当前位置:网站首页>[Natural Language Processing] [Vector Representation] PairSupCon: Pairwise Supervised Contrastive Learning for Sentence Representation
[Natural Language Processing] [Vector Representation] PairSupCon: Pairwise Supervised Contrastive Learning for Sentence Representation
2022-08-10 19:26:00 【BQW_】
论文地址:https://arxiv.org/pdf/2109.05424.pdf
相关博客:
【自然语言处理】【对比学习】SimCSE:基于对比学习的句向量表示
【自然语言处理】BERT-Whitening
【自然语言处理】【Pytorch】从头实现SimCSE
【自然语言处理】【向量检索】面向开发域稠密检索的多视角文档表示学习
【自然语言处理】【向量表示】AugSBERT:改善用于成对句子评分任务的Bi-Encoders的数据增强方法
【自然语言处理】【向量表示】PairSupCon:Pairwise Supervised Contrastive Learning for Sentence Representations
一、简介
Learning high-quality sentence embeddings is NLP \text{NLP} NLP中的基础任务.The goal is to map similar sentences to close locations in the representation space,Map dissimilar sentences to distant locations.A recent study passed in NLI \text{NLI} NLIThe training on the dataset was successful,The task on this dataset is to classify sentence pairs into one of three categories:entailment、contradiction或者neutral.
Although the results are not bad,But previous work has a drawback:构成contradictionThe right sentences may and need to belong to different semantic categories.因此,Differentiate by optimizing the modelentailment和contradiction,It is not enough for the model to encode high-level category concepts.此外,标准的siamese(triplet)The loss function can only learn from independent sentence pairs ( triplets ) (\text{triplets}) (triplets)中学习,It requires a large number of training samples to achieve competitive results.siameseLoss functions can sometimes bring the model into poor local optima,Its effect on high-level semantic concept encoding will be degraded.
在本文中,Inspired by self-supervised contrastive learning,And proposed joint optimization with instance discrimination (instance discrimination) \text{(instance discrimination)} (instance discrimination)The pairwise semantic inference objective function.The authors call this method Pairwise Supervised Contrastive Learning(PairSupCon) \text{Pairwise Supervised Contrastive Learning(PairSupCon)} Pairwise Supervised Contrastive Learning(PairSupCon).As mentioned in some recent research work,instance discrimination learningAbility to group similar instances nearby in the representation space without any explicit guidance. PairSupCon \text{PairSupCon} PairSupConTake advantage of this implicit grouping effect,Group together representations of the same class,While enhancing the semantics of the modelentailment和contradiction推理能力.
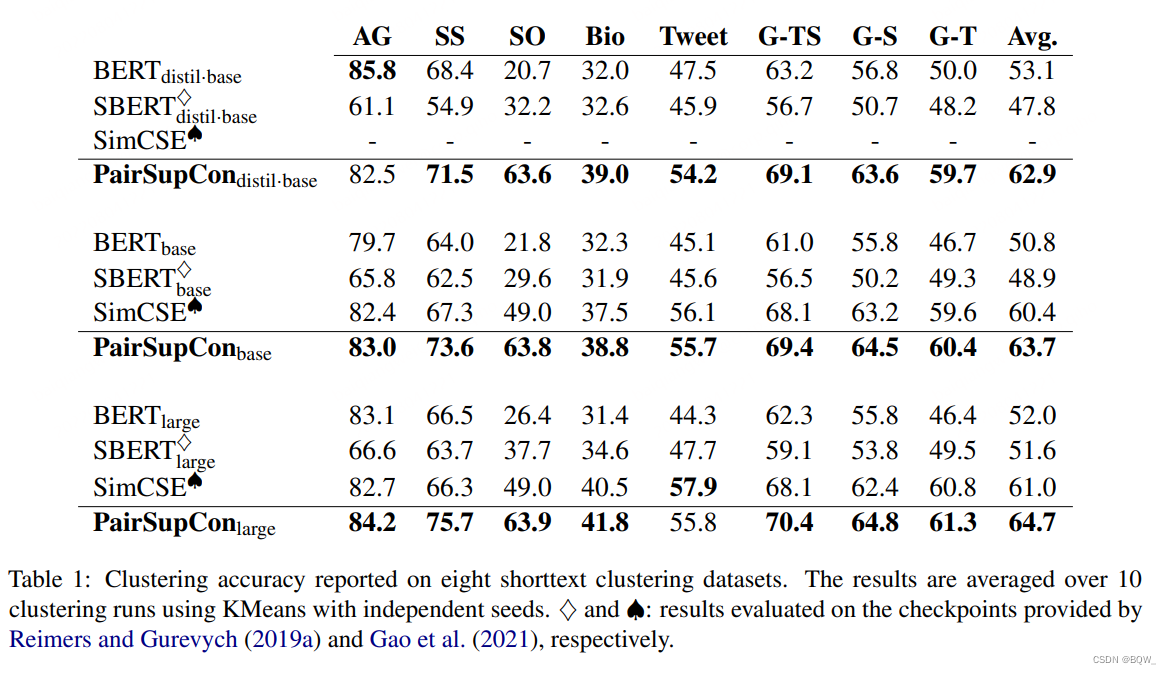
While previous work mainly focused on pairwise evaluation of semantic similarity.在本文中,The authors argue that encoding high-level semantic concepts into vector representations is also an important evaluation aspect.Previously on the Semantic Text Similarity Task STS \text{STS} STSThe best-performing model on top of the class leads to the degradation of the category semantic structure embeddings.另一方面,Better capture of high-level semantic concepts can in turn facilitate lower-level semanticsentailment和contradiction推理的效果.This assumption is consistent with humans classifying from the top down. PairSupCon \text{PairSupCon} PairSupCon在8Averaging is achieved in two short text clustering tasks10%-13%的改善,并且在 STS \text{STS} STS任务上实现了5%-6%的改善.
