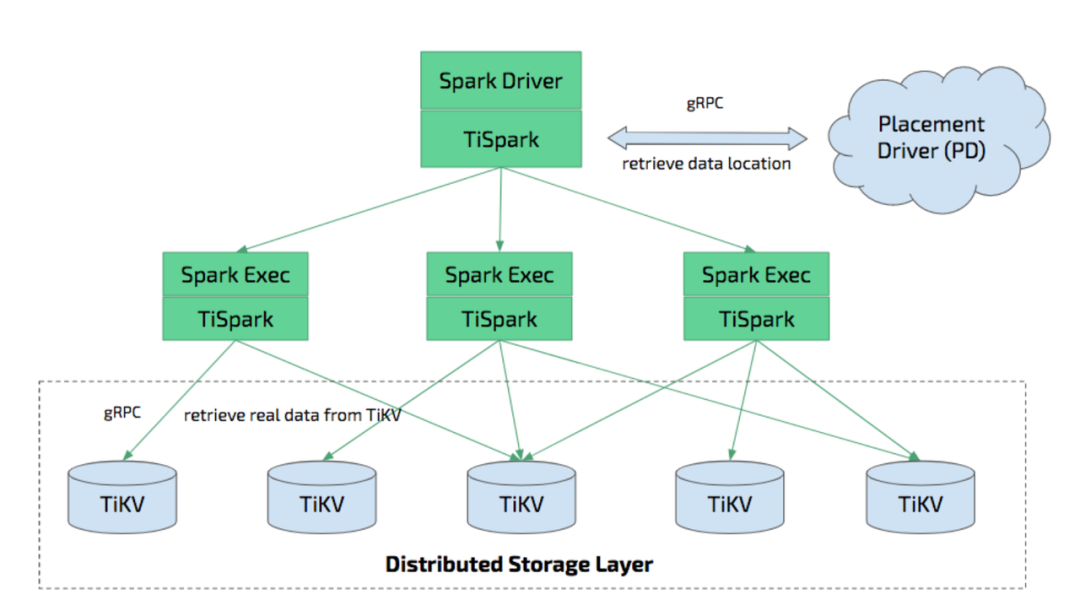
<center>TiSpark 架构图</center>
理解 Spark 的下推
TiSpark 本质是 Spark 的 connector,想要了解 TiSpark 是如何下推的必须先理解 Spark 中的下推。
了解 Spark SQL
首先简单了解一下 Spark SQL 的执行过程,这有助于理解下推原理的介绍。
Spark SQL 的核心是 Catalyst,它会依次进行 SQL 的解析,校验,优化,选择物理计划。最终生成可执行 RDD,交由 Spark Core 执行任务。
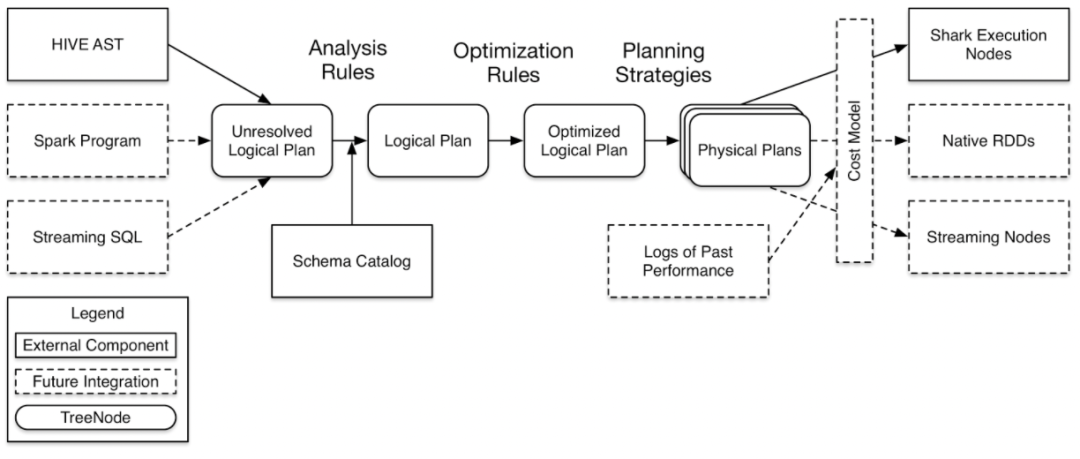
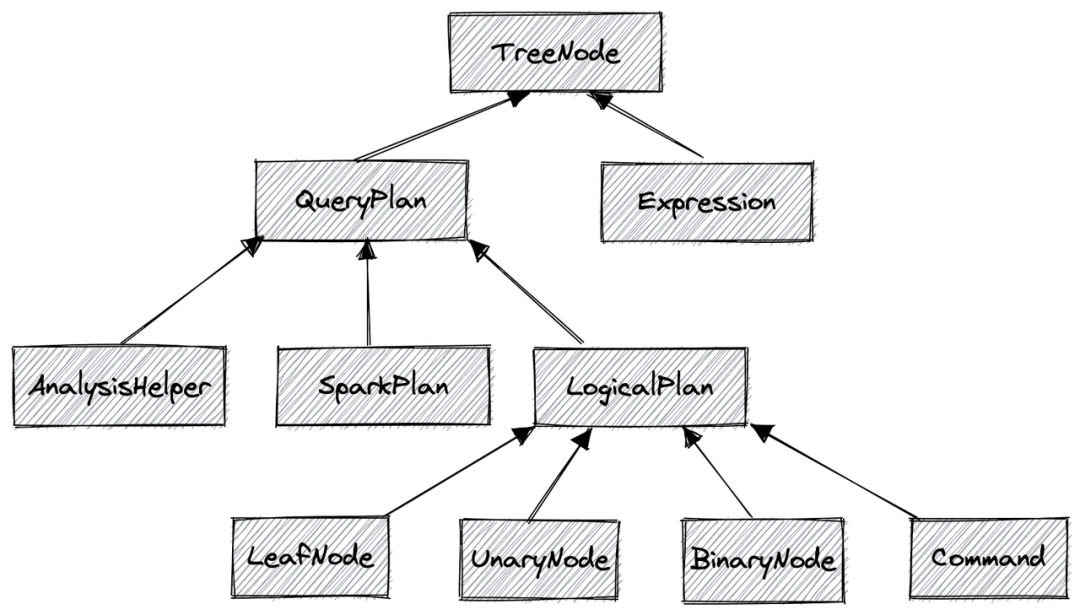
在这个过程中,Spark SQL 会被解析为一颗树。树的节点称为 TreeNode,它有多个实现类,可以用来表示逻辑计划树与物理计划树中各种类型的节点。这里不过多展开,我们只需要知道由 TreeNode 组成的一颗树可以表示一条 SQL:如过滤条件会被解析为 Filter 算子节点。
Spark 中的下推
下推是一种经典的 SQL 优化手段,它会尽量将一些算子推向靠近数据源的位置,以减少上层所需处理的数据量,最终达到加快查询速度的目的。常见的下推优化有:谓词下推,聚合下推,映射下推。
在分布式计算引擎 Spark 中,下推的含义如出一辙,但需要注意在 Spark 中其实有两步下推优化:
- 逻辑计划优化阶段:会尽量将算子推向靠近数据源的方向,但不会推向数据源
- 物理计划生成阶段:将算子推到数据源,Spark 可能不会再处理该算子
举个例子,考虑如下 SQL:
select * from A join B on A.id = B.id where A.a>10 and B.b<100;
上文提到 SQL 会被解析为一颗逻辑计划树
- filter 表示 where 条件
- join 表示 join 操作
- scan_a 与 scan_b 表示从数据源 A,B 表拉取数据
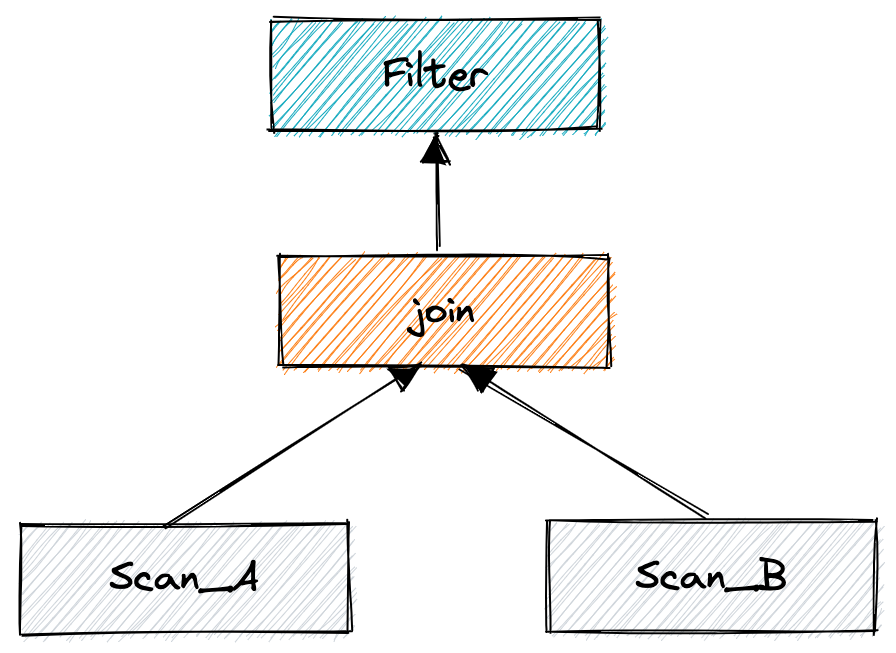
第一步:在逻辑计划下推优化后,过滤条件会被下推到更靠近数据源的位置,这样 join 所需处理的数据就会更少
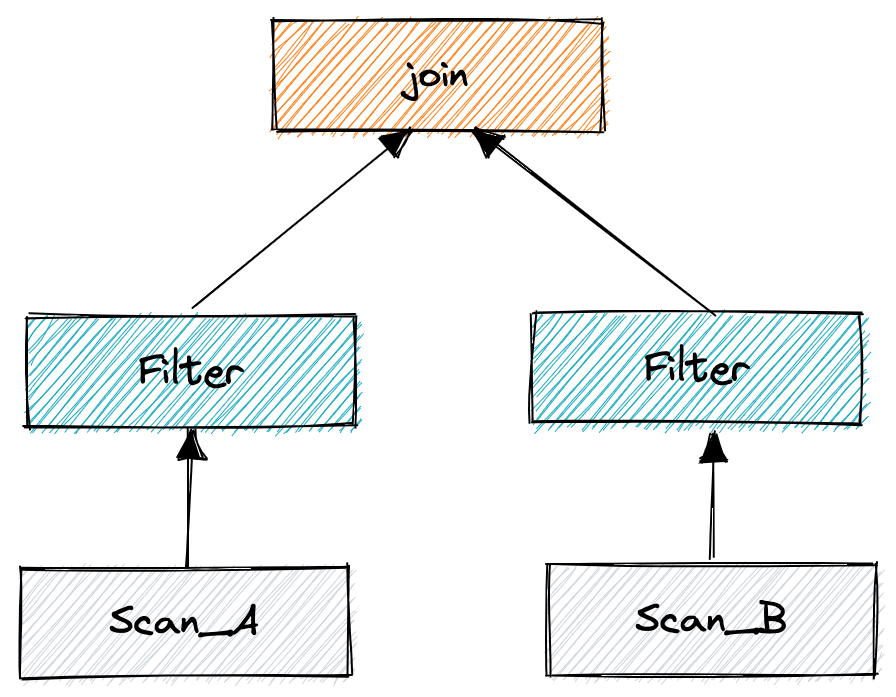
对应的 SQL 可如下表示:
select * from (select * from A where A.a>10) a join (select * from B where B.b<100) b on a.id = b.id
第二步:在物理计划生成时,过滤条件还可能被彻底下推到数据源。也就是说 Spark 无需处理 Filter 了,数据源返回就已完成过滤。
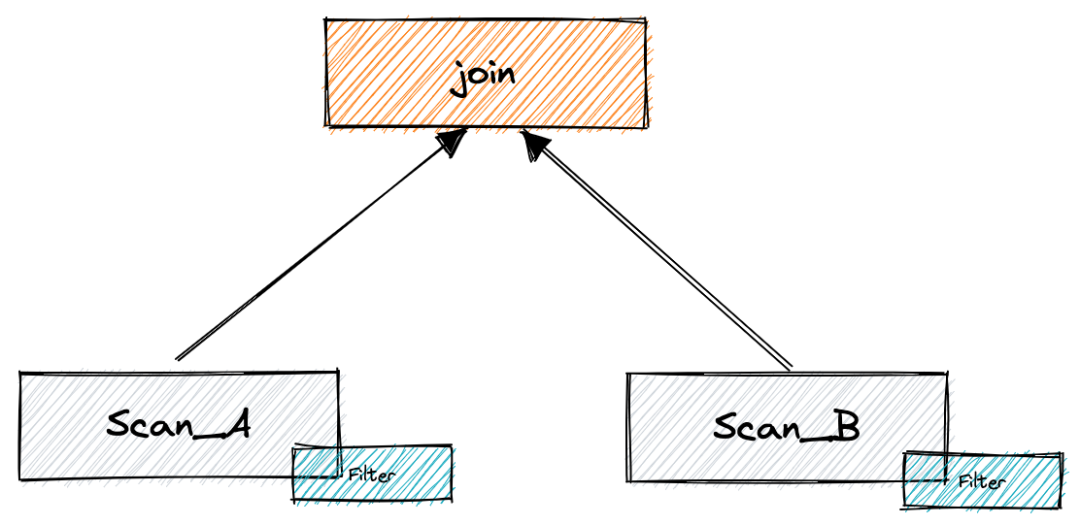
Spark 下推原理
该小节代码基于 Spark 3.2
逻辑计划下推优化
Spark 首先会在逻辑计划优化时进行下推优化。
在 Catalyst 的逻辑计划优化阶段,会应用各种优化规则,其中就包括了下推优化的规则。这里就对应了上文所说的逻辑计划层的下推优化。以谓词下推优化
PushDownPredicates 为例
object PushDownPredicates extends Rule[LogicalPlan] with PredicateHelper {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
CombineFilters.applyLocally
.orElse(PushPredicateThroughNonJoin.applyLocally)
.orElse(PushPredicateThroughJoin.applyLocally)
}
}
