当前位置:网站首页>MySQL interview questions
MySQL interview questions
2022-08-10 13:32:00 【PHP Bai Xiaobai】
- What should you pay attention to when creating a table?
- Take care to use the appropriate storage engine:读多写少使用Myisam Write More Read Less UseInnoDB It is only used as a temporary intermediate table and can be usedMemory ;
- Avoid empty fields(null)的时候,You can add a default value for each field,提高查询的效率;
- Access time type of field we can use a timestamp type storage;而不去使用date或者是datetime;
- 在SQLFields that are frequently used in the statement,Or a foreign key to build a suitable index,提高查询的效率;
- 如果使用InnoDBThe table must have a primary key,Avoid the operation of adding a hidden column at the bottom of the database;
- Field types also need attention,比如:enum使用tyint代替,ID card and mobile phone number use fixed lengthchar存储,If the data is not a negative word can use unsigned types for storage
- 数据类型的区别:char和varchar,int(10)和int(11)?
- Char和varchar:
- charis stored in fixed length,varcharis stored variable length;
- char查询效率比varchar查询效率快;
- charWhen the stored length is less than the set length, it is filled with spaces,varcharWhen the stored length is less than the set length, only the occupied length is allocated;
- int(10)和int(11):int(10)和int(11)Just the length of the display is different,Actually the allocated size is the same;
- 主键索引和唯一索引?
- There is only one primary key index in a table,唯一索引可以有多个;
- 主键索引不能为空,唯一索引可以为空;
- Primary key creation must create a unique index,But a unique index does not create a primary key index;
- Primary key indexes can be used as foreign keys,But unique index doesn't work;
- The primary key index is essentially a constraint,But the primary key index is a kind of index;
- 主键采用自增id(int)还是UUID(varchar)?
- 自增idIn the process of adding, it is sequentially auto-incrementing,UUID是随机的;
- 自增id查询的效率比UUID快;
- uuidLarger storage space can easily lead to memory fragmentation;
- UUIDMore suitable for use in distributed scenarios;
- count(*)和count(字段)区别?
- Take precedence when using aggregate functionscount(*),Because the official has done optimization;
- If the field is indexed,可以使用count(字段)
- 脏读、幻读、不可重复读?
- Dirty read corresponds to database isolation level read uncommitted:事务A和事务BOperate the same data transactionA修改未提交,这个时候事务Bread uncommitted data,这就是脏读;
- Phantom read corresponds to read committed:Phantom read notice to write operation,事务AModify the status of all data to1,After modifying this time to view the data,同时事务BAdded a data status as0,A phantom read phenomenon;
- Not repeatable read corresponding repeatable read,事务ARead once the data is modified in the middle and then read it again and find that the data is inconsistent,这就是不可重复读
- Three paradigms and four characteristics and four isolation levels of transactions?
三大范式:
- 第一范式:Each column is a single attribute,不可再分割;
- 第二范式:在第一范式的基础上,The other columns are completely dependent on the primary key,不能只依赖于主键的一部分;
- 第三范式:在第二范式的基础上,消除传递依赖,Only depends on the primary key does not depend on other than the primary key
四大特性:
- 原子性:All transactions succeed or all fail(回滚);
- 一致性:The total amount before and after the transaction does not change,比如:转账事务AThere are five hundred affairsBalso five hundred,事务Atransfer to transactionBThree hundred this time the sum must be1000,Otherwise it's not consistency;
- 持久性:Changes to the database after the transaction is committed are persistent;
- 隔离性:Multiple transactions submitted at the same time each other
四大隔离级别:
- 读未提交:The data has been modified but the data has not been submitted,会造成:脏读、幻读、不可重复读
- 读已提交:Modified Read Committed,会造成:幻读、不可重复读
- 可重复读:Consistent results for multiple reads,unless modified by transaction,会造成:幻读(MySQL默认隔离级别)
- 串行化:最高隔离级别,Transactions are executed sequentially to avoid all reads
- Indexing Scenarios?联合索引?
Indexing Scenarios:
- Add an index based on the data size of the table,Usually, when the data in the table is greater than 300 or 500, you can consider adding an index.;
- SQLCommonly used in sentences withwhere、order by、group by查询的字段;
- 如果使用InnoDBThe engine needs to set a primary key,SQLThe statement needs to create an index for the foreign key;
- 避免索引失效的场景;
联合索引:
- Follow the leftmost principle when creating a joint index(Only the leftmost index is hit first before the next index can be hit);
- When the joint index is set in order,Put the most queries on the leftmost and decrease in turn;
- In case of range queries joint index when there will be a failure;
- 索引失效的场景?
- When avoiding ambiguous queries%In the field before;
- 避免在SQL进行表达式的计算;
- can be used in subqueriesExists进行替换;unin替代or
- 避免隐式类型转换;
- InnoDB和Myisam的区别?
- Innodb支持事务,myisam不支持
- Innodb支持外键,myisam不支持
- Innodb支持行级锁,myisam支持表级锁
- Innodb使用的是聚簇索引,myisam使用的是非聚簇索引
- Innodb表文件:.frm,idb,myisam表文件:.frm,.myi,.myd
- 慢查询?Explain分析SQL语句性能?
- Parameters set by slow query:slow_query_log(开启慢查询),slow_query_time(时间,Recorded beyond this time),log_queries_not_using_index(Query if unused indexes)
- ExplainSeveral parameters of main concern:selece_type,type,是否命中索引,rows,extra
Type:system>const>ref>range>index>all

