当前位置:网站首页>spark学习笔记(九)——sparkSQL核心编程-DataFrame/DataSet/DF、DS、RDD三者之间的转换关系
spark学习笔记(九)——sparkSQL核心编程-DataFrame/DataSet/DF、DS、RDD三者之间的转换关系
2022-08-10 19:01:00 【一个人的牛牛】
目录
RDD<=>DataSet<=>DataFrame转换编码实现
前言
Spark SQL可以理解为Spark Core的一种封装,在模型上和上下文环境对象上进行了封装;
SQLContext查询起始点:用于Spark自己提供的SQL查询;
HiveContext查询起始点:用于连接Hive的查询。
SparkSession:是Spark最新的SQL查询起始点,是SQLContext和HiveContext的组合,在 SQLContex和HiveContext上可用的API在SparkSession上同样是可以使用的。
注:Spark Core首先构建上下文环境对象SparkContext才可以执行应用程序,sparkSQL和spark core类似。使用spark-shell的时候, spark框架会自动创建一个名称叫做spark的SparkSession对象, 就像我们以前可以自动获取到一个sc来表示SparkContext对象一样。

DataFrame
创建DataFrame
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:
(1) 从spark数据源创建
spark支持创建的数据源格式:csv format jdbc json load option options orc parquet schema
table text textFile
在bin目录下创建input目录,在input目录下创建user.json,内容为:
{"username":"zj","age":20}
{"username":"xx","age":21}
{"username":"yy","age":22}
读取bin/input/user.json文件
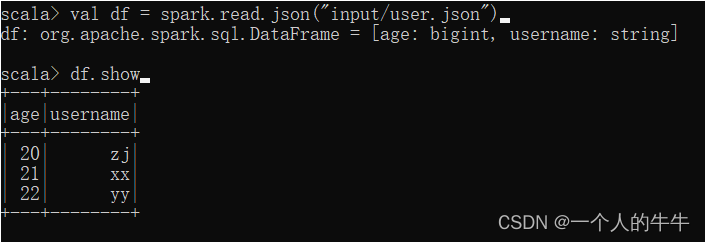
(2)从RDD转换
(3)从hive table查询返回
SQL语法
SQL语法是指查询数据的时候使用SQL语句查询,这种查询必须要有临时视图或全局视图来辅助。
(1)读取json文件
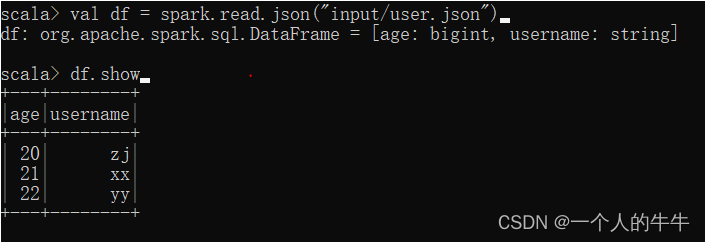
(2)创建临时表

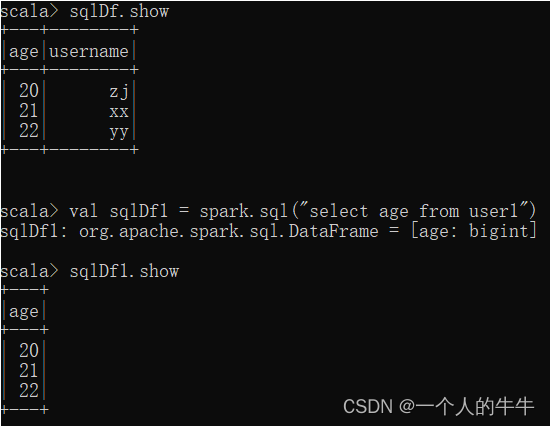
(3)实现查询
(4)创建全局表
df.createOrReplaceGlobalTempView("user2")![]()
注:普通临时表是Session范围内的;如果想扩大有效应用范围,可以使用全局临时表。使用全局临时表时需要全路径访问,global_temp.user2
(5)实现查询
#查询