二、方法
遵循 SBERT \text{SBERT} SBERT,采用 SNLI \text{SNLI} SNLI和 MNLI \text{MNLI} MNLI作为训练数据,And for convenience the merged data is called NLI \text{NLI} NLI. NLI \text{NLI} NLIThe data consists of labeled sentence pairs,And each sample is of the form : (premise,hypothesis,label) \text{(premise,hypothesis,label)} (premise,hypothesis,label).每个 premise \text{premise} premiseSentences are all selected from existing text sources,并且每个 premise \text{premise} premiseThere will be various manual annotations hypothesis \text{hypothesis} hypothesisSentences form a pair.每个 label \text{label} label都表示 hypothesis \text{hypothesis} hypothesistypes and classifications premise \text{premise} premise和 hypothesis \text{hypothesis} hypothesisThe semantic relations of sentence pairs are of three types: entailment \text{entailment} entailment、 contradiction \text{contradiction} contradiction和 neural \text{neural} neural.
The previous work will be there NLI \text{NLI} NLIindependently optimizedsiamese loss或者triplet loss.The authors aim to exploit the implicit grouping effect in discriminative learning to better capture the high-level category semantic structure of the data,Simultaneously facilitates semantic text at a low levelentailment和contradictionBetter convergence of the recommended objective.
1. 实例判别( Instance Discrimination \text{Instance Discrimination} Instance Discrimination)
作者利用 NLI \text{NLI} NLIpositive sample pair (entailment) \text{(entailment)} (entailment)to optimize the instance-level discriminative objective function,It tries to distance each positive pair from other sentences.令 D = { ( x j , x j ′ ) , y j } j = 1 M \mathcal{D}=\{(x_j,x_j'),y_j\}_{j=1}^M D={(xj,xj′),yj}j=1MIndicates random samplingminibatch,其中 y i = ± 1 y_i=\pm 1 yi=±1表示entailment或者contradiction.对于正样本对 ( x i , x i ′ ) (x_i,x_i') (xi,xi′)中的premise句子 x i x_i xi,The goal here is tohypothesis句子 x i ′ x_i' xi′与同一个batch D \mathcal{D} D中的 2M-2 \text{2M-2} 2M-2separate sentences.具体来说,令 I = { i , i ′ } i M \mathcal{I}=\{i,i'\}_{i}^M I={ i,i′}iM表示 D \mathcal{D} DThe index corresponding to the sample in ,Minimize the loss function below:
l ID i = − log exp ( s ( z i , z i ′ / τ ) ) ∑ j ∈ I ∖ i exp ( s ( z i , z j / τ ) (1) \mathcal{l}_{\text{ID}}^i=-\log\frac{\exp(s(z_i,z_{i'}/\tau))}{\sum_{j\in\mathcal{I}\setminus i}\exp(s(z_i,z_{j}/\tau)} \tag{1} lIDi=−log∑j∈I∖iexp(s(zi,zj/τ)exp(s(zi,zi′/τ))(1)
在上面的等式中, z j = h ( ψ ( x j ) ) z_j=h(\psi(x_j)) zj=h(ψ(xj))Represents the output of the entity judgment header, τ \tau τ表示温度参数, s ( ⋅ ) s(\cdot) s(⋅)是cosine相似的,即 s ( ⋅ ) = z i ⊤ z i ′ / ∥ z i ∥ ∥ z i ′ ∥ s(\cdot)=z_i^\top z_{i'}/\parallel z_i\parallel\parallel z_{i'}\parallel s(⋅)=zi⊤zi′/∥zi∥∥zi′∥.等式(1)can be interpreted for classification z i z_i zi和 z i ′ z_i' zi′of the classification loss functionsoftmax.