CombineFilters 用于合并过滤条件。PushPredicateThroughNonJoin 和 PushPredicateThroughJoin 则用于分别处理不包含 join 和包含 join 时的谓词下推。由于这部分下推不是本文重点,我们不再赘述其具体实现,感兴趣的同学可以直接参考
Spark 源码
。
物理计划下推数据源
在完成逻辑计划阶段的下推优化后,Spark 会基于下推结果,在生成物理计划时再进行下推数据源的优化。TiSpark 主要涉及此时的下推,我们重点阐述这部分的原理。
下推接口
在 Spark 中,提供了 DataSource API 接口用于拓展数据源,其中包含了下推接口用于指定需要下推到数据源的算子。以 Spark 3.2.1 的谓词下推为例,其接口如下:
@Evolving
public interface SupportsPushDownFilters extends ScanBuilder {
Filter[] pushFilters(Filter[] filters);
Filter[] pushedFilters();
}
- Filter[] pushFilters(Filter[] filters):入参是从 Catalyst expression 解析来的所有过滤条件,它是经过了第一步逻辑计划优化之后的结果。出参是 Spark 无法下推到数据源的过滤条件,被称为 postScanFilters
- Filter[] pushedFilters():出参是能下推到数据源的过滤条件,被称为 pushedFilters
其中 postScanFilters 和 pushedFilters 中允许有相同的 filter,此时数据源和 Spark 都会进行过滤操作。在 Spark 中
parquet row group filter 就是有相同 filter 的一个例子
下推原理
那么当我们实现该接口,Spark 又是如何运作的呢?我们可以简单将其归纳为两步:
- 第一步:根据此接口,保留无法下推到数据源的 Filter
- 第二步:根据此接口,最终生成物理计划时,在获取数据源数据的 Scan 算子中处理下推部分的 Filter。这一步中,由于不同的数据源会有不同处理,当我们自定义拓展数据源时,一般由我们自己实现。
先来看第一步,第一步发生在 catalyst 的优化阶段,由 V2ScanRelationPushDown 完成。
其简化过的核心代码如下:
object V2ScanRelationPushDown extends Rule[LogicalPlan] with PredicateHelper {
import DataSourceV2Implicits._
def apply(plan: LogicalPlan): LogicalPlan = {
applyColumnPruning(pushDownAggregates(pushDownFilters(createScanBuilder(plan))))
}
private def pushDownFilters(plan: LogicalPlan) = plan.transform {
case Filter(condition, sHolder: ScanBuilderHolder) =>
val (pushedFilters, postScanFiltersWithoutSubquery) = PushDownUtils.pushFilters(
sHolder.builder, normalizedFiltersWithoutSubquery)
val filterCondition = postScanFilters.reduceLeftOption(And)
filterCondition.map(Filter(_, sHolder)).getOrElse(sHolder)
}
在 apply 方法中会应用各种下推,其中包含谓词下推 pushDownFilters。
而在 pushDownFilters 中会依赖 PushDownUtils 分别获取到 pushedFilters 与 postScanFilters。最终返回的逻辑计划中只会包含 postScanFilters。