spark.sql("select * from global_temp.user2").show()
#使用新的session查询
spark.newSession().sql("select * from global_temp.user2").show()
spark.newSession().sql("select age from global_temp.user2").show()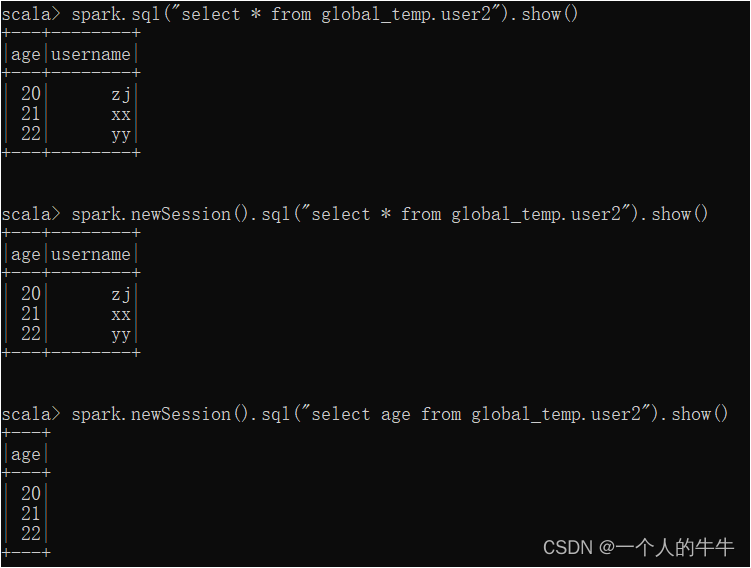
DSL语法
DataFrame提供一个特定领域语言DSL(domain-specific language)去管理结构化的数据。可以在Scala, Java, Python、R中使用DSL,使用DSL语法不用去创建临时视图。
(1)创建DataFrame
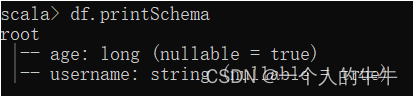
(2)查看DataFrame的schema信息
(3)查看数据
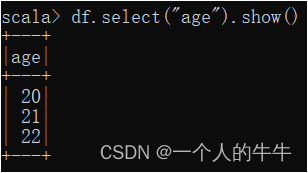
1)查看age数据
2)查看username和age+1数据

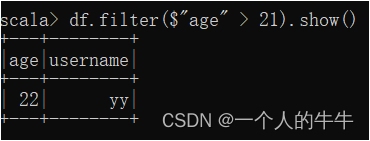
3)filter查看大于21数据
4)groupBy按age分组查看数据条数
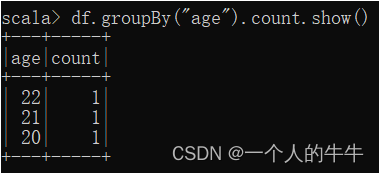
RDD转换为DataFrame
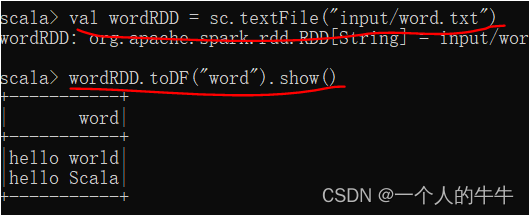
(1)sc.textFile创建RDD,转换为DataFrame
val wordRDD = sc.textFile("input/word.txt")
wordRDD.toDF("word").show()
(2)makeRDDR创建RDD并直接转换为DataFrame
case class user(name:String,age:Int)
sc.makeRDD(List(("zj",20),("zx",21),("xc",23))).map(t => user(t._1,t._2)).toDF.show()
注:在IDEA中开发程序时,如果需要RDD与DF或者DS之间互相操作,那么需要引入import spark.implicits._
import spark.implicits._:必须先创建SparkSession对象再导入,这里的spark是创建的sparkSession对象的变量名称。Scala只支持val修饰的对象的引入,切记这里的spark对象不能使用var声明。
spark-shell自动完成此操作。
DataFrame转换为RDD
DataFrame其实就是对RDD的封装,可以直接获取内部的RDD。
(1)创建RDD并转换为DataFrame,DataFrame转换为RDD
val df = sc.makeRDD(List(("zj",20),("zx",21),("xc",23))).map(t => user(t._1,t._2)).toDF
