当前位置:网站首页>Mysql index, transaction and storage engine
Mysql index, transaction and storage engine
2022-08-10 17:49:00 【small glimmer】
一、索引介绍
1、数据库索引
- 是一个排序的列表,存储着索引值和这个值所对应的物理地址
- 无须对整个表进行扫描,通过物理地址就可以找到所需数据
- 是表中一列或者若干列值排序的方法
- 需要额外的磁盘空间
2、索引的作用
- 数据库利用各种快速定位技术,能够大大加快查询速率
- 当表很大或查询涉及到多个表时,可以成千上万倍地提高查询速度
- 可以降低数据库的IO成本,并且还可以降低数据库的排序成本
- 通过创建唯一性索引保证数据表数据的唯一性
- 可以加快表与表之间的连接
- 在使用分组和排序时,可大大减少分组和排序时间
索引的副作用
- 索引需要占用额外的磁盘空间.
对于MyISAM引擎而言,索引文件和数据文件是分离的,索引文件用于保存数据记录的地址.
而InnoDB引擎的表数据文件本身就是索引文件. - 在插入和修改数据时要花费更多的时间,因为索引也要随之变动.
3、创建索引的原则依据
索引虽可以提升数据库查询的速度,但并不是任何情况下都适合创建索引.因为索引本身会消耗系统资源,在有索引的情况下,数据库会先进行索引查询,然后定位到具体的数据行,如果索引使用不当,反而会增加数据库的负担.
表的主键、外键必须有索引.因为主键具有唯一性,外键关联的是子表的主键,查询时可以快速定位
记录数超过300行的表应该有索引.如果没有索引,需要把表遍历一遍,会严重影响数据库的性能
经常与其他表进行连接的表,在连接字段上应该建立索引.
唯一性太差的字段不适合建立索引
更新太频繁地字段不适合创建索引
经常出现在WHERE子句中的字段,特别是大表的字段,应该建立索引.
select name,score from ky20 where id=1
索引应该建在选择性高的字段上
索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引.
id type score zhusang(txt) page blog
Mysql的优化哪些字段/场景适合创建索引,哪些不适合
1、小字段
2、唯一性强的字段
3、更新不频繁,但查询率很高的字段
4、表记录超过300+行
5、主键、外键、唯一键
4、索引的分类和创建
模板:
mysql -u root -p
create database ux;
use ux;
create table ux01 (id int (10),name varchar (10),cardid varchar (18),phone varchar (11),address varchar (50),remark text);
desc ux01;
insert into ux01 values (1,‘zhangsan’,‘123’,‘111111’,‘nanjing’,‘this is vip’);
insert into ux01 values (4,‘lisi’,‘1234’,‘444444’,‘nanjing’,‘this is normal’);
insert into ux01 values (2,‘wangwu’,‘12345’,‘222222’,‘benjing’,‘this is normal’);
insert into ux01 values (5,‘zhaoliu’,‘123456’,‘555555’,‘nanjing’,‘this is vip’);
insert into ux01 values (3, ‘qianqi’,‘1234567’, ‘333333’,‘shanghai’, ‘this is vip’);
select * from ux01;
①普通索引
最基本的索引类型,没有唯一性之类的限制.
直接创建索引
CREATE INDEX 索引名 ON 表名(列名[(length)]);
zhangsan
(列名(length)):length是可选项.如果忽略length的值,则使用整个列的值作为索引.如果指定使用列前的length个字符来创建索引,这样有利于减小索引文件的大小.
索引名建议以"_index"结尾.
示例:create index phone_index on ux01 (phone);
select phone from ux01;
show create table ux01;KEY “phone_index” (“phone”),
修改表方式创建
ALTER TABLE 表名 ADD INDEX索引名(列名);
例: alter table ux01 add index id_index (id);
select id from ux01;
select id,name from ux01;show create table ux01;
KEY “id_index” (“id”)
创建表的时候指定索引
CREATE TABLE表名(字段1数据类型,字段2数据类型[,.……],INDEX索引名(列名));
例:create table ux02(id int(4) not null,name varchar(10) not null,cardid varchar(18) not null,index id_index (id));
show create table ux02;KEY “id_index” (“id”)
②、唯一索引
与普通索引类似,但区别是唯一索引列的每个值都唯一
唯一索引允许有空值(注意和主键不同).如果是用组合索引创建,则列值的组合必须唯一.添加唯一键将自动创建唯一索引.
直接创建唯一索引
CREATE UNIQUE INDEX索引名 ON 表名(列名);
例:UNIQUE
create unique index address_index on ux01 (address);
create unique index name_index on ux01 (name);
show create table ux01;UNIQUE KEY “address_index” (“address”),
UNIQUE KEY “name_index” (“name”),修改表方式创建
ALTER TABLE 表名ADD UNIQUE索引名(列名);
例: alter table ux01 add unique cardid_index (cardid); show create table ux01;
UNIQUE KEY “cardid_index” (“cardid”),
创建表的时候指定
CREATE TABLE表名(字段1数据类型,字段2数据类型[,………],UNIQUE索引名(列名));
例:create table amd2 (id int,name varchar(20),unique id_index (id));
show creat table amd2;UNIQUE KEY “id_index” (“id”)
③、主键索引
是一种特殊的唯一索引,必须指定为“PRIMARYKEY”.
一个表只能有一个主键,不允许有空值.添加主键将自动创建主键索引.
- 创建表的时候指定
CREATE TABLE 表名([…],PRIMARY KEY(列名));
例:create table ux01(id int primary key,name varchar(20));
create table ux02 (id int,name varchar(20),primary key (id));
show create table ux01;
show create table ux02; - 修改表方式创建
ALTER TABLE 表名 ADD PRIMARY KEY (列名);
④、组合索引(单列索引与多列索引)(※※When querying, first query the parentheses,Left to right when indexing)