PushDownUtils 简化过的核心代码如下:
object PushDownUtils extends PredicateHelper {
def pushFilters(
scanBuilder: ScanBuilder,
filters: Seq[Expression]): (Seq[sources.Filter], Seq[Expression]) = {
scanBuilder match {
case r: SupportsPushDownFilters =>
val postScanFilters = r.pushFilters(translatedFilters.toArray).map { filter =>
DataSourceStrategy.rebuildExpressionFromFilter(filter, translatedFilterToExpr)
}
(r.pushedFilters(), (untranslatableExprs ++ postScanFilters).toSeq)
case _ => (Nil, filters)
}
}
}
pushFilters 方法负责处理谓词下推,其实现很简单:匹配上 SupportsPushDownFilters 接口,然后根据我们的具体实现获取到 pushedFilters 与 postScanFilters。如果没有实现,则 pushedFilters 为空表示无需下推。
第二步数据源不同其实现也不同,我们以 JDBC 数据源为例。
首先是 JDBCScanBuilder 的 build 方法
override def build(): Scan = {
val resolver = session.sessionState.conf.resolver
val timeZoneId = session.sessionState.conf.sessionLocalTimeZone
val parts = JDBCRelation.columnPartition(schema, resolver, timeZoneId, jdbcOptions)
JDBCScan(JDBCRelation(schema, parts, jdbcOptions)(session), finalSchema, pushedFilter,
pushedAggregateList, pushedGroupByCols)
}
该方法会以 pushedFilter 为参数返回 Scan 的实现类 JDBCScan
case class JDBCScan(
relation: JDBCRelation,
prunedSchema: StructType,
pushedFilters: Array[Filter],
pushedAggregateColumn: Array[String] = Array(),
groupByColumns: Option[Array[String]]) extends V1Scan {
override def toV1TableScan[T <: BaseRelation with TableScan](context: SQLContext): T = {
new BaseRelation with TableScan {
override def buildScan(): RDD[Row] = {
val columnList = if (groupByColumns.isEmpty) {
prunedSchema.map(_.name).toArray
} else {
pushedAggregateColumn
}
relation.buildScan(columnList, prunedSchema, pushedFilters, groupByColumns)
}
}.asInstanceOf[T]
}
}