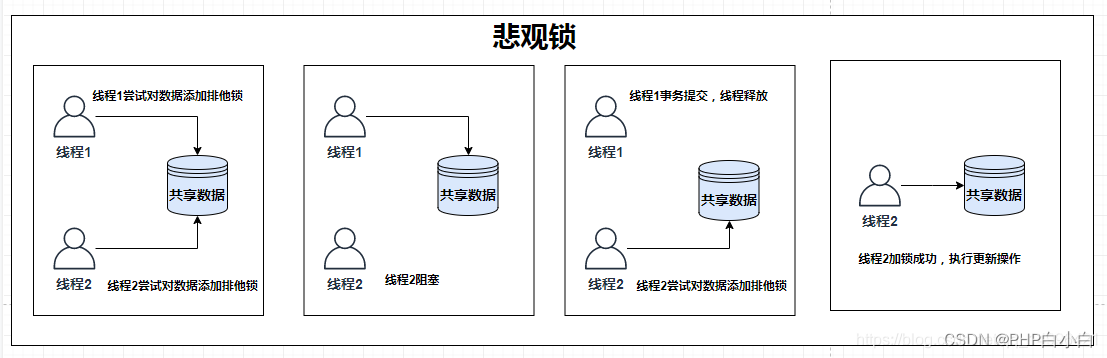
悲观锁和乐观锁:乐观锁的CAS和ABAProblems and application scenarios?
悲观锁阻塞事务,乐观锁回滚重试
悲观锁:When multiple transactions compete for the same resource,加上悲观锁,A transaction is scrambled to only wait for the transaction to commit,Otherwise everything else is in a blocking state.
It is suitable for the scenario of writing more and reading less
乐观锁:Multiple transactions do not affect each other when reading,If you want to modify the data, you need to read it first,Read the play data and then modify it according to the read data,Then check whether the version number is the same when submitting,Consistent commit,Inconsistent rollback retry;
适用于读多写少的场景下

