当前位置:网站首页>训练一个神经网络要多久,神经网络训练时间过长
训练一个神经网络要多久,神经网络训练时间过长
2022-08-11 09:24:00 【阳阳2013哈哈】

为什么要批量训练神经网络
重复利用神经网络时需要多次训练吗
卷机神经网络为什么增加训练次数后 准确率降低了很多
神经网络中进行多次权值训练中的“训练”如何理解
神经网络,训练样本500条,为什么比训练样本6000条,训练完,500条预测比6000条样本好!
并非训练样本越多越好,因课题而异。1、样本最关键在于正确性和准确性。你所选择的样本首先要能正确反映该系统过程的内在规律。
我们从生产现场采得的样本数据中有不少可能是坏样本,这样的样本会干扰你的神经网络训练。通常我们认为坏样本只是个别现象,所以我们希望通过尽可能大的样本规模来抵抗坏样本造成的负面影响。
2、其次是样本数据分布的均衡性。你所选择的样本最好能涉及到该系统过程可能发生的各种情况,这样可以极大可能的照顾到系统在各个情况下的规律特征。
通常我们对系统的内在规律不是很了解,所以我们希望通过尽可能大的样本规模来“地毯式”覆盖对象系统的方方面面。3、再次就是样本数据的规模,也就是你要问的问题。
在确保样本数据质量和分布均衡的情况下,样本数据的规模决定你神经网络训练结果的精度。样本数据量越大,精度越高。
由于样本规模直接影响计算机的运算时间,所以在精度符合要求的情况下,我们不需要过多的样本数据,否则我们要等待很久的训练时间。
补充说明一下,不论是径向基(rbf)神经网络还是经典的bp神经网络,都只是具体的训练方法,对于足够多次的迭代,训练结果的准确度是趋于一致的,方法只影响计算的收敛速度(运算时间),和样本规模没有直接关系。
如何确定何时训练集的大小是“足够大”的?
神经网络的泛化能力主要取决于3个因素:1.训练集的大小2.网络的架构3.问题的复杂程度一旦网络的架构确定了以后,泛化能力取决于是否有充足的训练集。
合适的训练样本数量可以使用Widrow的拇指规则来估计。
拇指规则指出,为了得到一个较好的泛化能力,我们需要满足以下条件(WidrowandStearns,1985;Haykin,2008):N=nw/e其中,N为训练样本数量,nw是网络中突触权重的数量,e是测试允许的网络误差。
因此,假如我们允许10%的误差,我们需要的训练样本的数量大约是网络中权重数量的10倍。
支持向量机为什么比神经网络好?神经网络不是可以训练很多次吗?
边栏推荐
猜你喜欢
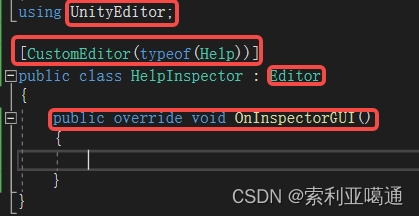
Unity3D - modification of the Inspector panel of the custom class