JDBCScan 会调用 relation.buildScan,该方法最终会返回 JDBCRDD
private[jdbc] class JDBCRDD(
sc: SparkContext,
getConnection: () => Connection,
schema: StructType,
columns: Array[String],
filters: Array[Filter],
partitions: Array[Partition],
url: String,
options: JDBCOptions,
groupByColumns: Option[Array[String]])
extends RDD[InternalRow](sc, Nil) {
private val filterWhereClause: String =
filters
.flatMap(JDBCRDD.compileFilter(_, JdbcDialects.get(url)))
.map(p => s"($p)").mkString(" AND ")
}
在 JDBCRDD 中,Filter 会在 filterWhereClause 中被解析为 SQL 的 Where 条件,最终以完整 SQL 的形式请求兼容 MySQL 协议的数据源。
至此,JDBC 数据源实现了对下推 Filter 的处理。那么在 Spark 中,是如何衔接上 JDBCRDD 的呢?
这就发生 catalyst planner 阶段中的 DataSourceV2Strategy 策略中。其简化核心代码如下:
class DataSourceV2Strategy(session: SparkSession) extends Strategy with PredicateHelper {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(project, filters,
DataSourceV2ScanRelation(_, V1ScanWrapper(scan, pushed, aggregate), output)) =>
val v1Relation = scan.toV1TableScan[BaseRelation with TableScan](session.sqlContext)
val rdd = v1Relation.buildScan()
val unsafeRowRDD = DataSourceStrategy.toCatalystRDD(v1Relation, output, rdd)
val dsScan = RowDataSourceScanExec(
output,
output.toStructType,
Set.empty,
pushed.toSet,
aggregate,
unsafeRowRDD,
v1Relation,
tableIdentifier = None)
withProjectAndFilter(project, filters, dsScan, needsUnsafeConversion = false)
case PhysicalOperation(project, filters, DataSourceV2ScanRelation(_, scan: LocalScan, output))
case PhysicalOperation(project, filters, relation: DataSourceV2ScanRelation)
case PhysicalOperation(p, f, r: StreamingDataSourceV2Relation)
case PhysicalOperation(p, f, r: StreamingDataSourceV2Relation)
在该策略中,Spark 会匹配 PhysicalOperation 算子,由于有多种 Scan ,因此这里会有多种匹配。由于 JDBC 数据源实现的是 V1Scan,这里就会进入到第一个匹配。
