当前位置:网站首页>【语义分割】DeepLab系列
【语义分割】DeepLab系列
2022-08-10 14:32:00 【可乐大牛】
DeepLab V1
概述
我们之前有提到FCN将分类网络的全连接操作转换成卷积操作,得到了端到端的分割网络,然后思考如何提高这个网络的效果。文中出现了两种思路,一种是将最后输出的特征图的尺寸变大,那么上采样之后的结果会好一点;另一种就是使用skip-connection操作,慢慢上采样,并且做特征补充。
DeepLab v1是在第一种思路的基础上做的进一步思考,通过修改骨干网络(减少池化次数和添加空洞卷积),在保证感受野的同时,增大输出特征图的尺寸,并且使用全连接的CRF对最后的输出进行微调,得到更好的效果。
细节
网络结构
骨干网络是VGG,但是做了一些修改,包括:
1、将全连接层转换为卷积层(FCN的思想),
2、最后两个池化层的步长变为1(池化前后尺寸不变,因此最后的输出尺寸是原图的1/8,而不是1/32了),
3、第5个stage的卷积层和fc1的卷积层,变为空洞卷积(至于参数的设置,是为了保证与VGG网络的感受野相同。)
注:第二个修改是为了使最后的输出尺寸变大一点,而第三个修改则是解决第二个修改导致无法使用预训练模型的问题。它使得修改过后网络感受野与原网络相同,就可以使用预训练参数了,只需要把额外添加的参数置为0就可以了。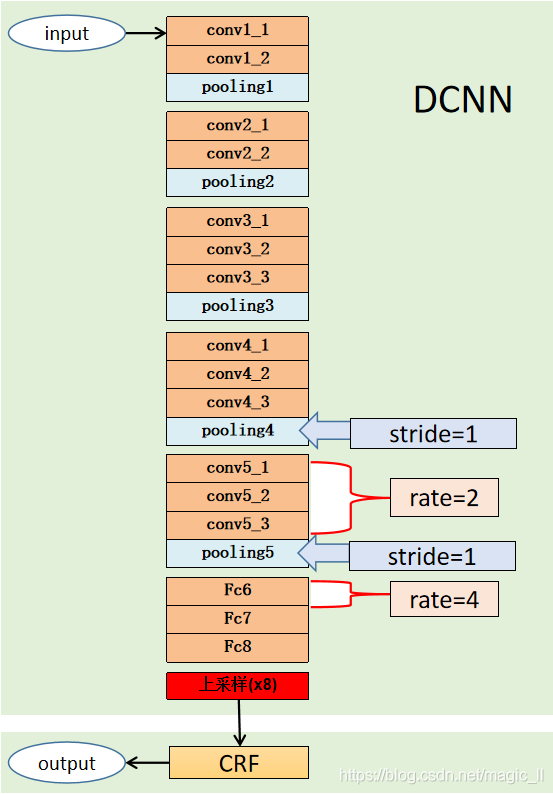
图片来自:链接
空洞卷积
是什么:就是在标准卷积中注入空洞,从而增大感受野。现在基本的深度学习框架都是支持这种类型的卷积的,相对于标准卷积多了一个空洞率的参数,表示间隔的数量。空洞卷积的实际卷积核大小为
K = K + ( k − 1 ) ( a − 1 ) K = K + (k-1)(a-1) K=K+(k−1)(a−1),
其中 K K K是卷积核的大小, a a a是空洞率。例如,一个空洞率为2的3*3卷积,相当于一个5*5卷积。而标准卷积相当于是空洞卷积中a取为1的特例。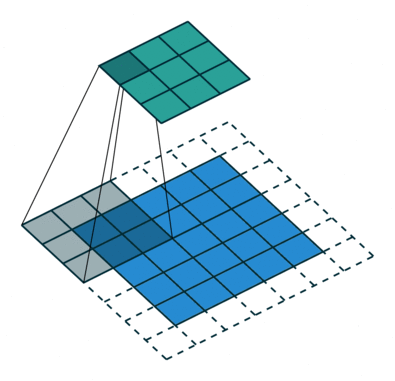
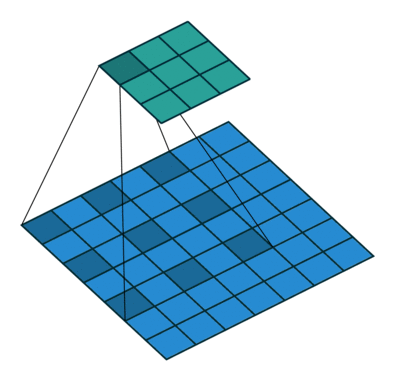
有什么用:
1、扩大感受野。可以用空洞卷积代替下采样操作(步长为2的卷积或者池化),并且可以不降低分辨率或者说少降低分辨率,另一方面,空洞卷积相对于标准卷积而言,没有引入额外的参数。
2、获取多尺度上下文信息。不同的空洞率,带来不同的感受野,也就有不同的上下文信息,这些信息无论是串联还是并联,都是很优秀的。
缺陷:可能带来网格效应。如果单纯的串联的话,图像中并不是所有的像素点都被用于计算,丧失了一些局部信息,并且得到的信息是离散的,不是连续的;另一方面,对于小物体的分割其实没有带来很大的收益,反而会有弊处。因此,作者只是在网络的最后两个stage,取消下采样操作,之后采用空洞卷积弥补丢失的感受野。
全连接CRF
CRF(概率图模型,线性条件随机场)在传统图像处理上的应用是平滑处理。CRF在决定一个位置的像素值时,会考虑周围像素点的值。但是通过CNN得到的概率图在一定程度上已经足够平滑,所以短程的CRF没有太大的意义。于是考虑使用全连接的CRF,这样就会综合考虑全局信息,恢复详细的局部结构,如精确图形的轮廓。CRF几乎可以用于所有的分割任务中图像精度的提高。
CRF是一个后处理阶段,相当于是对于分割图的一个优化过程。
多尺度预测
以往的研究显示,多尺度预测能得到更好的效果,本文也做了尝试。注:多尺度预测其实和skip-connetion操作类似
具体方式就是,在输入图片和前4个 maxpooliing后添加 MLP层(多层感知机,第一层是 3x3x33x128卷积,第二层是 1x1x11x128 卷积),得到预测结果,然后将这个结果和最后一层的输出concat起来,得到最终的结果。这个操作也是有提升的,但是没有全连接CRF带来的提升更多。
DeepLab V2
概述
v2在v1的基础上加入了ASPP,并把主干网络从VGG-16换成了ResNet-101,同时增加了一些训练中的tirck。
细节
ASPP
本文提出了空洞空间卷积池化金字塔Atrous spatial pyramid pooling (ASPP),通过并行的采用多个不同采样率的空洞卷积层来检测,以多个比例捕捉对象以及图像上下文。
首先空洞卷积相当于是一个更大卷积核的卷积,那么设定好padding之后,不管是多少空洞率,都能得到相同尺寸的的特征图,最后将这些特征图做融合就好了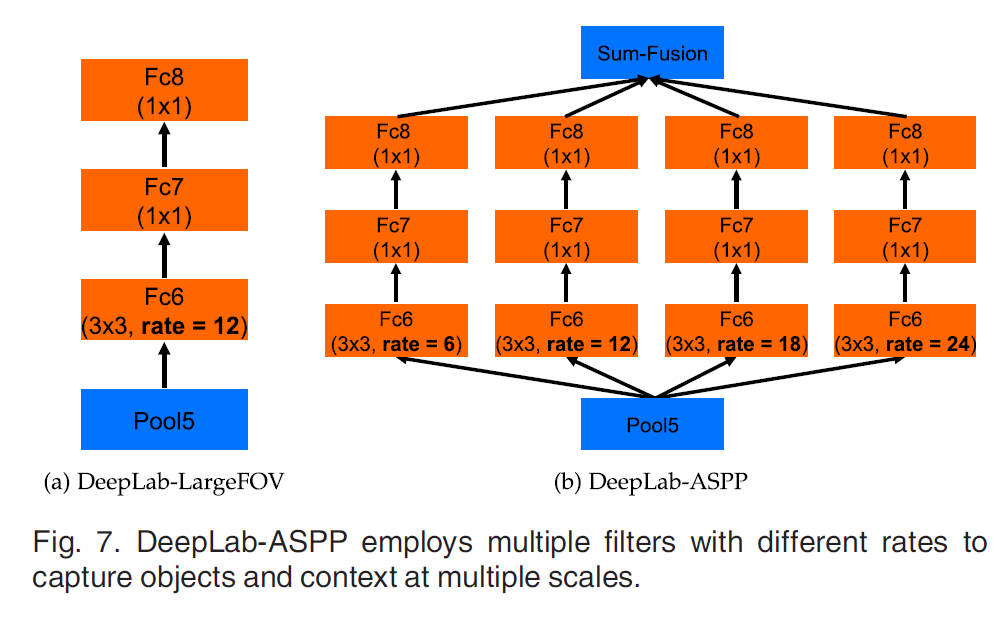
边栏推荐
猜你喜欢
C#实现访问OPC UA服务器

