当前位置:网站首页>机器学习(一)数据的预处理
机器学习(一)数据的预处理
2022-08-11 07:38:00 【ViperL1】
一、导入标准库(Python)
import numpy as np --数据分析库
import matplotlib.pyplot as plt --绘图库
import pandas as pd --数据集导入二、导入数据集
1.读取文件
dataset = pd.read_csv('Data.csv') --读取数据集合(csv文件)2.创建矩阵
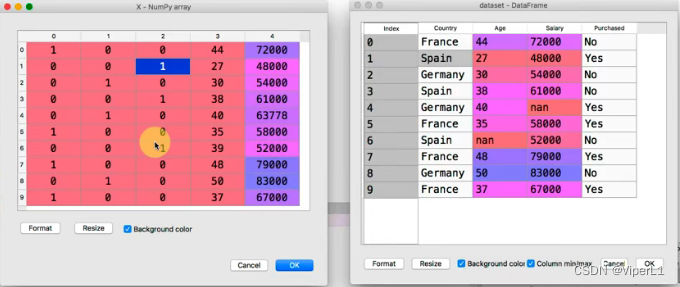
x = dataset.iloc[:,:-1].values --自变量
--iloc表示取数据(行,列) 所有行和除最后一列外的数据
y = dataset.iloc[:,:3].values --因变量--[]内数据的表示
--[x:y,a] x->起始位置,y->终止位置,a->需要处理的数据的位置三、处理缺失数据
这里使用的策略是使用当列的平均值代替缺失数据,此外常用的还有中位数,众数等方法
from sklearn.preprocessing import Imputer --导入缺失数据处理类
imputer = Imputer(missing_values='NaN',strategy = 'mean',axis=0)
--参数含义:缺失数据,采用策略,作用对象为行/列
imputer = imputer.fit(x[:,1:3]) --数据拟合
x[:,1:3] = imputer.transform(x[:,1:3])四、分类数据
将不同的类别转换为有意义的数值(例如利用bool、string)
from sklearn.preprocessing import LabelEncoder --标签编码器,转义为数字
labelencoder_X = LabelEncoder(); --创建对象
x[:,0] = labelencoder_X.fit_transform(x[:,0]) --拟合+转换虚拟编码:将标签转变为编码,使其没有顺序区别
--需要和上面的转换代码混合使用
from sklearn.preprocessing import OneHotEncoder --引入工具
onehotencoder = OneHotEncoder(categorical_features = [0]) --处理数据集的列号
x = onehotencoder.fit_transform(x).toarry()五、训练集和测试集
from sklearn.model_selection import train_test_split --引入工具
x_train,x_test,y_trian,y_test = train_test_split(x,y,test_size=0.2,random_state = 0)
--参数:需要划分的数据,测试集比重(一般为0.2-0.25),训练集比重(一般不单独赋值),随机数生成方式
--训练集的自变量、因变量 / 测试集的自变量、因变量
六、特征缩放
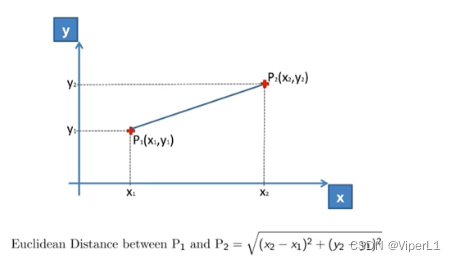
①用于解决欧氏距离遍历数量级差距过大的问题(若差距过大则会出现由数量关系中的某一组数据主导关系的存在)
欧氏距离:(斜线公式)
②加速决策树的收敛
如何进行特征缩放
1.标准化
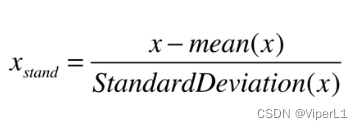
mean--平均值 StanderDeviation--标准方差
x会得到一个平均值为0,标准方差为1的分布
2.正常化
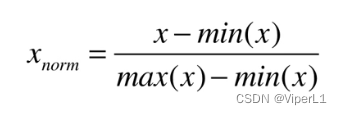
0-1区间内的等比缩小
3.进行缩放
from sklearn.preprocessing import standerScaler --导入工具
sc_x = standardScaler() --类对象
x_train = sc_x.fit_transform(x_train) --拟合+转换
x_test = sc_x.transform(x_test) --已经拟合过了,直接转换七、数据预处理标准模板
一般的数据预处理很少用到缺失数据、分类数据,一般使用以下几步
①读取数据
②测试集和训练集分割
③特征缩放(部分情况需要使用)
边栏推荐
猜你喜欢