在该匹配中会调用 toV1TableScan 获取到 JDBCRDD,并在 RowDataSourceScanExec 中执行获取数据的操作。
最后返回的 withProjectAndFilter 只是将 RowDataSourceScanExec 拼接到整个物理计划中返回。
基于此,Spark 完成了数据源的下推,并提供了一套封装好的接口用于实现外部数据源的下推。
理解 TiSpark 的下推
注意:TiSpark 的下推是指下推到数据源,TiSpark 不会对逻辑计划中的下推优化有任何改动。下文涉及到的下推都是指下推到数据源。
TiSpark 下推策略
那么对 TiSpark 来说,一个算子是否要下推?我们从两方面讨论
是否需要下推
一般来说,下推可以获得更好的速度与性能,但这在大数据量的 OLAP 场景中不是绝对的:假设你的 Spark 资源非常充裕,而作为 TiSpark 数据源的 TiKV 压力较大,如果还进行下推特别是消耗资源较大的聚合下推,反而会使得整体执行速度降低,转而将压力放到资源充分的 Spark 则是更合理的选择。因此对于一些资源消耗大的算子,我们应该由实际情况决定是否下推。对于此 TiSpark 提供了一些可配置的参数
- spark.tispark.plan.allow_agg_pushdown:用于指定是否允许下推聚合操作,当 TiKV 压力过大时可以选择配置此参数
- spark.tispark.plan.unsupported_pushdown_exprs:提供更精细的配置,用户可以通过配置禁止相应表达式被下推。当你不想下推或是你使用的是非常老的 TiKV 版本(某些表达式无法下推),那么可以选择配置此参数。
能否被下推
算子不总是能下推,可能某些表达式,类型就会无法下推。这里的限制来源于两个方面:Spark 本身不支持,TiKV 不支持。两者的并集即是最终无法下推的。对于此 TiSpark 会自动基于 Spark 与 TiKV 的能力决定是否下推,无需用户选择。
TiSpark 下推原理
上文讲到 Spark 提供了 DataSource API 用于拓展数据源实现下推。但实际上它并不能满足 TiSpark 的下推需求,它存在如下问题:
- DataSource API V1 时期下推接口设计糟糕:假设原来有 limitscan,prunedscan,limitprunedscan 三种下推接口。那么当要支持新的下推算子 filter 时,就需要新增 filterscan,filterlimitscan,filterprunedscan,filterlimitprunedscan 四个接口。
- 下推能力受限:即使是在 Spark 3.0 中的 DataSource API V2,也只支持谓词下推与列裁剪下推。在最近的 Spark 3.2/3.3 中才陆续支持了聚合下推,Limit 下推等能力
- 下推策略不灵活:有些下推是要综合考虑各种算子的。比如 Avg 实际就是 Sum/Count,只要这两个算子可以下推理论上我们也可以下推 Avg,但 DataSource API 却无法支持
回顾 Spark 下推的实现原理。其实就是在 Spark 逻辑计划中摘除相应算子,然后在执行物理计划时应用到数据源中。其问题在于 DataSource API 的框架使得下推能力被大大限制。那么如果我们不使用 DataSource API,同时使用类似修改物理计划的方式去进行数据源下推不就可以了吗?
TiSpark 的确是这么做的。在 Spark 2.2 时支持了 catalyst extension 了,它能以拓展点的方式在 catalyst 的各阶段插入自定义规则或策略。TiSpark 就是基于 catalyst extension 实现了一套下推策略。
数据源下推需要修改物理计划,从逻辑计划转换为物理计划发生在 planner 阶段。相应的 TiSpark 就需要去实现该阶段的拓展点,其接口如下:
def injectPlannerStrategy(builder: StrategyBuilder): Unit = {
