当前位置:网站首页>李沐d2l(十)--卷积层Ⅰ
李沐d2l(十)--卷积层Ⅰ
2022-08-11 05:36:00 【madkeyboard】
文章目录
一、从全连接到卷积
1 全连接层
- 将输入和输出变形为矩阵(宽度,高度)
- 将权重变形为4-D张量(h,w)到(h’, w’)
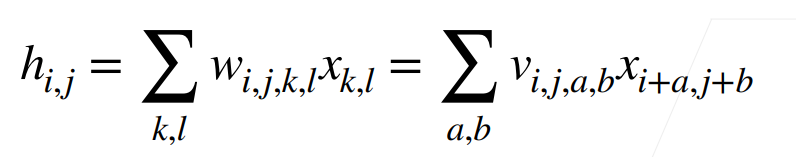
- V是W的重新索引 vi,j,a,b = wi,j,i+a,j+b
2 平移不变性
由下面公式可知,x的平移会导致h的平移,但是我们希望当x变换时(也就是i和j变换)不应该影响到V,简单的说就是V不能依赖于(i,j)。
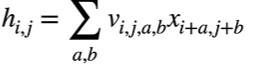
我们可以加一个限制让 vi,j,a,b = va,b ,这样当i和j随便变换时也不会影响到v。
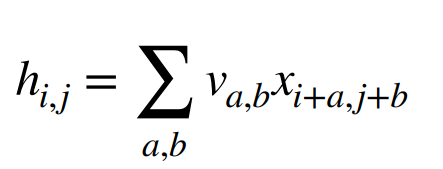
3 局部性
在评估hi,j 时,我们不应该使用远离xi,J 的参数。因此我们可以加一个限制:当|a|,|b| > Δ 时,使得va,b = 0
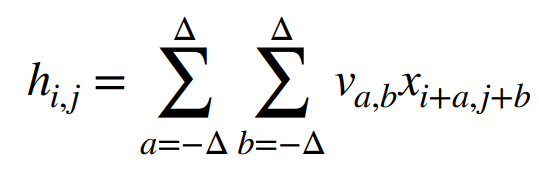
总结
对全连接层使用平移不变性和局部性就能得到卷积层
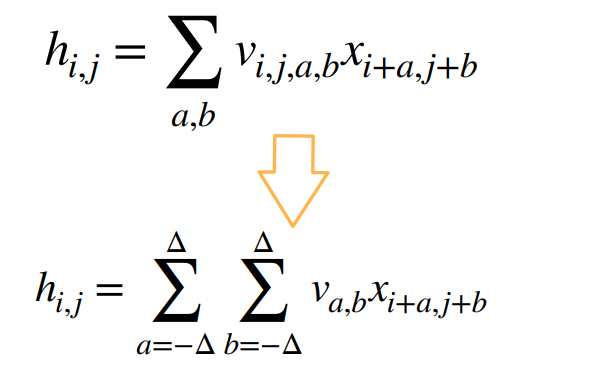
二、卷积层
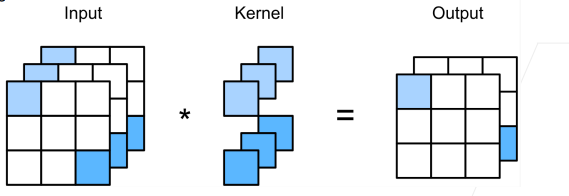
1 二维交叉相关
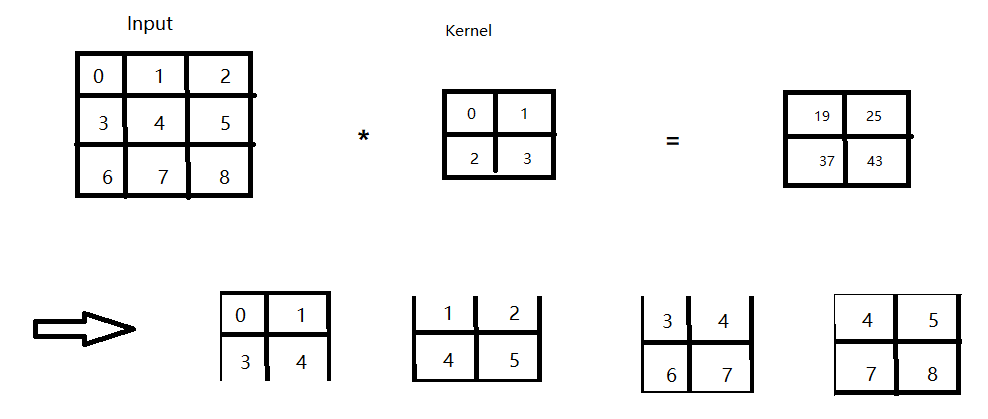
2 二维卷积层
- 输入X: nh x nw
- 核W:kh x kw (就是Kernel)
- 偏差b∈R
- 输出Y:(nh - kh + 1) x (nw - kw + 1) (输出会变小是因为在做二维交叉相关时,比如从左为右移动到右边界,只含有元素2和5,这时就会被舍弃。)
- Y = X * W + b(这儿的*就是二维交叉相关)
3 比较
两者的区别在W中,a和b是相反数,这在实际使用中没有区别
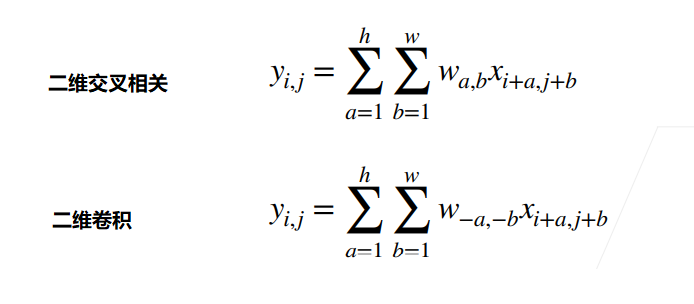
总结
- 卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出
- 核矩阵和偏移是可学习的参数
- 核矩阵的大小是超参数
4 代码
定义
# 定义二维交叉函数
def corr2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
# 实现二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super.__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
例子:检测图片不同颜色的边缘
从结果可以看出第二列和倒数第二列的值都不为0,所有这里就是颜色不同的边缘
X = torch.ones((6,8))
X[:,2:6] = 0
K = torch.tensor([[1.0, -1.0]]) # 如果颜色相同结果是0,否则表示颜色不同
Y= corr2d(X, K)
print(Y)
''' tensor([[ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.], [ 0., 1., 0., 0., 0., -1., 0.]]) '''