可以是单列上创建的索引,也可以是在多列上创建的索引.需要满足最左原则,因为select语句的where条件是依次从左往右执行的,所以在使用select语句查询时where条件使用的字段顺序必须和组合索引中的排序一致,否则索引将不会生效.
CREATE TABLE 表名(列名1数据类型,列名2数据类型,列名3数据类型,INDEX索引名(列名1,列名2,列名3));
select * from表名 where 列名1=‘…’ AND 列名2=‘…’ AND 列名3=‘…’;
例:create table ux03 (id int not null,name varchar(20),cardid varchar(20),index index_amd (id,name));
show create table ux03;
KEY “index_ux” (“id”,“name”)
insert into ux03 values(1,‘zhao’,‘123’);
insert into ux03 values(2,‘qian’,‘456’);
select id,name from ux03;
+----+------+
| id | name |
+----+------+
| 1 | zhao |
| 2 | qian |
+----+------+
小结:
组合索引创建的字段顺序是其触发索引的查询顺序
select id,name from ux03; #会触发组合索引
而:
select name,id from ux03; #按照索引从左到右检索的顺序,则不会触发组合索引
⑤、全文索引(FULLTEXT)
适合在进行模糊查询的时候使用,可用于在一篇文章中检索文本信息.
在 MySQL.5.6版本以前FULLTEXT 索引仅可用于 MyISAM 引擎,在 5.6版本之后 innodb 引擎也支持 FULLTEXT 索引.全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建.每个表只允许有一个全文索引.
直接创建索引
CREATE FULLTEXT INDEX 索引名 ON 表名(列名);
例:select * from ux01;
create fulltext index remark_index on ux01 (remark);show create table ux01;
show index from ux01\G;
show keys from ux01\G;
FULLTEXT KEY “remark_index” (“remark”)
修改表方式创建
ALTER TABLE 表名 ADD FULLTEXT索引名(列名);创建表的时候指定索引
CREATE TABLE 表名(字段1数据类型[,.….],FULLTEXT 索引名(列名));
#数据类型可以为CHAR、VARCHAR或者TEXT使用全文索引查询
SELECT * FROM 表名 WHERE MATCH(列名)AGAINST(‘查询内容’);
例:select * from member where match(remark) against(‘this is vip’);
or select * from member where remark=‘this is vip’;
5、查看索引
show index from表名;
show index from 表名\G; 竖向显示表索引信息
show keys from表名;
show keys from 表名\G;
各字段的含义如下:
Table 表的名称
Non_unique 如果索引内容唯一,则为0:如果可以不唯一,则为1.
Key_name 索引的名称.
Seq_in_index 索引中的列序号,从1开始.limit2,3
Column_name 列名称.
Collation 列以什么方式存储在索引中.在NYSQL中,有值’A’(升序)或NULL(无分类).
Cardinality 索引中唯一值数目的估计值.
sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目(zhangsan).如果整列被编入索引,则为NULL.
Packed 指示关键字如何被压缩.如果没有被压缩,则为NULL.
Null 如果列含有NULL,则含有YES.如果没有,则该列含有NO.
Index type 用过的索引方法(BTREE,FULLTEXT,HASH,RTREE).
Comment 备注.
小结:
索引分为:
普通索引:针对所有字段,没有特殊的需求/规则
唯一索引:针对唯一性的字段,仅允许出现一次空值
组合索引:(多列/多字段组合形式的索引)
全文索引:(varchar char text)
主键索引:针对唯一性字段、且不可为空,同时一张表只允许包含一个主键索引
创建索引:
在创建表的时候,直接指定index
alter修改表结构的时候,进行add添加index
直接创建索引index
PS:主键索引–》直接创建主键即可
6、删除索引
- 直接删除索引
DROP INDEX 索引名ON 表名;
例:drop index id_index on ux01; - 修改表方式删除索引
ALTER TABLE表名 DROP INDEX 索引名;
例:alter table ux01 drop index cardid_index;
show index from ux01; - 删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;
二、事务介绍
1、事务的概念
- 是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行
- 是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元
- 适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等等
- 通过事务的整体性以保证数据的一致性
2、事务的ACID特点
原子性(Atomicity)
- 事务是一个完整的操作,事务的各元素是不可分的
- 事务中的所有元素必须作为一个整体提交或回滚
- 如果事务中的任何元素失败,则整个事务将失败
一致性(Consistency)
- 当事务完成时,数据必须处于一致状态
- 在事务开始前,数据库中存储的数据处于一致状态
- 在正在进行的事务中,数据可能处于不一致的状态
- 当事务成功完成时,数据必须再次回到已知的一致状态
隔离性(Isolation)
- 对数据进行修改的所有并发事务是彼此隔离的,表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务
- 修改数据的事务可在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同数据的事务结束之后访问这些数据
持久性(Durability)
- 指不管系统是否发生故障,事务处理的结果都是永久的
- 一旦事务被提交,事务的效果会被永久地保留在数据库中
mysql事务默认自动提交,当sqlThe transaction is automatically committed when the statement is committed.
3、一个事务的执行不能被其他事务干扰,The interactions between transactions are
脏读(读取未提交数据):脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据.读到了并不一定最终存在的数据,这就是脏读
案例
比如事务B执行过程中修改了数据X,在未提交前,事务A读取了X,而事务B却回滚了,这样事务A就形成了脏读.也就是说,当前事务ARead the data it is other affairsBI want to modify the data that has become but has not been modified successfully.
不可重复读(前后多次读取,数据内容不一致):一个事务内两个相同的查询却返回了不同数据.这是由于查询时系统中其他事务修改的提交而引起的.