plannerStrategyBuilders += builder
}
以下代码基于 Spark 3.2.1 TiSpark 3.0.1
TiSpark 对该拓展点的实现如下:
e.injectPlannerStrategy(new TiStrategyFactory(getOrCreateTiContext))
class TiStrategyFactory(getOrCreateTiContext: SparkSession => TiContext)
extends (SparkSession => Strategy) {
override def apply(sparkSession: SparkSession): Strategy = {
TiExtensions.validateCatalog(sparkSession)
ReflectionUtil.newTiStrategy(getOrCreateTiContext, sparkSession)
}
}
其中 ReflectionUtil 可以利用反射,基于 Spark 版本返回对应的 TiStrategy。这是为了解决多版本 Spark 之间的源代码不兼容问题,我们重点来看 TiStrategy 的实现:
case class TiStrategy(getOrCreateTiContext: SparkSession => TiContext)(sparkSession: SparkSession)
extends Strategy with Logging {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = {
plan
.collectFirst {
case DataSourceV2ScanRelation(DataSourceV2Relation(table: TiDBTable, _, _, _, _), _, _) =>
doPlan(table, plan)
}
.toSeq
.flatten
}
}
该方法会去尝试匹配 TiDBTable ,如果出现 TiDBTable 那么就表示数据源为 TiDB,就会执行 doPlan 方法应用我们自定义的策略。反之,我们不做任何操作避免影响其他数据源的执行计划。再来深入到 doPlan 方法中(简化代码):
private def doPlan(source: TiDBTable, plan: LogicalPlan): Seq[SparkPlan] =
plan match {
case PhysicalOperation(
projectList,
filters,
DataSourceV2ScanRelation(
DataSourceV2Relation(source: TiDBTable, _, _, _, _),
_,
_)) =>
pruneFilterProject(projectList, filters, source, newTiDAGRequest()) :: Nil
case TiAggregation(
groupingExpressions,
aggregateExpressions,
resultExpressions,
TiAggregationProjectionV2(filters, _, `source`, projects))
if isValidAggregates(groupingExpressions, aggregateExpressions, filters, source) =>
case _ => Nil
}
该策略其实在模仿 Spark 下推原理章节中提到的 DataSourceV2Strategy 策略。
在该下推策略中,我们基于模式匹配,识别出能够进行下推的 Spark 算子,分别执行各种下推逻辑。以谓词下推进行举例:谓词下推会匹配 PhysicalOperation ,并执行 pruneFilterProject 方法:
private def pruneFilterProject(