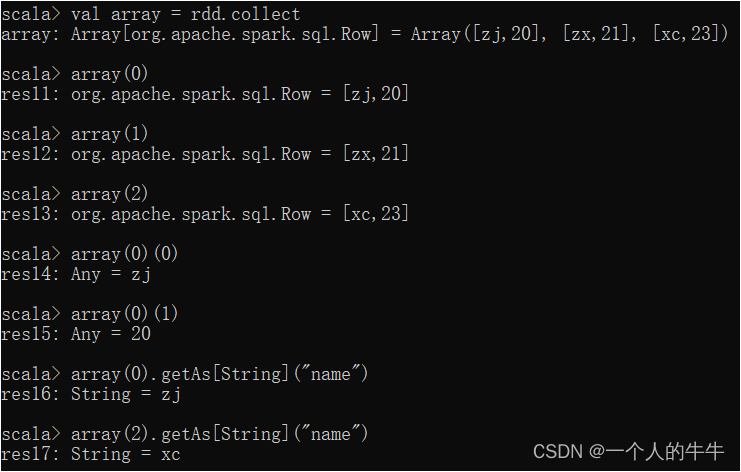
val rdd = df.rdd
(2)RDD的collect操作
DataSet
创建DataSet
(1)使用样例类序列创建DataSet
case class person(name:String,age:Long)
val caseClassDS = Seq(person("zj",2)).toDS()
caseClassDS.show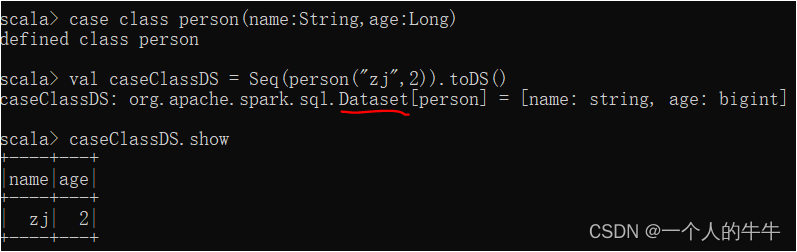
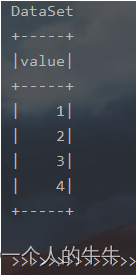
(2)使用基本类型的序列创建DataSet
val ds = Seq(1,2,3,4).toDS
ds.show 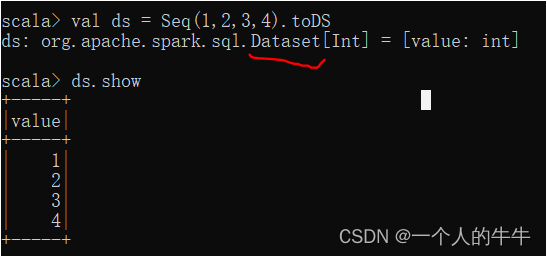
RDD转换为DataSet
SparkSQL能够自动将包含有case类的RDD转换成DataSet,case类定义了table的结构,case类属性通过反射变成了表的列名。case类可以包含诸如Seq、Array等复杂的结构。
注:实际中很少把序列转换成DataSet,更多的是通过RDD来得到DataSet。
case class user(name:String,age:Int)
sc.makeRDD(List(("zj",21),("zz",22),("xx",24))).map(t => user(t._1,t._2)).toDS
DataSet转换为RDD
DataSet也是对RDD的封装,可以直接获取内部的RDD。
#创建RDD并转换为DataSet
case class user(name:String,age:Int)
val ds = sc.makeRDD(List(("zj",21),("zz",22),("xx",24))).map(t => user(t._1,t._2)).toDS
#DataSet转换为RDD
val rdd = ds.rdd
#RDD的collect操作
rdd.collect
DataSet和DataFrame的转换
DataFrame是DataSet的特例,它们之间可以互相转换。
(1)DataFrame转换为DataSet
val df = sc.makeRDD(List(("zj",21),("zz",22),("xx",24))).map(t => user(t._1,t._2)).toDF("name","age")
val ds = df.as[user]
(2)DataSet转化为DataFrame
val df = ds.toDF
RDD、DataFrame、DataSet之间的关系
相同点
(1)三者都有partition的概念;
(2)三者有许多共同的函数,如map、filter等;
(3)RDD、DataFrame、DataSet全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