案例
事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到row1,但列内容发生了变化.
select * from ux01;
1 zhangsan 20分
select * from Member;
1 zhangsan 30分
幻读(前后多次读取,数据总量不一致):一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行.同时,另一个事务也修改这个表中的数据,这种修改是向表中插入一行新数据.那么,操作前一个事务的用户会发现表中还有没有修改的数据行,就好象发生了幻觉一样.
案例
假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读
丢失更新:两个事务同时读取同一条记录,A先修改记录,B也修改记录(B不知道A修改过,B提交数据后B的修改结果覆盖了A的修改结果.
A 30 ->40 事务 先完成
B 30 ->50 事务 后完成
B的事务结果会覆盖A的事务结果,最终值为50
4、Mysql及事务隔离级别(四种)
(1)read uncommitted(未提交读):读取尚未提交的数据:不解决脏读
允许脏读,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值.也就是可能读取到其他会话中未提交事务修改的数据
(2)read committed(提交读):读取已经提交的数据:可以解决脏读
只能读取到已经提交的数据.oracle等多数数据库默认都是该级别(不重复读).
(3)repeatable read(可重复读):重读读取:可以解决脏读和不可重复读-mysql默认的可重复读.无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响
(4)serializable:串行化:可以解决脏读 不可重复读 and virtual reading,相当于锁表
完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞.
mysql默认的事务处理级别是 repeatable read,而oracle和SQL Server是 read committed.
//事务隔离级别的作用范围分为两种:
全局级:对所有的会话有效
会话级:只对当前的会话有效
1、查询全局事务隔离级别
show global variables like ‘%isolation%’;
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | **REPEATABLE-READ** |
+---------------+-----------------+
1 row in set (0.00 sec)
SELECT @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| **REPEATABLE-READ** |
+-----------------------+
1 row in set (0.00 sec)
2、查询会话事务隔离级别
show session variables like ‘%isolation%’;
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | **REPEATABLE-READ** |
+---------------+-----------------+
1 row in set (0.00 sec)
SELECT @@session.tx_isolation;
+------------------------+
| @@session.tx_isolation |
+------------------------+
| **REPEATABLE-READ** |
+------------------------+
1 row in set (0.00 sec)
SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| **REPEATABLE-READ** |
+-----------------+
1 row in set (0.00 sec)
3、设置全局事务隔离级别
set global transaction isolation level read committed;
show global variables like ‘%isolation%’;
+---------------+----------------+
| Variable_name | Value |
+---------------+----------------+
| tx_isolation | **READ-COMMITTED** |
+---------------+----------------+
1 row in set (0.00 sec)
select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| **READ-COMMITTED** |
+-----------------------+
1 row in set (0.00 sec)
4、设置会话事务隔离级别
set session transaction isolation level read committed;
show session variables like ‘%isolation%’;
+---------------+----------------+
| Variable_name | Value |
+---------------+----------------+
| tx_isolation | **READ-COMMITTED** |
+---------------+----------------+
1 row in set (0.00 sec)
select @@session.tx_isolation;
+------------------------+
| @@session.tx_isolation |
+------------------------+
| **READ-COMMITTED** |
+------------------------+
1 row in set (0.00 sec)
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| **READ-COMMITTED** |
+----------------+
1 row in set (0.00 sec)
5、事务控制语句
BEGIN 或 START TRANSACTION:显式地开启一个事务.
COMMIT或COMMIT WORK:提交事务,并使已对数据库进行的所有修改变为永久性的.
ROLLBACK或ROLLBACK WORK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改.
SAVEPOINT S1:使用SAVEPOINT允许在事务中创建一个回滚点,一个事务中可以有多个
SAVEPOINT;"S1"代表回滚点名称.
ROLLBACK TO [SAVEPOINT] S1:把事务回滚到标记点.
create database SCHOOL;
use SCHOOL;
create table info(
id int(10) primary key not null,
name varchar (40),
moneny double
);
insert into info values(1,‘A’,1000);
insert into info values(2,‘B’,1000);
select * from info;
①、测试提交事务
begin;
update info set moneny= moneny -100 where id=1;
select * from info;