WordpressCMS主题开发01-首页制作
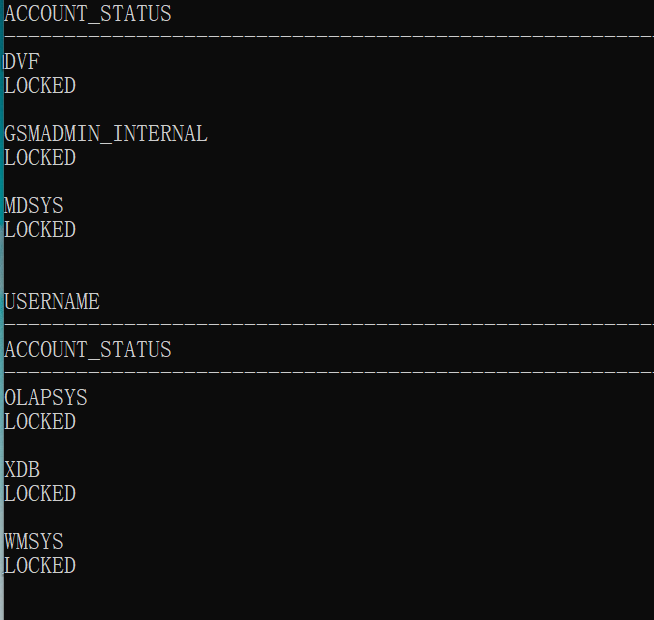
Oracle database use problems
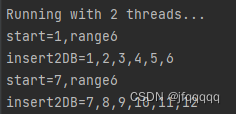
nodejs worker_threads的事件监听问题
pycharm 取消msyql表达式高亮
疫情当前,如何提高远程办公的效率,远程办公工具分享
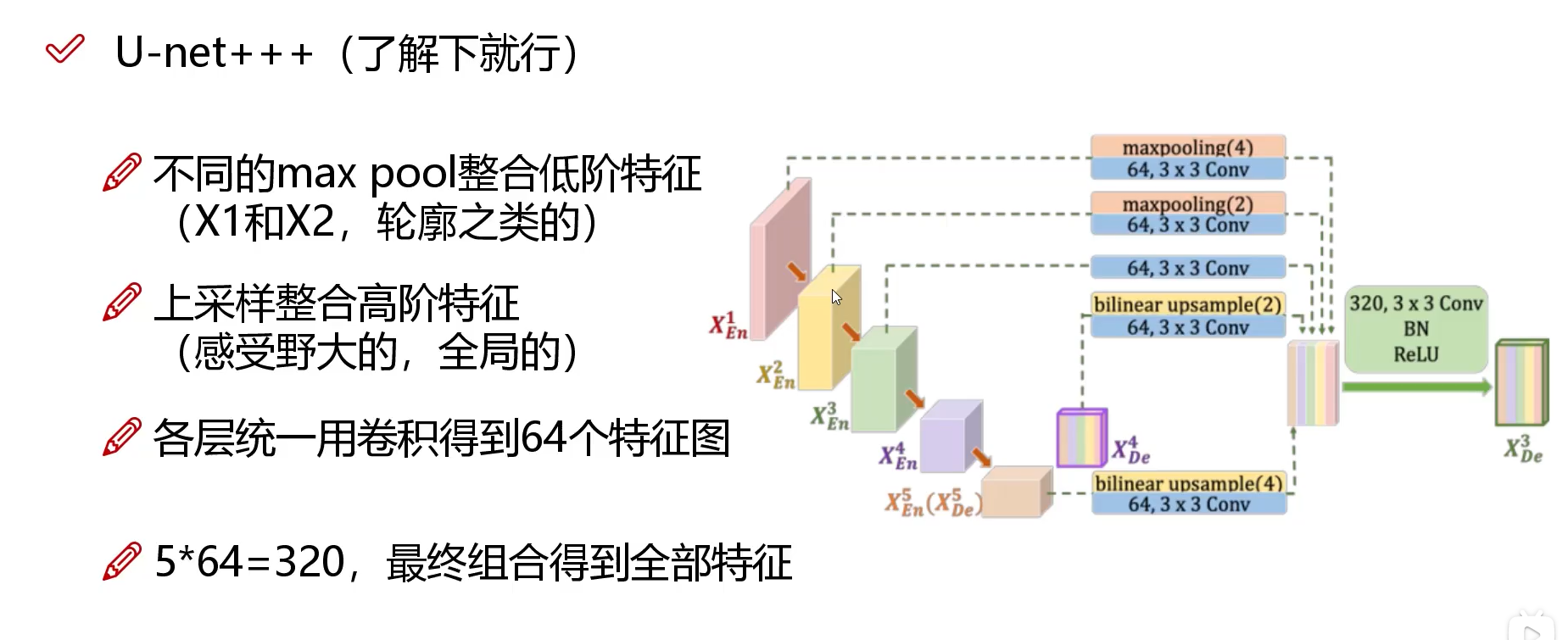
网络模型(U-net,U-net++, U-net+++)
WooCommerce电子商务WordPress插件-赚美国人的钱

canvas文字绘制(大小、粗体、倾斜、对齐、基线)
基于 VIVADO 的 AM 调制解调(1)方案设计
随机推荐
四级独创的阅读词汇表
Audio and video + AI, Zhongguancun Kejin helps a bank explore a new development path | Case study
Detailed Explanation of the Level 5 Test Center of the Chinese Institute of Electronics (1)-string type string
Unity3D - modification of the Inspector panel of the custom class
gRPC系列(四) 框架如何赋能分布式系统
Inventorying Four Entry-Level SSL Certificates
Typescript基本类型---下篇
Getting Started with Kotlin Algorithms Calculating Prime Numbers and Optimization
mindspore如何实现每50个epoch检测一次psnr
halcon实例
Primavera P6 Professional 21.12 登录异常案例分享
js将table生成excel文件并去除表格中的多余tr(js去除表格中空的tr标签)
YTU 2297: KMP pattern matching three (string)
万字长文带你了解多态的底层原理,这一篇就够了
ES6:数值的扩展
SQL语句
Quickly submit a PR (Web) for OpenHarmony in 5 minutes
wordpress插件开发02-首页文章自动摘要插件开发
Typescript基本类型---上篇
在软件工程领域,搞科研的这十年!