类似地,对于hypothesis句子 x i ′ x_{i'} xi′,Try it from here D \mathcal{D} DDiscriminate in all other sentences in premise句子 x i x_i xi.因此,Define the corresponding loss function l ID i ′ \mathcal{l}_{\text{ID}}^{i'} lIDi′为等式(1)Exchange instance x i ′ x_{i'} xi′和 x i x_i xi的角色.总的来说,The final loss function is the average D \mathcal{D} Dall positive samples in .
L ID = 1 P M ∑ i = 1 M 1 y i = 1 ⋅ ( l ID i + l ID i ′ ) (2) \mathcal{L}_{\text{ID}}=\frac{1}{P_M}\sum_{i=1}^M\mathbb{1}_{y_i=1}\cdot(\mathcal{l}_{\text{ID}}^i+\mathcal{l}_{\text{ID}}^{i'}) \tag{2} LID=PM1i=1∑M1yi=1⋅(lIDi+lIDi′)(2)
这里, 1 ( ⋅ ) \mathbb{1}_{(\cdot)} 1(⋅)表示指示函数, P M P_M PM是 D \mathcal{D} D中的正样本数量.Optimizing the above loss function not only helps to implicitly encode category semantic information into the vector representation,It can also better promote the pair-wise semantic reasoning ability.
2. Hard negative sample learning
等式(1)可以被重写为
l ID i = log ( 1 + ∑ j ≠ i , i ′ exp [ s ( z i , z j ) − s ( z i , z i ′ ) τ ] ) \mathcal{l}_{\text{ID}}^i=\log\Big(1+\sum_{j\neq i,i'}\exp[\frac{s(z_i,z_j)-s(z_i,z_{i'})}{\tau}] \Big) lIDi=log(1+j=i,i′∑exp[τs(zi,zj)−s(zi,zi′)])
It can be seen as a reference to the standardtriplet loss的扩展,通过将minibatch内的 2M-2 \text{2M-2} 2M-2个样本作为负样本.然而,Negative samples are uniformly sampled from the training data,It ignores the amount of information these samples contain.理想情况下,Difficult negative samples from different semantic groups but close mapping should be separated.虽然在 NLI \text{NLI} NLIThere is no category-level supervision in ,But the importance of negative samples can be approximated by the following method.
l wID i = log ( 1 + ∑ j ≠ i , i ′ exp [ α j s ( z i , z j ) − s ( z i , z i ′ ) τ ] ) (3) \mathcal{l}_{\text{wID}}^i=\log\Big(1+\sum_{j\neq i,i'}\exp[\frac{\alpha_js(z_i,z_j)-s(z_i,z_{i'})}{\tau}] \Big) \tag{3} lwIDi=log(1+j=i,i′∑exp[ταjs(zi,zj)−s(zi,zi′)])(3)
这里, α j = exp ( S ( z i , z h ) / t a u ) 1 2 M − 2 ∑ k ≠ i , i ′ exp ( S ( z i , z k ) / τ ) \alpha_j=\frac{\exp(S(z_i,z_h)/tau)}{\frac{1}{2M-2}\sum_{k\neq i,i'}\exp(S(z_i,z_k)/\tau)} αj=2M−21∑k=i,i′exp(S(zi,zk)/τ)exp(S(zi,zh)/tau),It can be interpreted as targeting z i z_i zi, z j z_j zj在所有 2 M − 2 2M-2 2M−2The relative importance of the negative samples.The importance is based on assumptions:Difficult negative samples are those that are identical in representation space z i z_i zicloser sample.
