当前位置:网站首页>CVPR22 Oral | shunt through multi-scale token polymerization from attention, code is open source
CVPR22 Oral | shunt through multi-scale token polymerization from attention, code is open source
2022-08-09 23:05:00 【FightingCV】

【写在前面】
最近的视觉Transformer(ViT)Model in various computer vision tasks achieved encouraging results,Thanks to its attention by modeling image block ortokenThe ability of long-term dependence.然而,These models are usually specified in each layer eachtokenCharacteristics of the similar feeling wild.This constraint limits the inevitably multi-scale characteristics of each layer to capture the attention of ability,Leading to handle multiple objects with different scale image performance.为了解决这个问题,The author puts forward a new general strategy,Called a shunt since attention(SSA),该策略允许VIT在每个注意力层的混合尺度上对注意力进行建模.SSAThe key idea is to heterogeneous receptive field size injectiontoken:Before the calculation from the matrix concentration,它选择性地合并tokenTo show a larger object features,同时保留某些tokenTo retain fine-grained characteristics.The new merger enables the attention to study the relationship between the different size object,同时减少了tokenNumber and calculate the cost.跨各种任务的大量实验证明了SSA的优越性.具体来说,基于SSA的Transformer达到了84.0%的Top-1精度,优于ImageNet上最先进的Focal Transformer,Model size and calculate the cost for only half its,在相似的参Number and calculate the cost下,在COCO上超过了Focal Transformer 1.3 mAP,在ADE20K上超过了2.9 mIOU.
1. 论文和代码地址

Shunted Self-Attention via Multi-Scale Token Aggregation
论文地址:https://arxiv.org/abs/2111.15193[1]
代码地址:https://github.com/oliverrensu/shunted-transformer[2]
2. Motivation
最近的视觉Transformer(ViT)Model in various computer vision tasks shows excellent performance.与专注于局部建模的卷积神经网络不同,ViTs将输入图像划分为一系列patch,And through the global since the attention gradually updatetoken特征.Since the attention can be effectively simulatedtokenThe long-term dependence,并通过聚合来自其他tokenInformation to gradually expand its receptive field size,这在很大程度上解释了VIT的成功.
然而,Since the attention mechanism also brought expensive memory consumption cost,即输入tokenThe square of the number of than.因此,最先进的TransformerModel adopted various down sampling strategy to reduce the size and memory consumption characteristics.Some methods to calculate the characteristic of high resolution attention,并通过将token与token的空间缩减合并来降低成本.然而,These methods tend to be merged in a since attention layer too muchtoken,Resulting from the small object and the background noisetoken的混合.This kind of behavior, in turn, will reduce the model to capture the efficiency of the small object.
此外,以前的TransformerModel largely ignored the attention the multiscale nature scene objects inside the,Make them in different size of wild scene involving vulnerable.从技术上讲,This incompetence attributable to the attention of the potential mechanism:Existing methods rely ontokenThe static receptive field and a pay attention to the unity inside layer of information granularity,因此无法同时捕获不同尺度的特征.
为了解决这一局限性,The author introduces a new universal attention since the plan,Called a shunt since attention(SSA),The plan explicitly allow the attention within the same layer of the head, respectively, considering the characteristics of coarse-grained and fine-grained.A merger with before too muchtokenOr to capture the small object fail differently,SSAEffectively in the same layer of different head at the same time for different size of object modeling,Make it has good computational efficiency and retain the ability to fine-grained details.

The author in the diagram above shows the attention(来自ViT)、下采样辅助注意力(来自PVT)和SSA之间的定性比较.When the feature mapping application of same size different note,ViTCapture the fine-grained small object,But it has very high calculation cost(上图(a));PVT降低了计算成本,But its attention is limited to large coarse-grained objects(上图(b)).相比之下,提出的SSAKeep the lighter computational load,But at the same time, considering the mixed scale note(上图(c)).有效地,SSANot only a precise focus on coarse-grained large object(如沙发),But also focus on granular small object(Such as lighting and fan),Even some in the corner of the object,These objects are unfortunately byPVT忽略.The authors in the following figure shows the attention to visual comparison,以突出SSA的学习尺度自适应注意力.