commit;

quit
mysql -u root -p
use SCHOOL;
select * from info;

②、测试回滚事务
begin;
update info set moneny= moneny + 500 where id=1;
select * from info;
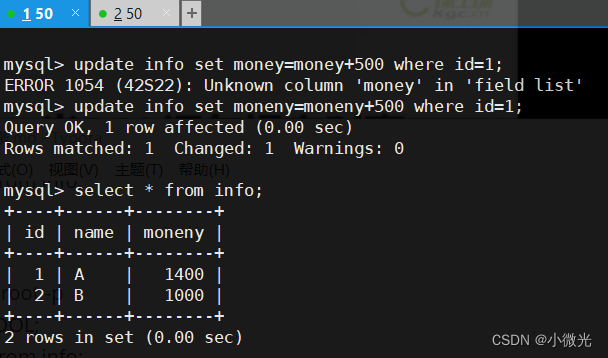

rollback;


quit
mysql -u root -p
use SCHOOL;
select * from info;
③、测试多点回滚
begin;
update info set moneny= moneny + 777 where id=1;
select * from info;

SAVEPOINT S1;
update info set moneny= moneny + 111 where id=2;
select * from info;

SAVEPOINT S2;
insert into info values(3,‘C’,1000);
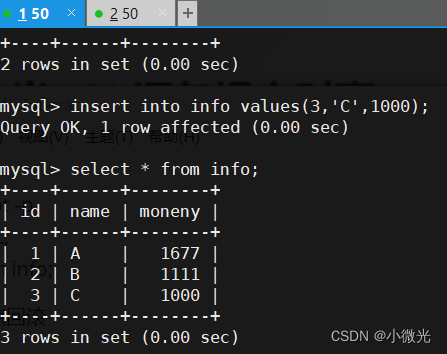
SAVEPOINT S3;

select * from info;