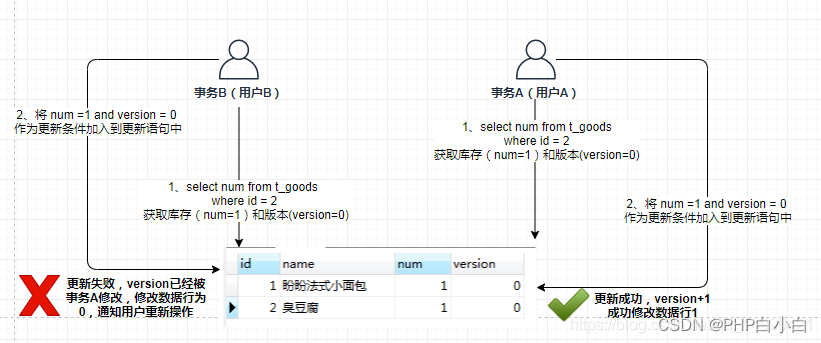
乐观锁的CAS?即比较并替换,在CPUIt seems to be a momentary thing
ABA问题?所谓的ABAIs part of a optimistic locking problems,When the transaction is committed, it is found to be consistent with the original information,At this point we think we can submit,But it is possible that the data is changed during the submission process. This is calledABA问题;The solution is to add aversion版本号
- 聚簇索引和非聚簇索引?
Mysql底层使用b+treeas an index,Clustered and non-clustered indexes are implementations of concrete indexes;
innodbThe engine uses a clustered index,As the files generated each time a table is created can be seen:.frm(表结构),.idb(索引和数据)
myisamThe engine uses a non-clustered index,Because the file generated each time a table is created is:.frm,.myi(存储索引),.myd(存储数据)
- Clustering index in leaf index and data storage;
- Non-clustered indexes store indexes,To get specific data, you need to get the index first,fetching data by index(回表);
- B-tree和B+tree的区别?
b-tree(单向链表):
- Key values are distributed over leaves and non-leafs;
- Meet with range queries,You need to search from the root node every time,增加了I/O的内存消耗;
- The fastest query isO(1);
B+tree(双向链表):
- Values are stored in leaf nodes,非叶子结点存储的是键;
- same query speed,need to search on leaf nodes;
- A leaf node also stores a value pointing to an adjacent leaf node,也就是说B+tree天然支持范围查询;
- Mysql的日志?
Mysql日志:二进制日志,回滚日志,普通日志,中继日志,重做日志;
- Operation and application scenarios of sub-database and sub-table?
- Sub-library and sub-table are usually divided into:水平拆分和垂直拆分
水平拆分:表(库)结构相同,数据不同,没有交集,并集是全量数据
垂直拆分:表结构不同,数据不同,Intersection is the associated foreign key,并集是全量数据
- 拆分的方法:id取模,or ranged insertion
Id取模Difficulties will result in the late extension,假设id原本是%5,If you want to expand the table later,需要%8There is a problem with the data;
范围查询也有一定问题,The newly inserted data is in a new table,It will not be evenly divided into each table like the modulo;
- 什么是死锁?怎么避免?(解决)
- Two transactions compete for the same resource,And lock the other resources request waiting for each other;事务A修改数据id1和2,事务B修改数据id2和1,事务A修改完1等待事务B修改完2才可以提交,而这个时候事务B Waiting transactions also appearedAThen there will be a deadlock;
- 怎么解决:
- Agreed to access tables in the same order;
- At the beginning of the transaction, try to lock all the required resources at once;
- Use optimistic locking or distributed locking;
- 升级锁粒度;
- MVCC机制?
MVCCThe full name is called multi-version concurrency control,主要是基于InnodbEngine and Repeatable Read and Read Committedisolation level implementation;
核心逻辑:Determine which transaction among all uncommitted transactions is the visible processing of the current transaction;
Trx_id:The hidden column of the table records the modification transactionid
Roll_pointer:Pointer to record the previous address
快照:The query is executed,List of generated uncommitted transactions
Compare against a list of snapshots,Whether the transaction can be read,If the access is not available, take the last read address according to the rollback pointer;
规则:
当前事务id<Minimum transaction for transaction listid,Indicates that it has been submitted and can be accessed before the snapshot is generated;
当前事务id>The largest transaction of the transaction listid+1,Indicates that the transaction committed after the snapshot is generated cannot be accessed;
当前事务idin the transaction list,Determine whether it has been submitted and can be accessed if submitted,If you don't submit it, you can't access it;
注:读已提交的隔离级别下,A snapshot is generated for each query,
可重复读的隔离级别下,Only the snapshot generated by the first query,Subsequent reads reuse the snapshot generated for the first time
- 主从复制:GTID?半同步模式?主从延迟?