matrix multiplication in tf
4.1-支持向量机

求职简历这样写,轻松搞定面试官
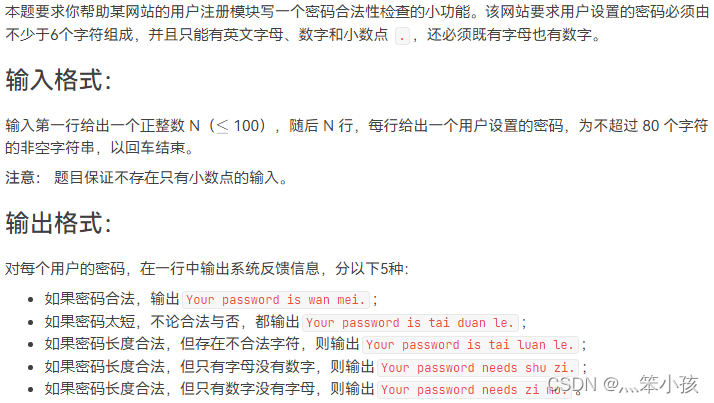
1081 检查密码 (15 分)
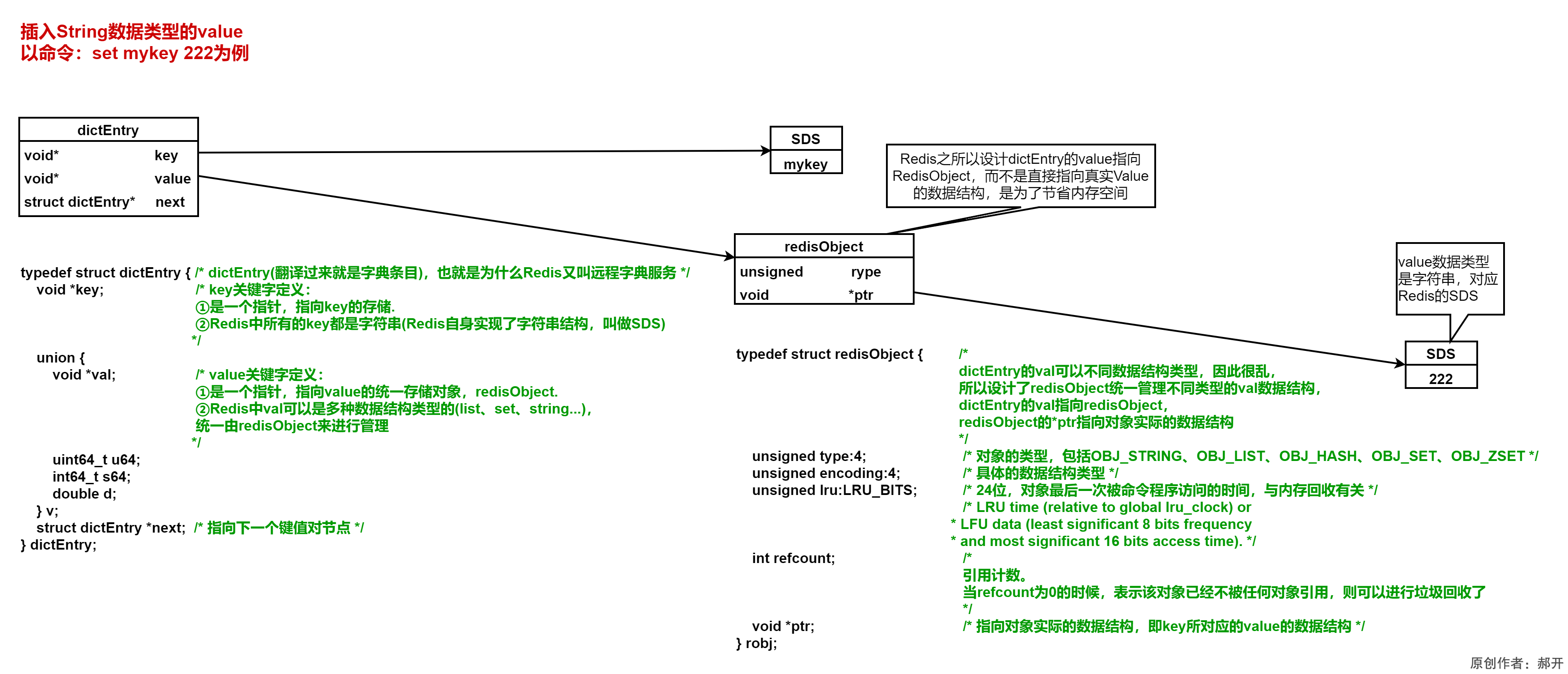
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
Write a resume like this, easy to get the interviewer

TF中的四则运算
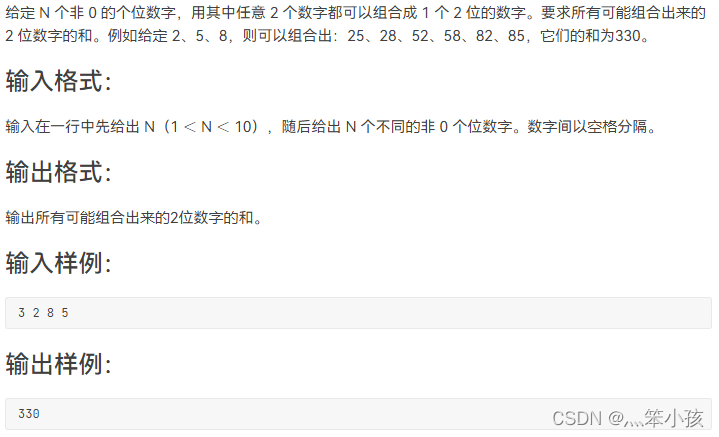
1056 组合数的和 (15 分)
租房小程序
1071 Small Gamble (15 points)

随机推荐
囍楽云任务源码
1.2 - error sources
go sqlx 包
1.2-误差来源
Conditional statements in TF; where()
1081 Check Password (15 points)
1101 How many times B is A (15 points)
Interaction of Pico neo3 in Unity
1061 判断题 (15 分)
oracle数据库中列转行,列会有变化
Pico neo3 Unity打包设置
【C语言】每日一题,求水仙花数,求变种水仙花数
2.1-梯度下降
无服务器+域名也能搭建个人博客?真的,而且很快
1091 N-自守数 (15 分)
分布式锁-Redission - 缓存一致性解决
Test cases are hard?Just have a hand
klayout--导出版图为gds文件
go 操作MySQL之mysql包
关于Excel实现分组求和最全文档