projectList: Seq[NamedExpression],
filterPredicates: Seq[Expression],
source: TiDBTable,
dagRequest: TiDAGRequest): SparkPlan = {
val (pushdownFilters: Seq[Expression], residualFilters: Seq[Expression]) =
filterPredicates.partition((expression: Expression) =>
TiExprUtils.isSupportedFilter(expression, source, blocklist))
val residualFilter: Option[Expression] =
residualFilters.reduceLeftOption(catalyst.expressions.And)
filterToDAGRequest(tiColumns, pushdownFilters, source, dagRequest)
val scan = toCoprocessorRDD(source, projectSeq, dagRequest)
residualFilter.fold(scan)(FilterExec(_, scan))
}
- 首先 TiExprUtils.isSupportedFilter 方法会将 filter 表达式 转换为 TiKV 表达式,然后根据具体的表达式与类型判断是否可以下推。可以下推的被放在 pushdownFilters 中,不可以下推的被放在 residualFilter 中。
- 然后 filterToDAGRequest 方法会基于可下推的 filter 构建请求 TiKV 的参数。最终由 toCoprocessorRDD 方法返回一个可获取源数据的物理计划。
- 最后该物理计划会由 FilterExec 包装执行,同时还需要在其上层应用无法下推的 residualFilter 算子。
这样就完成了 Filter 的下推,类似的 TiSpark 还支持了常见的聚合下推,limit 下推,order by 下推。
TiSpark 下推参照表
TiSpark 目前能够支持谓词下推,聚合下推,limit 下推,order by 下推,但有些类型无法下推,其支持情况如下表:
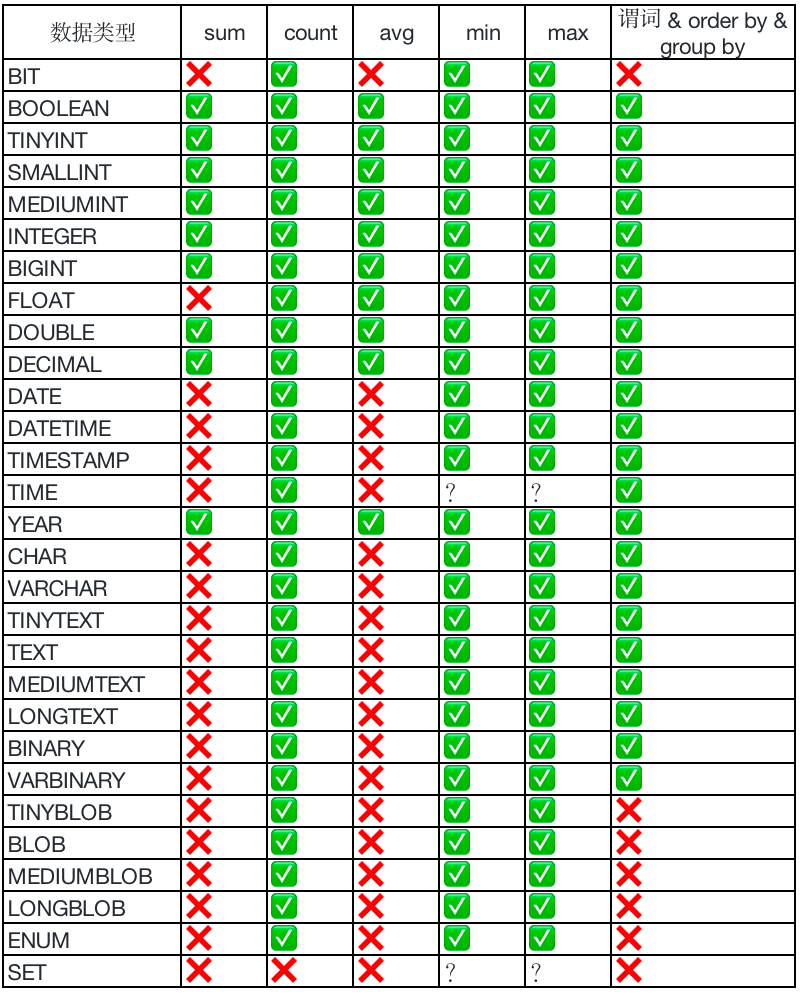
目前 2022/07/11:
- min/max(time) 下推有错误的结果,min/max(set) 下推可能导致 TiKV panic
- 谓词下推不支持对 NULL 进行过滤
在 TiSpark 中,可以通过 explain 判断是否被下推,举个例子:
- 创建 TiDB 表
CREATE TABLE `test`.`t` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
);
- 执行查询语句
spark.sql("select avg(id) from test.t where id > 10").explain
- 查看执行计划,重点关注 TiKV CoprocessorRDD
RangeFilter: [[[email protected] GREATER_THAN 10]]:表明 id>10 被下推
Aggregates: Sum([email protected]), Count([email protected]): 表明 Sum 和 Count 被下推,他们会最终被处理为 Avg
*(2) HashAggregate(keys=[], functions=[specialsum(specialsum(id#252L, DecimalType(38,0), null)#258, DecimalType(38,0), null), specialsum(count(id#252L)#259L, LongType, 0)])