主从复制的工作原理:
The operations of additions, deletions and modifications to the master node will be recorded in thebinlog日志中,然后发送一个dump通知slave结点,
Slavenode to readbinloglog dump torelay log(中继日志)中,然后slaveNode opens aSQLThread to execute relay log file,Achieving the effect of a master-slave replication;
什么是GTID?即全局事务id
Gtid是在mysql5.6A heavyweight feature released after the version,Unlike traditional master-slave replication,When copying from the library, you don't need to look for itmaster文件,Just need to know the businessid,根据这个idnode to execute,It is guaranteed that each transaction will only be executed once;
半同步策略:mysqlDefault is asynchronous strategy,Semi-synchronous is based on a kind of between synchronous and asynchronous,just wait for oneslaveThe node can return by writing to the relay log;
The reason for the master-slave delay?
- 网络延迟;
- 数据库负载过高;
- Bad hardware;
如何解决主从延迟问题?
- Master-slave replication serial replication to parallel replication;
- Adopt semi-synchronous replication strategy;
- Improve hardware facilities;
(3条消息) MySQL八股文连环45问,你能坚持第几问?_IT邦德的博客-CSDN博客_mysql45问
小白都能懂的Mysql主从复制原理(原理+实操) - 知乎 (zhihu.com)
- 如何避免回表?什么是索引覆盖?
假设查询name值为lisi,Need to locate the primary key first,locate the data by the primary key,这就是回表查询;
Index coverage can avoid back to the table,Index coverage means that the fields in the query are all set with indexes,If you query multiple fields, you can set a joint index
如何避免回表查询?什么是索引覆盖? | 1分钟MySQL优化系列 (qq.com)
- 查询优化器?
- 实际应用场景:大分页?
Huge paging scenario:
比如执行SQLexecutes aselect * from users limit 100000,10这样的SQL语句;
In order to ensure the optimization of the query, we can perform aSQL语句的优化,The location of the record when the last page,When paging, fetch directly from the position of the last paging
Select * from users where id>=100000 limit 10
边栏推荐
- Cloud Migration Practice of Redis
- Proprietary cloud ABC Stack, the real strength!
- tampercfg内核模块导致机器频繁crash
- kubernetes介绍
- Reversing words in a string in LeetCode
- Interface Automation Testing Basics
- Jenkins修改默认主目录
- LeetCode medium topic search of two-dimensional matrix
- [Advanced Digital IC Verification] Difference and focus analysis between SoC system verification and IP module verification
- 开源SPL消灭数以万计的数据库中间表
猜你喜欢

BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes

bgp双平面实验 路由策略控制流量

商汤自研机械臂,首款产品是AI下棋机器人:还请郭晶晶作代言

AWS 安全基础知识

2022 Recruitment Notice for Academician Zhao Guoping Group of Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
Stream通过findFirst()查找满足条件的一条数据

Open Office XML 格式里如何描述多段具有不同字体设置的段落
【目标检测】小脚本:提取训练集图片与标签并更新索引
SenseTime self-developed robotic arm, the first product is an AI chess-playing robot: Guo Jingjing is also invited as an endorsement

DNS欺骗-教程详解
随机推荐
NodeJs原理 - Stream(二)
Loudi Sewage Treatment Plant Laboratory Construction Management
日志@Slf4j介绍使用及配置等级
kubernetes介绍
一种能让大型数据聚类快2000倍的方法,真不戳
MYSQL误删数据恢复
the height of the landscape
Loudi Cosmetics Laboratory Construction Planning Concept
C# InitializeComponent() does not exist in the current context
C# error The 'xmins' attribute is not supported in this context
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes
交换机的基础知识
[target detection] small script: extract training set images and labels and update the index
借数据智能,亚马逊云科技助力企业打造品牌内生增长力
CodeForces - 811A
Jiugongge lottery animation
How to describe multiple paragraphs with different font settings in Open Office XML format
浙大、阿里提出DictBERT,字典描述知识增强的预训练语言模型
Borg Maze (bfs+最小生成树)
递归递推之计算组合数