SSAThe multi-scale attention mechanism is by putting more attention head into several groups to implement.Each group has a dedicated attention particle size.For fine-grained group,SSALearning polymerization a littletokenAnd retain more local details.For the rest of the coarse-grained head group,SSALearning to aggregate a lottoken,从而降低计算成本,While maintaining the ability to capture large objects.多粒度组共同学习多粒度信息,The model can effectively modeling multi-scale objects.

如上图所示,The author shows from stack multiple based onSSABlock the shuntTransformer模型的性能.在ImageNet上,In this paper, the shuntTransformerBetter than the most advanced focusTransformer,At the same time the model size by half.When reduced to small size,分流Transformer实现了与DeiT Small相似的性能,但只有50%的参数.对于对象检测、实例分割和语义分割,In the model is similar to the size of theCOCO和ADE20K上,分流TransformerIs always superior to focusTransformer.
本文的贡献如下:
The author puts forward the shunt from attention(SSA),它通过多尺度tokenAggregation in a unified multi-scale feature extraction in the attention layer.本文的SSAAdaptively with large objects on thetoken以提高计算效率,And keep the small objecttoken.
基于SSA,The author constructs the shuntTransformer,Can effectively capture the multi-scale objects,Especially small and remote isolated objects.
The authors evaluated the proposed shuntTransformerAll kinds of research,包括分类,目标检测和分割.实验结果表明,Under the model of similar size,In this paper, the shuntTransformerAlways better than the previous visualTransformer.
3. 方法

In this paper, the shuntTransformer的整体架构如上图所示.Since it is based on the new shunt attention(SSA)块的基础上.本文的SSA块与ViTTraditional since the attention of the two main difference:1)SSADivert attention mechanism is introduced for each since attention layer,To capture more different sizes of particle size information and better modeling object,尤其是小对象;2) 它通过增强跨token交互,Enhanced in the ability to point feedforward layer extracts local information.此外,In this paper, the shuntTransformer部署了一种新的patch嵌入方法,For the first piece of attention for better input characteristic figure.在下文中,The author will expound the new place.
3.1. Shunted Transformer Block
In the proposed shuntTransformer的第i个阶段,有个Transformer块.每个transformerBlock contains a since attention layer and a feedforward.In order to reduce the computational cost of dealing with high resolution figure,PVTIntroduced the space reduction attention(spatial-reduction attention,SRA)To replace the original long since attention(multi-head self attention,MSA).然而,SRATend to be in a much attention in the polymerizationtoken,And only within a single scale providetoken特性.These limitations hindered the multi-scale especially small size object model to capture the ability.因此,The author are introduced within a since attention layer parallel learning multi-granularity shunt from attention.
3.1.1 Shunted Self-Attention
输入序列First the projection to the query(Q)、键(K)和值(V)张量中.然后,Long since attention byHA separate note head parallel computing since the attention.为了降低计算成本,作者遵循PVT并减少K和V的长度,而不是像在Swin Transformer中那样将{Q,K,V}分割为多个区域.

如上图所示,本文的SSA不同于PVT的SRA,因为K,VLength in the same attention since the layer between the attention of the head is not the same.相反,The length of different head,To capture different granularity of information.This provides a multi-scaletoken聚合(MTA).具体而言,对于由iThe index of different head,将键K和值VThe sample to a different size:
这里,是第iHead of the multi-scaletoken聚合层,下采样率为.在实践中,The authors use convolution kernels and step forThe convolution kernels of convolution layer.是第iLinear projection parameters in size.In a layer of attention head variation.因此,Keys and values can capture different dimensions in the attention.是MTAThe local enhancement components,Used for depth of convolutionV值.Compared with the space to cut,保留了更多细粒度和低层次的细节.
And then through the following formula to calculate the shunt from attention:
其中是尺寸.Thanks to the multi-scale keys and values,In this paper, the shunt from attention in multi-scale object capture more powerful.Calculate the cost of reducing may depend onr的值,因此,可以很好地定义模型和r,To weigh the computation cost and model performance.当r变大时,K,VIncorporating the moretoken,并且K,V的长度较短,因此,计算成本较低,But still keep the ability to capture large objects.相反,当r变小时,保留了更多细节,But bring more computing cost.In a since attention layer integration of variousr使其能够捕获多粒度特征.
3.1.2 Detail-specific Feedforward Layers