(4)三者都有惰性机制,在进行创建转换时不会立即执行,只有在遇到Action时三者才会开始运算;
(5)在对DataFrame和Dataset进行操作许多操作都需要这个包import spark.implicits._;
(6)三者都会根据Spark的内存情况自动缓存运算,即使数据量很大,也不用担心内存溢出;
(7)DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型。
区别点
(1)RDD不支持sparksql操作;
(2)RDD一般和spark mllib同时使用;
(3)DataFrame和DataSet一般不与spark mllib同时使用;
(4)DataFrame与DataSet支持一些特别方便的保存方式,比如:csv,csv可以带上表头;
(5)DataFrame与RDD和Dataset不同,每一行的类型固定为Row,每一列的值没法直 接访问,只有通过解析才能获取各个字段的值;
(6)DataFrame与DataSet均支持SparkSQL的操作,还能注册临时表/视窗进行sql语句操作;
(7)DataFrame和Dataset拥有完全相同的成员函数,区别只是每一行的数据类型不同,DataFrame就是DataSet的一个特例:type DataFrame = Dataset[Row]
(8)DataFrame每一行的类型是Row,不解析各个字段是什么类型无从得知,只能用模式匹配拿出特定字段;而Dataset中每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息。
相互转换
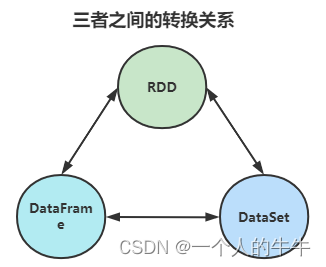
sparkSQL-IDEA编程
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>全部依赖展示
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--该插件用于把Scala代码编译成为class文件-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!--声明绑定到maven的compile阶段-->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>RDD<=>DataSet<=>DataFrame转换编码实现
下面是代码部分
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object sparkSQL_Basic {
def main(args: Array[String]): Unit = {
//TODO 创建sparkSQL运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//TODO 执行逻辑操作