ROLLBACK TO S2;
select * from info;
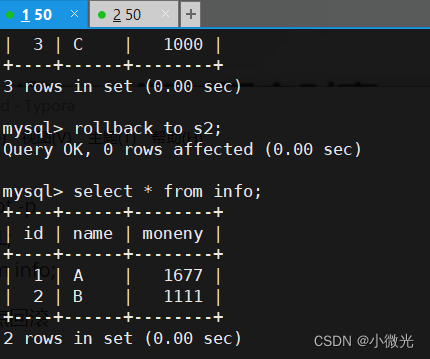
ROLLBACK TO S3;
ROLLBACK TO S1;
select * from info;

④、使用set设置控制事务
SET AUTOCOMMIT=0; #禁止自动提交
show variables like’autocommit’;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.01 sec)
SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1
show variables like’autocommit’;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
SHOW VARIABLES LIKE ‘AUTOCOMMIT’; #查看Mysql中的AUTOCOMMIT值
如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback l commit;当前事务才算结束.当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果.
如果开启了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit.
当然无论开启与否,begin;commit|rollback;都是独立的事务.
use SCHOOL;
select * from info;
SET AUTOCOMMIT=0;
SHOW VARIABLES LIKE ‘AUTOCOMMIT’;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
update info set moneny= moneny + 111 where id=2;
select * from info;

quit
mysql -u root -p
use SCHOOL;
select * from info;

三、存储引擎介绍
1、存储引擎概念介绍
- MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎
- 存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
- MySQL常用的存储引擎:MyISAM 和 InnoDB
- MySQL数据库中的组件,负责执行实际的数据I/O操作
- MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储
2、MYISAM
MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的
访问速度快,对事务完整性没有要求
MYISAM适合查询、插入为主的应用场景
MyISAM在磁盘上存储成三个文件,文件名和表名都相同,但是扩展名分别为:
文件存储表结构的定义.frm
数据文件的扩展名为.MYD(MYData)
索引文件的扩展名是.MYI(MYIndex)
表级锁定形式,数据在更新时锁定整个表
数据库在读写过程中相互阻塞:——》串行操作,按照顺序操作,每次在读或写的时候会把全表锁起来
会在数据写入的过程阻塞用户数据的读取,也会在数据读取的过程中阻塞用户的数据写入
特性:数据单独写入或读取,速度过程较快且占用资源相对少
MyIsam是表级锁定,读或写无法同时进行
好处是:分开执行时,速度快、资源占用相对较少(相对)
MYISAM表支持3种不同的存储格式:
(1)静态(固定长度)表
静态表是默认的存储格式.静态表中的字段都是非可变字段,这样每个记录都是固定长度的,这种存储
The advantage of the method is that the storage is very fast,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多.
固定长度10
存储非常迅速,容器缓存,故障之后容易恢复
id(5) char(10)
000000001
(2)动态表
动态表包含可变字段(varchar),记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁的更新、删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk-r 命令来改善性能,And it is relatively difficult to recover when a failure occurs
(3)压缩表
压缩表由 myisamchk工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支.
MYISAM适用的生产场景
- 公司业务不需要事务的支持
单方面读取或写入数据比较多的业务
MyISAM存储引擎数据读写都比较频繁场景不适合
使用读写并发访问相对较低的业务
数据修改相对较少的业务
对数据业务一致性要求不是非常高的业务
服务器硬件资源相对比较差
MyIsam:适合于单方向的任务场景、同时并发量不高、对于事务要求不高的场景
3、InnoDB
1、InnoDB特点
支持事务,支持4个事务隔离级别(数据不一致问题)
MySQL从5.5.5版本开始,默认的存储引擎为InnoDB
5.5之前是myisam(isam)默认
读写阻塞与事务隔离级别相关
能非常高效的缓存索引和数据
表与主键以簇的方式存储
支持分区、表空间,类似oracle数据库(5.5—》5.6|和5.7第三代数据库8.0后版本)
支持外键约束,5.5前不支持全文索引,5.5后支持全文索引
对硬件资源要求还是比较高的场合
行级锁定,但是全表扫描仍然会是表级锁定(select),如update table set a=1 where user like ‘%lic%’;
InnoDB中不保存表的行数,如 select count( * )from table;时,InnoDB需要扫描一遍整个表来计算有多少行,但是MYISAM只要简单的读出保存好的行数即可.需要注意的是,当count(*)语句包含where条件时 MyISAM也需要扫描整个表
对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立组合索引
清空整个表时,InnoDB是一行一行的删除,效率非常慢.MyISAM则会重建表(truncate)
死锁 **
MYISAM:表级锁定
innodb:行级锁定
当两个请求分别访问/读取2行记录,同时又需要读取对方的记录数据,因为(行锁的限制)而造成了阻塞的现象
怎么解决死锁
show
企业选择存储引擎依据
业务场景如果并发量大,什么并发量大,读写的并发量大,那我们建议使用innoDB
如果单独的写入或是插入单独的查询,那我们建议使用没有INNODB
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低:
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的
需要考虑每个存储引擎提供了哪些不同的核心功能及应用场景
支持的字段和数据类型
- 所有引擎都支持通用的数据类型
- 但不是所有的引擎都支持其它的字段类型,如二进制对象
锁定类型:不同的存储引擎支持不同级别的锁定
- 表锁定:MYISAM支持
- 行锁定:InnoDB支持
索引的支持
- 建立索引在搜索和恢复数据库中的数据时能显著提高性能
- 不同的存储引擎提供不同的制作索引的技术
- 有些存储引擎根本不支持索引
事务处理的支持
- 提高在向表中更新和插入信息期间的可靠性
- 可根据企业业务是否要支持事务选择存储引擎
二、查看系统支持的存储引擎
show engines;