在传统的前馈层中,全连接层是逐点的,Can't learn crosstoken信息.在这里,The author aims to specify details to supplement the local information of feedforward layer.如上图所示,The author through the feedforward layer between two completely connection layer to add data in a specific layer to supplement the feedforward local details:
其中是具有参数θ的细节特定层,在实践中通过深度卷积实现.
3.2. Patch Embedding
TransformerFirst designed for processing sequence data.如何将图像映射到序列对于模型的性能很重要.ViTDirectly to the input image is divided into16×16非重叠patch.最近的一项研究发现,在patchEmbedded in the use of convolution can provide higher qualitytoken序列,并有助于transformerThan the traditional step non-overlappingpatch嵌入“Look better”.因此,Some literature to use7×7Convolution of overlappatch嵌入.
在本文的模型中,The authors adopt different overlapping convolution layer according to the model size.The author will step for2And zero padding7×7卷积层作为patchThe first layer of the embedded,And according to the model size increase step for1的额外3×3卷积层.最后,使用步长为2的非重叠投影层生成大小为的输入序列.
3.3. Architecture Details and Variants
给定一个大小为H×W×3的输入图像,The author adopts the abovepatchLength of embedding method、token维数为CThe amount of information moretoken序列.根据之前的设计,In this paper, the model has four stages,Each phase contains several shuntTransformer块.在每个阶段,Each piece of output characteristic figure of the same size.The author USES the belt step2(线性嵌入)的卷积层来连接不同的阶段,在进入下一阶段之前,Characteristics of figure will halve the size of the,But the dimension will double.因此,Have each phase output characteristic map,的大小为.

The author put forward in this paper, the model of three different configuration,So under the condition of similar parameters and fair comparison.如上表所示,head和Represents a piece of quotas, and a stage of the blocks.变体仅来自不同阶段的层数.具体来说,The Numbers of each block is set to2,4,8,16.patchEmbedded in the scope of convolution as1到3.
4.实验

上表展示了本文方法在ImageNet-1K上的实验结果,,可以看出,In this paper, the method on each model size can achieveSOTA结果.

The table above shows the useMask R-CNNFor target detection and semantic segmentation,The performance of the model,可以看出,The method has obvious advantages in the performance.

The table above shows the useRetinaNetFor target detection and semantic segmentation,The performance of the model.

结果如上表所示.In this paper, the shuntTransfomerIn all framework has high performance and fewer parameters,Better than the most advanced beforeTransfomer.

作者还以SegFormer为框架,在SegformersThe comparison of the this article main andMiT的主干.结果见上表.
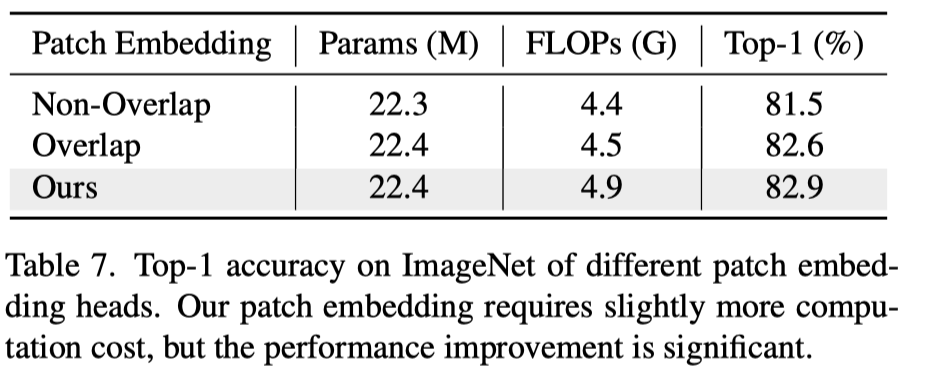
上表展示了不同patch embedding的实验结果.