由于我们输入的K是一维,所以只能检测垂直方向。
学习由X生成Y的卷积核
conv2d = nn.Conv2d(1, 1, kernel_size=(1, 2), bias=False)
X = torch.ones((6,8))
X[:,2:6] = 0
K = torch.tensor([[1.0, -1.0]]) # 如果颜色相同结果是0,否则表示颜色不同
Y= corr2d(X, K)
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
for i in range(50):
Y_hat = conv2d(X)
l = (Y_hat - Y)**2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'batch {
i+1}, loss {
l.sum():.3f}')
print(conv2d.weight.data.reshape((1,2))) #学习到的Kernel tensor([[ 1.0000, -1.0000]])
三、填充与步幅
1 填充
为什么需要填充
考虑这样一个问题,给定一个(32 x 32)的输入图像,应用(5 x 5)大小的卷积核,那么在一层的输出就会减少4。第一层得到输出的大小为28 x 28;第7层得到的大小为4 x 4。
所以如果卷积核越大就能更快地减少输出,但是如果我们不想减少,就需要进行填充。
如何进行填充
在输入周围添加额外的行/列。
如下图,在原输入周围添上0,得到输出甚至比原输入还大。
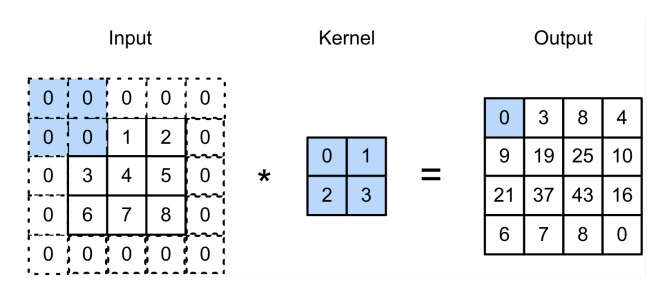
ph 表示填充行 = kh - 1
pw 表示填充列 = kw - 1
当kh 为奇数时:在上下两侧填充ph / 2
当kh 为偶数时:在上侧填充[ph / 2](这里是向上取整),在下侧填充[ph / 2] (这里是向下取整)填充后的输出形状如下
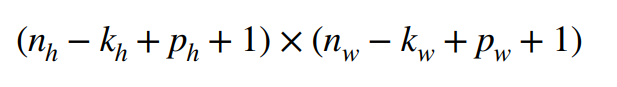
ph 和pw 这样取值的好处是保证输出和输入的形状相同。
2 步幅
为什么需要步幅
当我们输入一个224 x 224的图片,在使用5 x 5卷积核的情况要55层( (224 - 4) / (5 - 1))才能将输出降低到4 x 4。如果我们想要快速得到较小的输出,就需要使用步幅。
怎么进行步幅
步幅就是指行/列的滑动步长。之前我们进行卷积核的时候,默认的步幅是高度为1宽度为1,我们就可以更改步幅的大小来快速得到较小结果的输出。
下面看一个步幅高度为3, 宽度为2的例子。
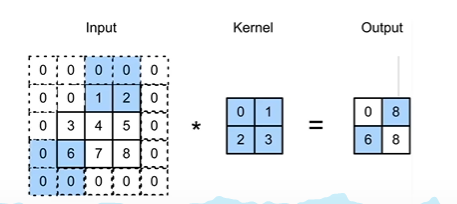
因此,如果给定高度为sh 和宽度为 sw 的步幅,输出的形状如下。
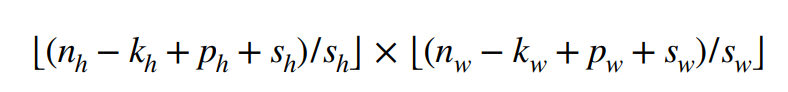
如果ph = kh - 1 pw= kw - 1
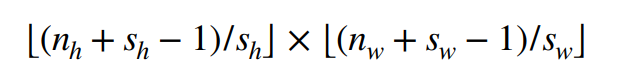
如果输入高度和宽度可以被步幅整除
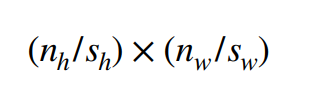
总结
- 填充和步幅都是卷积层的超参数
- 填充是在输入周围天剑额外的行/列,来控制输出减少量
- 步幅是每次滑动核窗口时的行/列的步长,可以成倍的减小输出大小。