//DataFrame
println("DataFrame")
val df = spark.read.json("datas/user.json")
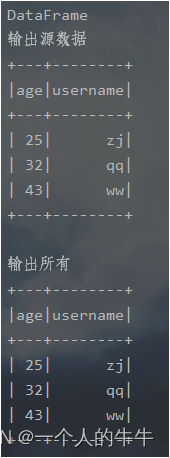
println("输出源数据")
df.show()
//DataFrame => SQL 要创建视图
df.createOrReplaceTempView("user")
println("输出所有")
spark.sql("select * from user").show()
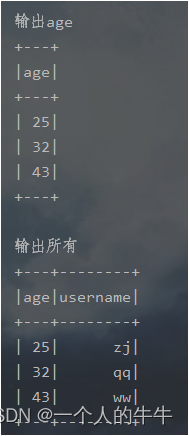
println("输出age")
spark.sql("select age from user").show()
//DataFrame => DSL 不用创建视图
println("输出所有")
df.select("age","username").show()
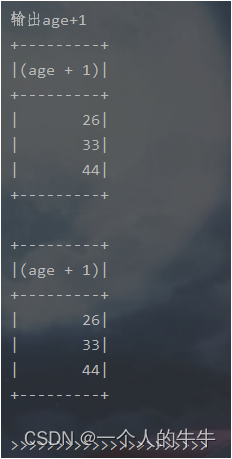
println("输出age+1")
df.select($"age" + 1).show()
df.select('age + 1).show()
println(">>>>>>>>>>>>>>>>>>>>>>")
//DataSet
println("DataSet")
val seq = Seq(1,2,3,4)
val ds = seq.toDS()
ds.show()
println(">>>>>>>>>>>>>>>>>>>>>>>>")
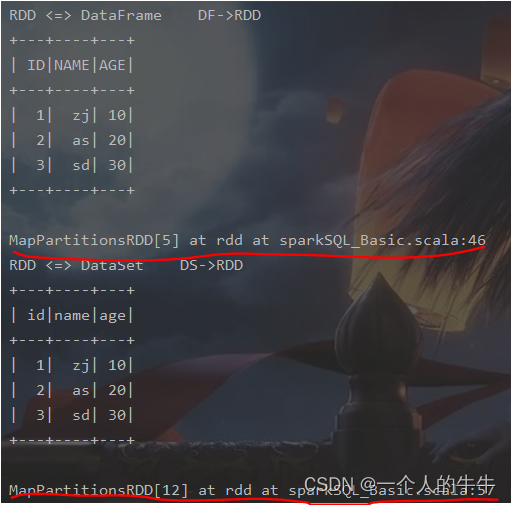
//RDD <=> DataFrame
println("RDD <=> DataFrame DF->RDD")
val rdd = spark.sparkContext.makeRDD(List((1,"zj",10),(2,"as",20),(3,"sd",30)))
val frame = rdd.toDF("ID", "NAME", "AGE")
val rowRDD : RDD[Row] = frame.rdd
frame.show()
println(rowRDD)
//RDD <=> DataSet
println("RDD <=> DataSet DS->RDD")
val ds2 = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
val userRDD = ds2.rdd
ds2.show()
println(userRDD)
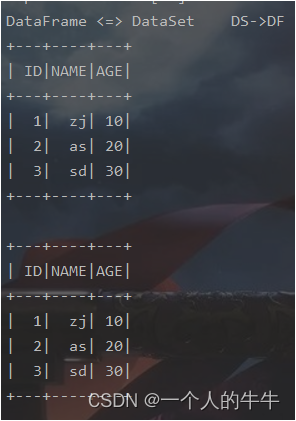
//DataFrame <=> DataSet
println("DataFrame <=> DataSet DS->DF")
val ds1:Dataset[User] = frame.as[User]