三、查看表使用的存储引擎
方法一
show table status from库名 where name=‘表名’\G;
例: show table status from SCHOOL where name=‘info’\G;

方法二
use 库名;
show create table 表名;
例:use SCHOOL;
show create table info;
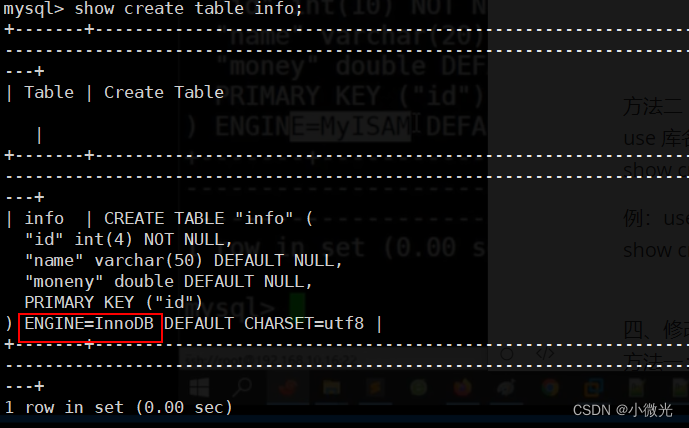
四、修改存储引擎
方法一:通过 alter table修改
use库名;
alter table 表名 engine=MyISAM;
例:use SCHOOL;
alter table info engine=myisam;
show create table info;

方法二:通过修改/etc/my.cnf配置文件,指定默认存储引擎并重启服务
quit
vim /etc/my.cnf
[mysqld]
default-storage-engine=INNODB

systemctl restart mysqld.service
修改完记得重启mysql服务
#注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更.
方法三:通过 createtable创建表时指定存储引擎
use库名;
create table 表名(字段1数据类型,…)engine=MyISAM;
例:mysql -u root-p
use SCHOOL;
create table ky20 (id int(4),name varchar(10),age char(4)) engine=myisam;
show create table ky20\G;
边栏推荐
猜你喜欢

随机推荐
2021强网杯
奥迪的极致高端属于一个大写的H?重塑时空,谁会是这个夜晚的主角?
期货开户前要第一时间确认手续费
shopee API 接入说明
defi质押借贷理财挖矿dapp系统开发逻辑
Interpretation of ZLMediaKit server source code---RTSP push and pull
oracle11g体系结构
leetcode:281. 锯齿迭代器
Error creating bean with name ‘sqlSessionFactory‘ defined in class path reso「建议收藏」
skywalking漏洞学习
nacos服务注册
MySQL增加字段SQL语句
win11安装deepin20.6双系统(双硬盘)
【Web3 系列开发教程——创建你的第一个 NFT(8)】如何开发一个成功的 NFT 项目 | NFT 社区建设技巧
vvic API 接入说明
成为一个优秀的测试工程师需要具备哪些知识和经验?
RMAN-08120的处理
【图像去雾】基于颜色衰减先验的图像去雾附matlab代码
perl编码转换
R语言ggplot2可视化:使用ggpubr包的text_grob函数和as_ggplot函数可视化文本段落(将指定文本段落可视化出来、指定文本段可视化为图像)、face参数指定文本的字体样式