3 代码
填充
# 1相同的高宽
def comp_conv2d(conv2d, X):
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
return Y.reshape(Y.shape[2:])
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1) # ph = 1 pw = 1
X = torch.rand(size=(8, 8))
print(comp_conv2d(conv2d, X).shape) # torch.Size([8, 8])
# 2不同的高宽
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
print(comp_conv2d(conv2d, X).shape) # torch.Size([8, 8])
步幅
kh = 3,ph= kh - 1 = 2,sh = 2, nh = 8
所以输出 = (8 - 3 + 2 + 2) / 2 = 4.5 (向下取整) = 4
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
print(comp_conv2d(conv2d, X).shape) # torch.Size([4, 4])
kh = 3 ph = 0 sh = 3 nh = 8
输出 = (8 - 3 + 20+ 3) / 3 = 2 (向下取整)kw = 5 pw = 1 sw = 4 nw = 8
输出 = (8 - 5 + 1 + 4) / 4 = 2
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
print(comp_conv2d(conv2d, X).shape) # torch.Size([2, 2])
四、多输入和多输出通道
1 多个输入通道
每个通道都有一个卷积核,结果就是所有通道卷积结果的和

- 输入X:ci x nh x nw
- 输出W:ci x kh x kw
- 输出Y:mh x mw
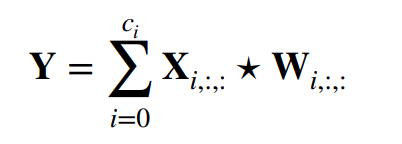
2 多个输出通道
无论有多少输入通道,目前为止只用到单输出通道。但是我们可以有多个三维卷积核,让每个核生成一个输出通道
- 输入X:ci x nh x nw
- 输出W:co x ci x kh x kw
- 输出Y:co x mh x mw

3 1 x 1卷积层
不识别空间模式,只融合通道。相当于输入形状为nh nw x ci ,权重为co x ci 的全连接层。
4 二维卷积层
- 输入X:cI x nh x nw
- 核W:co x ci x kh x kw
- 偏差B:co x ci
- 输出Y:co x mh x mw
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uaP6cNQw-1660120418598)(https://s2.loli.net/2022/08/10/ijeaQmJbYCXnVt4.png)]
总结
- 输出通道数是卷积层的超参数
- 每个输入通道有独立的二维卷积核,所有通道结果相加得到一个输出通道结果
- 每个输出通道有独立的三维卷积核。
5 代码
多输入通道互相关函数