3. Entailment and Contradiction Reasoning
The instance discriminative loss function is mainly used to separate positive sample pairs from other sample pairs,But there is no clear mandate to judgecontradiction和entailment.为了这个目的,Joint optimization in pairsentailment和contradictionInference objective function.这里采用基于softmaxThe cross-entropy loss function is used to form the pairwise classification objective function.令 u i = ψ ( x i ) u_i=\psi(x_i) ui=ψ(xi)代表句子 x i x_i xi的向量表示,for each labeled sentence pair ( x i , x i ′ , y i ) (x_i,x_{i'},y_i) (xi,xi′,yi),Minimize the loss function below
l C i = CE ( f ( u i , u i ′ , ∣ u i − u i ′ ∣ ) , y i ) (4) \mathcal{l}_{C}^i=\text{CE}(f(u_i,u_{i'},|u_i-u_{i'}|),y_i) \tag{4} lCi=CE(f(ui,ui′,∣ui−ui′∣),yi)(4)
这里 f f fRepresents a linear classification head, CE \text{CE} CE是交叉熵损失函数.不同于先前的工作,本工作将neuralSample pairs are removed from the original training set,And focus on semanticsentailment和contradictionon the binary classification problem.这样做的动机是:neuralIt can be captured by the instance discriminative loss function.因此,这里移除了neuralsample pair PairSupCon \text{PairSupCon} PairSupConThe complexity of the two loss functions,and improve learning efficiency.
- 总的损失函数
L = ∑ i = 1 M l C i + β 1 y i = 1 ⋅ ( l wID i + l wID i ′ ) (5) \mathcal{L}=\sum_{i=1}^M \mathcal{l}_C^i+\beta\mathbb{1}_{y_i=1}\cdot(\mathcal{l}_{\text{wID}}^i+\mathcal{l}_{\text{wID}}^{i'}) \tag{5} L=i=1∑MlCi+β1yi=1⋅(lwIDi+lwIDi′)(5)
其中, l C i \mathcal{l}_C^i lCi和 l wID i \mathcal{l}_{\text{wID}}^i lwIDi, l wID i ′ \mathcal{l}_{\text{wID}}^{i'} lwIDi′由等式(4)和等式(3)定义.在等式(5)中, β \beta βis a balanced hyperparameter.
三、实验

边栏推荐
猜你喜欢

入门:人脸专集2 | 人脸关键点检测汇总(文末有相关文章链接)
![[Image dehazing] Image dehazing based on color attenuation prior with matlab code](/img/ae/d6d36671804fadae548464496f28d6.png)
[Image dehazing] Image dehazing based on color attenuation prior with matlab code

如何通过JMobile软件实现虹科物联网HMI/网关的报警功能?

瑞吉外卖学习笔记4

RS-485多主机通信的组网方式评估
IoU、GIoU、DIoU、CIoU四种损失函数总结
Major upgrade of MSE Governance Center - Traffic Governance, Database Governance, Same AZ Priority

Consul简介和安装
从 GAN 到 WGAN
servlet映射路径匹配解析
随机推荐
选择是公有云还或是私有云,这很重要吗?
西安凯新(CAS:2408831-65-0)Biotin-PEG4-Acrylamide 特性
[TAPL] 概念笔记
flask生成路由的2种方式和反向生成url
servlet映射路径匹配解析
AIRIOT答疑第8期|AIRIOT的金字塔服务体系是如何搞定客户的?
FPGA工程师面试试题集锦61~70
799. 最长连续不重复(双指针)
MySQL 查询出重复出现两次以上的数据 - having
我们用48h,合作创造了一款Web游戏:Dice Crush,参加国际赛事
宝塔部署flask项目
云渲染的应用正在扩大,越来越多的行业需要可视化服务
3D Game Modeling Learning Route
CAS:2055042-70-9_N-(叠氮基-PEG4)-生物素
mysql 中大小写问题
服务器上行带宽和下行带宽指的是什么
[Go WebSocket] Your first Go WebSocket server: echo server
PG中的Index-Only Scans解密
API 网关的功能
MSE 治理中心重磅升级-流量治理、数据库治理、同 AZ 优先