数学建模学习视频及资料集(2022.08.10)
PyTorch multi-machine multi-card training: DDP combat and skills
![[JS Advanced] Creating sub-objects and replacing this_10 in ES5 standard specification](/img/3e/14a1d7c2837c896eaa0ca625eaa040.png)
[JS Advanced] Creating sub-objects and replacing this_10 in ES5 standard specification
2022年网络安全培训火了,缺口达95%,揭开网络安全岗位神秘面纱

这一次,话筒给你:向自由软件之父斯托曼 提问啦!
laravel 抛错给钉钉
王学岗—————————哔哩哔哩直播-手写哔哩哔哩硬编码录屏推流(硬编)(26节课)

产品使用说明书小程序开发制作说明
MySQL - 数据库的存储引擎
随机推荐
符合信创要求的堡垒机有哪些?支持哪些系统?
串口服务器调试助手使用教程,串口调试助手使用教程【操作方式】
普林斯顿微积分读本05第四章--求解多项式的极限问题
2011年下半年 系统架构设计师 下午试卷 II
文件系统设计
力扣解法汇总640-求解方程
【有限元分析】异型密封圈计算泄漏量与参数化优化过程(带分析源文件)
基于ArcGIS水文分析、HEC-RAS模拟技术在洪水危险性及风险评估
格式化输出当前时间
How does vue clear the tab switching cache problem?
MySQL - storage engine for databases
使用mysq语句操作数据库
重要通知 | “移动云杯”算力网络应用创新大赛初赛延期!!
王学岗————直播推流(软便)03x264集成与camera推流
作业
[JS Advanced] Creating sub-objects and replacing this_10 in ES5 standard specification
SWIG教程《二》
Vivado crashes or the message is not displayed
mysql进阶(三十三)MySQL数据表添加字段
蓝帽杯半决赛火炬木wp