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
print(corr2d_multi_in(X, K))
''' tensor([[ 56., 72.], [104., 120.]]) '''
多个通道的输出的互相关函数
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
K = torch.stack((K, K + 1, K + 2), 0)
print(K.shape)
print(corr2d_multi_in_out(X, K))
''' torch.Size([3, 2, 2, 2]) tensor([[[ 56., 72.], [104., 120.]], [[ 76., 100.], [148., 172.]], [[ 96., 128.], [192., 224.]]]) '''
1 x 1卷积
def corr2d_multi_in(X, K):
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
print(Y1)
print(Y2)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
''' tensor([[[-2.0720, -2.6179, 0.2528], [ 3.1700, 1.9594, 3.2119], [ 0.7149, 1.7988, -5.8433]], [[ 0.8412, 1.8544, -2.2386], [ 1.8311, -1.2274, -1.5514], [-0.3987, -1.0444, 0.1570]]]) tensor([[[-2.0720, -2.6179, 0.2528], [ 3.1700, 1.9594, 3.2119], [ 0.7149, 1.7988, -5.8433]], [[ 0.8412, 1.8544, -2.2386], [ 1.8311, -1.2274, -1.5514], [-0.3987, -1.0444, 0.1570]]]) '''
边栏推荐
猜你喜欢


随机推荐
强烈推荐一款好用的API接口
抖音分享口令url API工具
HCIP BGP建邻、联邦、汇总实验
MySQL之函数
Implement general-purpose, high-performance sorting and quicksort optimizations
Xshell如何连接虚拟机
姿态解算-陀螺仪+欧拉法
一个小时快速熟悉MySQL基本用法
Pinduoduo api interface application example
HCIP实验(pap、chap、HDLC、MGRE、RIP)
快速了解集成学习
HCIP--交换基础
[损失函数]——均方差
Eight-legged text of mysql
The ramdisk practice 1: the root file system integrated into the kernel
HCIP OSPF/MGRE Comprehensive Experiment
torch.cat()用法
八股文之redis
MySQL01
Class definition, class inheritance, and the use of super