当前位置:网站首页>Q-Learning & Sarsa
Q-Learning & Sarsa
2022-04-23 02:56:00 【Live up to your youth】
Basic concepts
Markov decision process
Markov decision process is simply an agent (Agent) take action (Action) To change your state (State) Get rewards (Reward) And the environment (Environment) The cyclic process of interaction .
Markov decision process, which can be simply expressed as : M = < S , A , P ( s ′ ∣ s , a ) , R > M=<S, A, P(s'| s, a),R> M=<S,A,P(s′∣s,a),R>
among P ( s ′ ∣ s , a ) P(s'| s, a) P(s′∣s,a) Representation transformation model , If we choose an action in a certain state , We will enter the next state . This is usually expressed as a table P. If we are in a state s And we choose an action a, that s ′ s' s′ The probability of becoming the next state is P ( s ′ ∣ s , a ) P(s'| s, a) P(s′∣s,a).
Reinforcement learning
Simply speaking , Reinforcement learning is that individuals in the environment make a series of decisions according to certain strategies to complete a given task and get rewards , Find the optimal strategy to maximize the return .
Reinforcement learning is similar to dynamic programming , But unlike dynamic programming , Reinforcement learning repeatedly uses the experience of the previous learning process , Dynamic programming is just the opposite , Assume a full understanding of the environment in advance .

The model of reinforcement learning is shown above , Individuals give actions action, The environment gives the status state And reward reward For feedback ; Then the individual gives a new action action, The state of the environment state It will change again , There will be new rewards reward. This circular process is the idea of strengthening learning . So , Reinforcement learning is essentially a process in which individuals constantly try and make mistakes in the environment and use the delayed return of the environment to learn .
Q-Learning
Q-Learning Algorithm is one of the main algorithms of reinforcement learning , It provides a learning ability for agents to select the best action by using the experienced action sequence in Markov environment , The interaction process between agent and environment is regarded as a Markov decision process (MDP), According to the current state of the agent and the selected action , Determine a fixed state transition probability distribution 、 Next state and get a timely return . The goal is to find a strategy that maximizes future rewards .

Q-Learning The mathematical model used by the algorithm is shown in the figure above , In the right half of the formula , Q ( s , a ) Q(s,a) Q(s,a) Express Q The memory return in the table , r r r Indicates according to the action a a a And status s s s The current return , m a x Q ( s ′ , a ∗ ) maxQ(s',a^*) maxQ(s′,a∗) Next state and optional action set a ∗ a^* a∗ Select the largest Q Value corresponding a ′ a' a′. α \alpha α It means the learning rate , It can be seen from the formula that , The lower the learning rate , The more the robot cares about the return before , Instead of accumulating new returns . γ \gamma γ Represents the discount factor , Is a factor that considers the impact of future rewards on the present , It's a (0,1) Between the value of the .
Hypothetical use r + γ Q ( s ′ , a ∗ ) r +\gamma Q(s',a^*) r+γQ(s′,a∗) The real value of , Q ( s , a ) Q(s,a) Q(s,a) Represents the estimated return value , Then the model updating method : New returns = (1- α \alpha α) Estimated return + α \alpha α * Realistic return .
Q-learning The pseudo code of the algorithm is shown in the figure below :

Sarsa
Sarsa Algorithm and Q-Learning The algorithm is very similar ,‘sarsa’ The meaning of five letters is s( current state ),a( Current behavior ),r( Reward ),s( Next state ),a( The next step is ), In other words, we have thought of the current situation when we carry out this step s Corresponding a, And figured out the next one s’ and a’.Sarsa The mathematical model used is as follows :
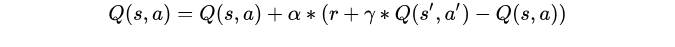
Sarsa The pseudo-code of the algorithm is as follows :

Q-learning and Sarsa Different :
Q-learning Algorithm and Sarsa Algorithms are from the State s Start , Based on the current Q-table Use certain strategies ( ϵ − g r e e d y \epsilon-greedy ϵ−greedy) Choose an action a ′ a' a′, Then observe the next state s ′ s' s′, And again according to Q-table Choose action a ′ a' a′. Just choose between the two a’ Different methods . According to the algorithm description , Select a new state s ′ s' s′ The action of a ′ a' a′ when ,Q-learning Use greedy tactics ( ϵ − g r e e d y \epsilon-greedy ϵ−greedy), That is, select the one with the largest value a ′ a' a′, At this point, we just calculate which a ′ a' a′ You can make m a x Q ( s ′ , a ∗ ) maxQ(s',a^*) maxQ(s′,a∗) Take the maximum , Did not really use this action a ′ a' a′; and Sarsa Still use ϵ − g r e e d y \epsilon-greedy ϵ−greedy Strategy , And really adopted this action a ′ a' a′ .
版权声明
本文为[Live up to your youth]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220657127253.html
边栏推荐
- Solve the problem that PowerShell mining occupies 100% of cpu7 in win7
- Store consumption SMS notification template
- If MySQL / SQL server judges that the table or temporary table exists, it will be deleted
- Mosaic Routing: implement / home / news
- JZ22 鏈錶中倒數最後k個結點
- 《信息系統項目管理師總結》第六章 項目人力資源管理
- 解决win7 中powershell挖矿占用CPU100%
- Windows MySQL 8 zip installation
- 接口请求时间太长,jstack观察锁持有情况
- 重大危险源企业如何保障年底前完成双预防机制数字化建设任务
猜你喜欢

Machine learning (Zhou Zhihua) Chapter 14 probability graph model

Domestic lightweight Kanban scrum agile project management tool

Processes and threads

Devil cold rice 𞓜 078 devil answers the market in Shanghai and Nanjing; Communication and guidance; Winning the country and killing and screening; The purpose of making money; Change other people's op

Liunx foundation - zabbix5 0 monitoring system installation and deployment
Fashion MNIST dataset classification training

基于ele封装下拉菜单等组件

Kubernetes - Introduction to actual combat

It turns out that PID was born in the struggle between Lao wangtou and Lao sky

Traversal of l2-006 tree (middle and later order determination binary tree & sequence traversal)
随机推荐
Log4j knowledge point record
Specific field information of MySQL export table (detailed operation of Navicat client)
Regular object type conversion tool - Common DOM class
Day 4 of learning rhcsa
Decision tree principle of machine learning
Introduction to ACM [inclusion exclusion theorem]
The shell monitors the depth of the IBM MQ queue and scans it three times in 10s. When the depth value exceeds 5 for more than two times, the queue name and depth value are output.
Airtrack cracking wireless network password (Dictionary running method)
Niuke white moon race 6 [solution]
JDBC JDBC
JS learning notes
机器学习(周志华) 第十四章概率图模型
Huashu "deep learning" and code implementation: 01 Linear Algebra: basic concepts + code implementation basic operations
BLDC double closed loop (speed PI + current PI) Simulink simulation model
Kubernetes study notes
重大危险源企业如何保障年底前完成双预防机制数字化建设任务
《信息系统项目管理师总结》第四章 项目成本管理
win查看端口占用 命令行
解决win7 中powershell挖矿占用CPU100%
Navicat premium import SQL file