val df1:DataFrame = ds1.toDF()
ds1.show()
df1.show()
//TODO 关闭环境
spark.stop()
}
case class User(id:Int,name:String,age:BigInt)
}运行结果展示!
本文为学习笔记的记录!!
边栏推荐
- Site Architecture Detection & Chrome Plugin for Information Gathering
- QoS服务质量六路由器拥塞管理
- FPGA工程师面试试题集锦91~100
- 主动信息收集
- 『牛客|每日一题』岛屿数量
- FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec论文总结
- 谈谈宝石方块游戏中的设计
- Hangdian Multi-School Seven 1003-Counting Stickmen (Combination Mathematics)
- 端口探测详解
- 皮质-皮质网络的多尺度交流
猜你喜欢
多种深度模型实现手写字母MNIST的识别(CNN,RNN,DNN,逻辑回归,CRNN,LSTM/Bi-LSTM,GRU/Bi-GRU)

【知识分享】在音视频开发领域中SEI到底是个啥?
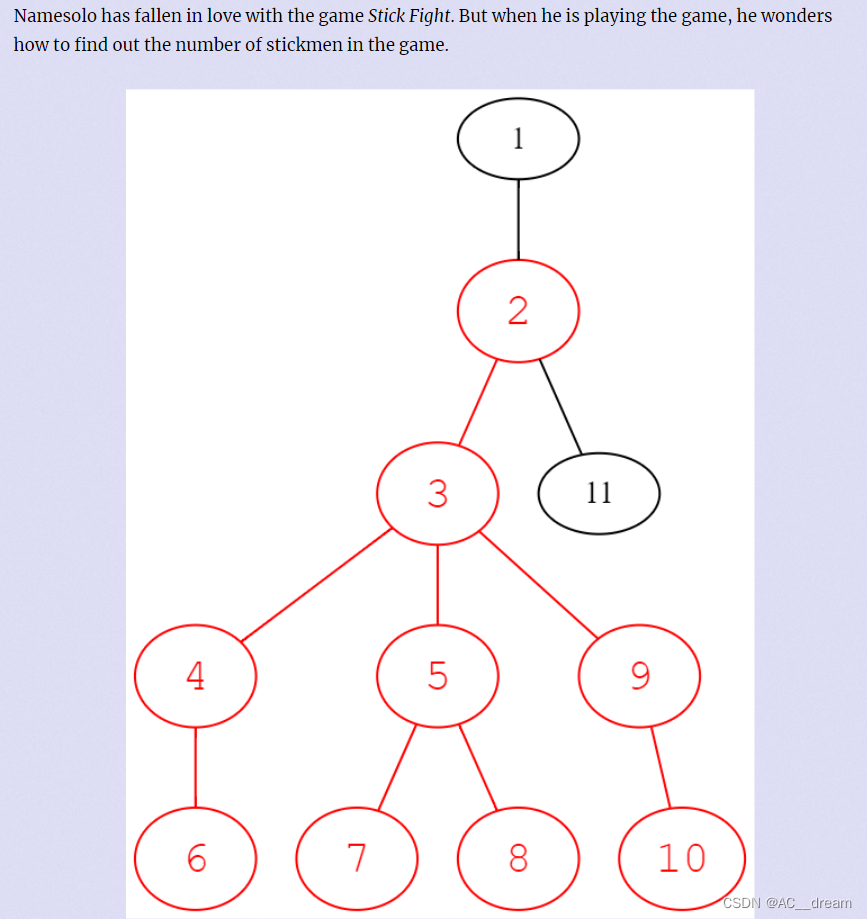
Hangdian Multi-School Seven 1003-Counting Stickmen (Combination Mathematics)
子域名收集&Google搜索引擎语法

『牛客|每日一题』岛屿数量
【Knowledge Sharing】What is SEI in the field of audio and video development?
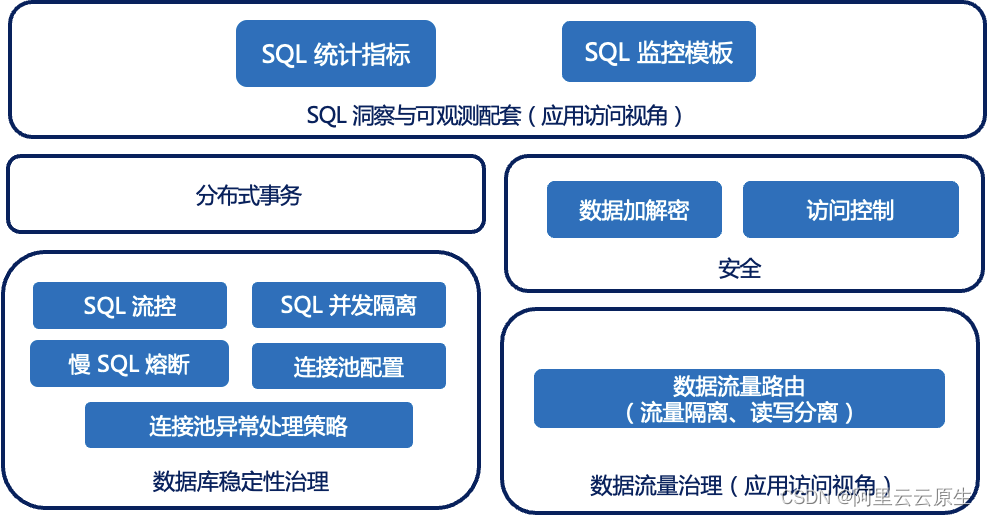
MSE 治理中心重磅升级-流量治理、数据库治理、同 AZ 优先

【OpenCV】-物体的凸包
The servlet mapping path matching resolution
MySQL安装步骤
随机推荐
网络虚拟化
【无标题】基于Huffman和LZ77的GZIP压缩
800. 数组元素的目标和(双指针)
机器学习|模型评估——AUC
Rider调试ASP.NET Core时报thread not gc-safe的解决方法
Win11连接投影仪没反应怎么解决?
[TAPL] 概念笔记
3D游戏建模学习路线
2816. 判断子序列(双指针)
MySQL安装步骤
FPGA工程师面试试题集锦71~80
argparse——命令行参数解析
Common ports and services
LeetCode·283.移除零·双指针
从 GAN 到 WGAN
dumpsys meminfo 详解
QoS服务质量七交换机拥塞管理
选择是公有云还或是私有云,这很重要吗?
产品思维训练 | 新用户从注册到绑卡流失率很高是什么原因?
TikTok选品有什么技巧?