当前位置:网站首页>Pytorch 经典卷积神经网络 LeNet
Pytorch 经典卷积神经网络 LeNet
2022-04-23 13:58:00 【哇咔咔负负得正】
Pytorch 经典卷积神经网络 LeNet
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. LeNet
1.0 简介
LeNet 是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由 AT&T 贝尔实验室的研究员 Yann LeCun 在 1989 年提出的(并以其命名),目的是识别图像 [LeCun et al., 1998] 中的手写数字。 当时,Yann LeCun 发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。
当时,LeNet取得了与支持向量机(support vector machines)性能相媲美的成果,成为监督学习的主流方法。 LeNet 被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字。 时至今日,一些自动取款机仍在运行 Yann LeCun 和他的同事 Leon Bottou 在上世纪 90 年代写的代码。
论文地址:https://axon.cs.byu.edu/~martinez/classes/678/Papers/Convolution_nets.pdf
其中的手写数字 MNIST 数据集:
- 50 , 000 50,000 50,000 个训练数据
- 10 , 000 10,000 10,000 个测试数据
- 图像大小 28 × 28 28 \times 28 28×28
- 10 10 10 类 ( 0 → 9 ) (0 \to 9) (0→9)
1.2 LeNet 结构
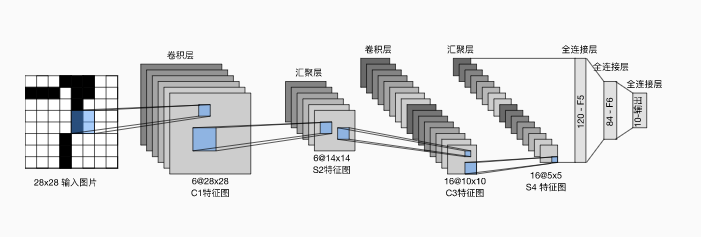
每个卷积块中的基本单元是一个卷积层、一个 sigmoid 激活函数和平均池化层。
注:虽然 ReLU 激活函数和最大池化层更有效,但它们在20世纪90年代还没有出现。
每个卷积层使用 5 × 5 5\times 5 5×5 卷积核和一个 sigmoid 激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有 6 6 6 个输出通道,而第二个卷积层有 16 16 16 个输出通道。使用 2 × 2 2\times 2 2×2 的平均池化窗口通过空间下采样将维数减少4倍。
先使用卷积层来学习图片空间信息,然后使用全连接层来转换到类别空间。
2. 代码实现
2.1 网络结构
对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的 LeNet-5 一致。

!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)

在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。 第一个卷积层使用 2 2 2 个像素的填充,来补偿卷积核导致的特征减少。 第二个卷积层没有填充,因此高度和宽度都减少了 4 4 4 个像素。 随着层叠的上升,通道的数量从输入时的 1 1 1 个,增加到第一个卷积层之后的 6 6 6 个,再到第二个卷积层之后的 16 16 16 个。 同时,每个平均池化层的高度和宽度都减半。最后,每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
2.2 加载 Fashion-MNIST 数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
2.3 评价函数
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
2.4 训练函数
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
# 使用 xavier 权重初始化
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {
train_l:.3f}, train acc {
train_acc:.3f}, '
f'test acc {
test_acc:.3f}')
print(f'{
metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {
str(device)}')
2.5 用 CPU 训练
在 kaggle 中 Accelerator 设置为 None。
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

每秒遍历 5612.2 5612.2 5612.2 个样本。
2.6 用 GPU 训练
在 kaggle 中使用 GPU:


每秒遍历 33873.6 33873.6 33873.6 个样本,可以发现比 CPU 训练快了不少。
训练集精度 0.820 0.820 0.820,测试集精度 0.801 0.801 0.801。
2.7 尝试更换激活函数为 ReLU 以及池化层换成最大池化,调整学习率
net2 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.ReLU(),
nn.Linear(120, 84), nn.ReLU(),
nn.Linear(84, 10))
# 学习率 0.9 的时候会不收敛,所以调整为 0.1
lr, num_epochs = 0.1, 10
train_ch6(net2, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
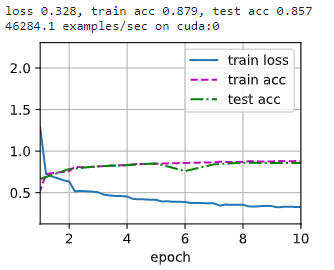
训练集精度 0.879 0.879 0.879,测试集精度 0.857 0.857 0.857,相对于之前的模型确实有提高。
版权声明
本文为[哇咔咔负负得正]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_39906884/article/details/124360050
边栏推荐
- Apache seatunnel 2.1.0 deployment and stepping on the pit
- Express ② (routage)
- [machine learning] Note 4. KNN + cross validation
- About note 1
- Dynamic subset division problem
- AtomicIntegerArray源码分析与感悟
- Processing of ASM network not automatically started in 19C
- 自动化的艺术
- 初探 Lambda Powertools TypeScript
- Quartus Prime硬件实验开发(DE2-115板)实验二功能可调综合计时器设计
猜你喜欢

Express中间件③(自定义中间件)

Express②(路由)

Small case of web login (including verification code login)

Dolphin scheduler scheduling spark task stepping record

Business case | how to promote the activity of sports and health app users? It is enough to do these points well
freeCodeCamp----arithmetic_ Arranger exercise
解决方案架构师的小锦囊 - 架构图的 5 种类型

Dynamic subset division problem
crontab定时任务输出产生大量邮件耗尽文件系统inode问题处理

Technologie zéro copie
随机推荐
Question bank and answer analysis of the 2022 simulated examination of the latest eight members of Jiangxi construction (quality control)
freeCodeCamp----arithmetic_ Arranger exercise
Special window function rank, deny_ rank, row_ number
Processing of ASM network not automatically started in 19C
Small case of web login (including verification code login)
Oracle database recovery data
Jenkins construction and use
Elmo (bilstm-crf + Elmo) (conll-2003 named entity recognition NER)
RAC environment alert log error drop transient type: systp2jw0acnaurdgu1sbqmbryw = = troubleshooting
SQL learning | set operation
SQL learning window function
Leetcode brush question 𞓜 13 Roman numeral to integer
Quartus Prime硬件实验开发(DE2-115板)实验一CPU指令运算器设计
JMeter pressure test tool
Kettle--控件解析
[code analysis (6)] communication efficient learning of deep networks from decentralized data
China creates vast research infrastructure to support ambitious climate goals
Oracle database combines the query result sets of multiple columns into one row
AtCoder Beginner Contest 248C Dice Sum (生成函数)
Express②(路由)