+- Exchange SinglePartition, true, [id=#38]
+- *(1) HashAggregate(keys=[], functions=[partial_specialsum(specialsum(id#252L, DecimalType(38,0), null)#258, DecimalType(38,0), null), partial_specialsum(count(id#252L)#259L, LongType, 0)])
+- *(1) ColumnarToRow
+- TiKV CoprocessorRDD{[table: t] IndexReader, Columns: [email protected]: { IndexRangeScan(Index:primary(id)): { RangeFilter: [[[email protected] GREATER_THAN 10]], Range: [([t\200\000\000\000\000\000\000o_i\200\000\000\000\000\000\000\001\003\200\000\000\000\000\000\000\v], [t\200\000\000\000\000\000\000o_i\200\000\000\000\000\000\000\001\372])] }, Aggregates: Sum([email protected]), Count([email protected]) }, startTs: 434873744501506049}
展望
TiSpark 通过劫持执行计划的方式具有如下优点:
- 不会被 DataSource API 限制下推能力;
- 我们只添加了足够薄的一层,使得完全不影响 Spark SQL 的执行计划以及其他数据源的执行流程。
但同时,他也带来了一定问题:
- 代码复杂度增加;
- 插入自定义策略的时要时刻注意不影响 Spark 原有逻辑;
- 需要深入 Spark Catalyst 触碰到一些正在发展中的接口,这意味着不稳定。
随着 Spark DataSource API 的发展,其下推能力也在不断完善:Spark 3.2 支持了聚合下推,Spark 3.3 支持了 Limit 下推并增强了整体下推的能力。希望在不远的将来,TiSpark 能将下推逻辑部分甚至全部切换到 DataSource API。以减少对执行计划的侵入并提高代码的可读性。
边栏推荐
猜你喜欢



随机推荐
rem如何使用
2022-08-10北京华为OD机试真题分享
centos linux 下安装mysql 8.0
阿里内网疯传的P8“顶级”分布式架构手册被我拿到了
chrome插件开发入门-保姆级攻略
齐话存储未来,诠释分布式缘起
scala 高级
【毕业设计】远程智能浇花灌溉系统 - stm32 单片机 嵌入式 物联网
或命名“狙击手” 长安全新皮卡申报图
I got the P8 "top" distributed architecture manual that went viral on Ali's intranet
C# 调用高德地图API获取经纬度以及定位【万字详解附完整代码】
鸿海董事长刘扬伟:市场对智能手机和其他消费电子产品的需求正在放缓
LeetCode · Question of the Day · 1417. Reformatting String · Simulation
阿里云 Hologres助力好未来网校实时数仓降本增效
HTM5学习:第一阶段02
数据库导出的csv文件纯数字被转为科学计数法
五分钟教你内网穿透
App Clip 苹果小程序开发须知
Web3 Entrepreneur's Guide: How to Build a Decentralized Community for Your Product?
Go-Excelize API源码阅读(七)—— CopySheet(from, to int)