作者提出了一种新的token聚合函数,Multi-scale object is used to merge the token,Keeping both the global and local information.从上表中可以看出,In this paper, a newtokenAggregation function is similar to the convolution space reduction calculation,But have more improvement.

The table above shows the proposedFFNThe performance of the improved results.
5. 总结
在本文中,The author puts forward a new shunt since attention(SSA)Plan to articulate the multi-scale features.Instead of focusing only on a attention layer static characteristic diagram of work in different,The author maintains the multi-scale characteristic figure,Focus on one since the attention these characteristics graph layer of multi-scale objects.大量实验表明,In this paper, the model of the trunk is effective for all kinds of downstream tasks.具体来说,This model is superior to the previousTransformers,并在分类、Detection and segmentation on the task, the most advanced results.
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://arxiv.org/abs/2111.15193: https://arxiv.org/abs/2111.15193
[2]https://github.com/oliverrensu/shunted-transformer: https://github.com/oliverrensu/shunted-transformer
边栏推荐
- 浅谈Numpy中的shape、reshape函数的区别
- Don't tell me to play, I'm taking the PMP exam: what you need to know about choosing an institution for the PMP exam
- 在VMware上安装win虚拟机
- Daily practice of PMP | Do not get lost in the exam -8.8 (including agility + multiple choice)
- PHP 二维数组根据某个字段排序
- 《强化学习周刊》第57期:DL-DRL、FedDRL & Deep VULMAN
- 别叫我玩,我要考PMP:考PMP选择机构需要了解的那些事儿
- PMP每日一练 | 考试不迷路-8.9(包含敏捷+多选)
- np中的round函数,ceil函数与floor函数
- 什么是源文件?
猜你喜欢

AI Knows Everything: Building and Deploying a Sign Language Recognition System from Zero

LoRa无线技术在物联网应用市场的概况和发展
Beat the interviewer, the CURD system can also make technical content

How to fix Windows 11 not finding files

LoRa Basics无线通信技术和应用案例详解

微软Excel表格点击单元格行和列都显示颜色怎么弄?聚光灯效果设置

PMP每日一练 | 考试不迷路-8.9(包含敏捷+多选)

SQL语句及索引的优化
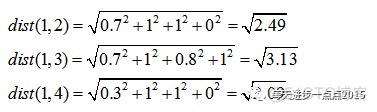
knn到底咋回事?

编程时请选择正确的输入法,严格区分中英文
随机推荐
fixed investment fund
ACM MM 2022 | Cloud2Sketch: 长空云作画,AI笔生花
matlab neural network ANN classification
cad图纸怎么复制到word文档里面?Word里插CAD图怎么弄?
Word第一页不要页眉怎么设置?设置Word首页不要页眉方法教程
单元测试
小黑leetcode清爽雨天之旅,刚吃完宇飞牛肉面、麻辣烫和啤酒:112. 路径总和
Reverse Analysis of Unknown Cryptographic Protocol Based on Network Data Flow
Optimization of SQL Statements and Indexes
supervisor 命令操作大全「建议收藏」
np中的round函数,ceil函数与floor函数
URL Protocol web page to open the application
Definition and Basic Operations of Sequence Tables
[corctf 2022] 部分
浅谈Numpy中的shape、reshape函数的区别
STC8H开发(十五): GPIO驱动Ci24R1无线模块
DSPE-PEG-Silane, DSPE-PEG-SIL, phospholipid-polyethylene glycol-silane modified silica particles
mysql多表左链接查询
Don't tell me to play, I'm taking the PMP exam: what you need to know about choosing an institution for the PMP exam
TF中使用zeros(),ones(), fill()方法生成数据