当前位置:网站首页>Making Pre-trained Language Models Better Few-Shot Learners
Making Pre-trained Language Models Better Few-Shot Learners
2022-08-10 17:49:00 【hithithithithit】
Table of Contents
Abstract
Using natural language prompts and task demonstrations as additional information to insert into the input text makes good use of the knowledge in the GPT-3 model.Therefore, this paper proposes the application of few samples in small models.Our approach includes prompt-based fine-tuning while using auto-generated prompts; for task demonstrations, we also redefine a dynamic and selective way to incorporate them into context.
Introduction
While GPT-3 can perform well using only cues and task examples without updating weights, the GPT-3 model is large and cannot be applied to real-world scenarios for fine-tuning.Therefore, this paper proposes to use only a small number of samples to fine-tune the model on small models such as BERT.The authors took inspiration from GPT-3 and used prompt and in-context to optimize both input and output. They used brute force search to get some better-performing answer words, and used T5 to generate prompt templates, which they saidThis method is cheap?Is it cheap to use T5 to generate a template separately?Due to the limitation of input length, they find a good demonstration for each class.Feeling nothing new?GPT-3 is really copied!!!
Methods

label words
Gao et al. (2021) used a pre-training model without fine-tuning to obtain the optimal K candidate words, which were used as the pruned answer word space.Then they further fine-tune the model on the training set to search for n better answer words in this space.Finally, an optimal answer word is obtained according to the results of the validation set.
Prompt template
Gao et al. (2021) Consider the prompt template generation problem as a text generation task, use T5(Raffel et al, 2020) as the generator model.They concatenate the raw input and output as T5 (Raffel et al, 2020) model, then they used beam search to generate multiple prompt templates, fine-tuned on the dev set to get a prompt template with the best performance, and they alsoThe prompt template obtained by beam search is used for the learning of the ensemble model.

Demonstrations
I don't want to read it, it's boring, just insert an example into the input by sampling each class, refer to GPT-3.
Experiments
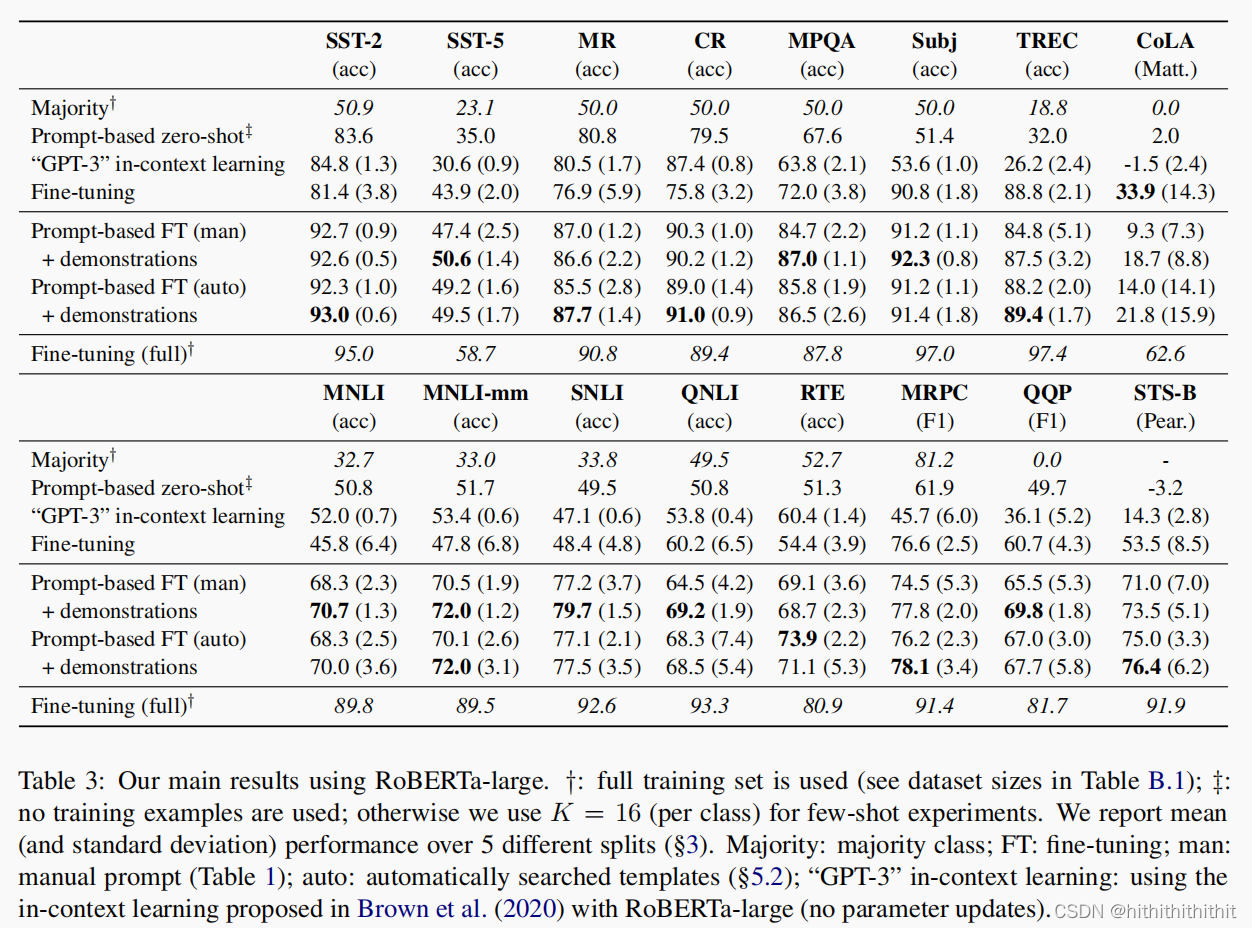
I've done a lot of experiments, but it's okay, I don't know much about these data sets, let's see for yourself

边栏推荐
猜你喜欢




随机推荐
Your local docbook2man was found to work with SGML rather than XML
不止跑路,拯救误操作rm -rf /*的小伙儿
事务的隔离级别,MySQL的默认隔离级别
leetcode:340.至多包含K个不同字符的最长子串
Talk about cloud native data platform
【硬件架构的艺术】学习笔记(4)流水线的艺术
perl编码转换
全新接口——邻家好货 API
Quicker+沙拉查词使用
DeamNet代码学习||网络框架核心代码 逐句查找学习
Trie字典树
如何学习性能测试?
等保2.0一个中心三重防护指的是什么?如何理解?
【接入指南 之 直接接入】手把手教你快速上手接入HONOR Connect平台(中)
1001 A+B Format (string processing)
R语言ggplot2可视化:使用ggpubr包的ggscatter函数可视化分组散点图、stat_mean函数在分组数据点外侧绘制凸包并突出显示分组均值点、自定会均值点的大小以及透明度
烟雾、空气质量、温湿度…自己徒手做个环境检测设备
ZLMediaKit 服务器源码解读---RTSP推流拉流
skywalking漏洞学习
JWT 实现登录认证 + Token 自动续期方案