当前位置:网站首页>Mysql statement analysis, storage engine, index optimization, etc.
Mysql statement analysis, storage engine, index optimization, etc.
2022-08-10 15:06:00 【languageStudents】
高性能Mysql阅读笔记
Mysql存储引擎
Mysql的默认存储引擎:Innodb
在Mysql5.1版本之前,默认存储引擎为: MyISAM
The difference between multiple concurrency control of storage engines(MVCC):
InnoDB:
支持事务,Four isolation levels are employed
Read Uncommitted (读未提交)
并发量最高,Modifications within a transaction are even committed,Also visible in other transactions
Read Committed (读已提交)
This is the default isolation level for most database management systems(Mysql不是),Only committed transaction modifications are visible.
It is possible that the result of two executions is the same,但结果不一样
RepeaTable Read (可重复读)
Mysql的事务默认隔离级别.It is guaranteed that the results of multiple reads of the same transaction are consistentSerializable (可串行化)
最高的隔离级别,并发量最低,A shared lock is added when each row of data is read.
MyISAM:
不支持事务
性能方面,在某些特定场景下,MyISAM性能很好.设计简单,数据以紧密格式存储,插入速度非常快
Mysql的自动提交
Mysq默认采用自动提交模式.也就是说,If not displayed, start a transaction,Then each query is treated as a transaction to perform the commit operation.in the current link,可以通过设置AUTOCOMMITVariable to enable or disable autocommit mode.(*10)
可以通过命令set autocommit= 0/1(1:启用.0:关闭)
Mysql性能剖析
捕获Mysql的查询到日志文件
可以通过设置long_query_time=0来捕获所有的查询
show variables like 'slow_query_log'; -- Shows whether the opening is slowsql日志
SET GLOBAL slow_query_log_file -- 指定慢查询日志存储文件的地址和文件名.
SET GLOBAL log_queries_not_using_indexes -- 无论是否超时,未被索引的记录也会记录下来.
SET SESSION long_query_time -- SQL execution exceeds this threshold(秒)will be recorded in the log.
SET SESSION min_examined_row_limit -- 慢查询仅记录扫描行数大于此参数的 SQL.
There are tools for analyzing slow query logspt-query-digest,一半情况下,Just pass the slow query log as a parameterpt-query-digest,will work correctly.He will print out the analysis report of the query.
Mysql性能剖析工具
- New Relic (会插入到应用程序中进行性能剖析)
- Mattkit
- Super Smark(可以提供压力测试和负载生成.可以加载测试数据到数据库,And support the accumulation of generated data to fill the data table)
SHOW PROFILE
语句分析工具
SHOW PROFILE命令是在Mysql5.1以后的 版本引入的.disabled by default,可以通过set profiling=1来开启
The tool will execute all statements on the server,It will detect the time spent and other related data of query execution state changes.
When a query command is submitted to the server,Analysis information will be recorded in a temporary record table.
使用方式:
使用命令show PROFILESYou can view all recorded execution statements,Each statement has an encodingQuery_id.Find the statement for which you want to see details.拿到Query_id.
在通过命令
show profile for QUERY queri_id(上面获取到的Query_id);
如下图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LqM2b4AX-1659795260686)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.00.03.png)]](/img/c3/cff4b12c1746e0901de3b941307f16.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5QaRYS2-1659795260687)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.01.47.png)]](/img/c6/99419bbfc15e2d966853a377e1e5e7.png)
SHOW STATUS
返回一些计数器,Shows the number of operations for some,例如下sqlStatements can be viewed quickly,The number of times the temporary table was used.and read operations that use the index(*84)
SHOW STATUS WHERE Variable_name LIKE 'Handler%' OR Variable_name LIKE 'Create%'
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QZWjwCSH-1659795260687)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.12.53.png)]](/img/62/3ae0b6d89f7d38ca146592f8dc43f0.png)
也可以使用SHOW GLOBAL STATUSShow global state
选择优化的数据类型
注意点
- Usually smaller data types should be
- 简单就好,For example, integer operations are less expensive than string operations
- 尽量避免NULL值
最好指定列为NOT NULL,如果查询中包含NULL值,对于Mysqlmay be more difficult to optimize.因为可为NULL的列使得索引、The comparison of index statistics and values is more complicated,可为NULL的列会使用更多的存储空间
整数类型
If it is an integer,There are several types of integers
Also better can use auto increment
- TINYINT 范围:(-128-127)所占字节 :8
- SMALLINT 范围:(-8388608-8388607)16
- MEDIUMINT 范围:(-128-127)24
- INT 范围:(-2,147,483,648-2,147,483,647) 32
- BIGINT 范围:(-9223372036854775808-9223372036854775807) 64
浮点数类型
DECIMAL
可以存储比BIGINT还大的整数,Support high-precision calculations
DOUBLE
FLOAT
字符串类型
- VARCHAR
可变长字符串,An additional byte is required to record the length of the character.
思考:
varchar(5)和varchar(2000)The space overhead is the same,So is there any advantage to using shorter columns?
答:会有很大的优势,will save more memory,因为mysqlA fixed size of memory will be allocated to hold the inner value.
We only need to allocate the space that is really needed to be optimal
- CHAR
Used to store fixed-length characters,当存储字符时,All trailing spaces are removed,Good for storing values with fields that are close in length
大型数据类型
- BOLB.(以二进制的方式保存数据)
- TEXT.(Save data in character format)
日期时间类型
- DATETIME
Save in a fixed formatYYYYMMDDHHMMSS的整数中(可以保存1001年至9999年)
TIMESTAMP
只能保存1970年至2038年,Save time data with timestamps
索引基础
索引的优点
- 大大减少了服务器需要扫描的数据量
- Helps the server avoid using temporary tables and sorting
- 可以将随机IO变为顺序IO
B-tree
MysqlThe index data type usedB-Tree数据结构来实现的
b-tree通常意味着所有的值是按照顺序存储的.
索引类型
1、单值索引
创建方式:
create index [indexname] ON [tablename](fieldname)
最普通的索引.Create one for all values of that columnb-treeThe index tree of the structure,并升序排序
2、Unique and joint unique indexes
ALTER TABLE tablename ADD UNIQUE [indexname] (fieldname,fieldname)
索引列的值必须唯一.但是可以为null
3、联合索引
create index [indexname] ON [tablename](fieldname,fieldname)
Multiple columns can be specified as index values,Sort by multiple columns in ascending order at the same time.Need to follow the leftmost matching principle
5000A table with more than 10,000 pieces of data.Through the following two figures,同样的sql.One adds a federated index and covers the index.一个没有索引.The time comparison can also show the optimization efficiency of the index
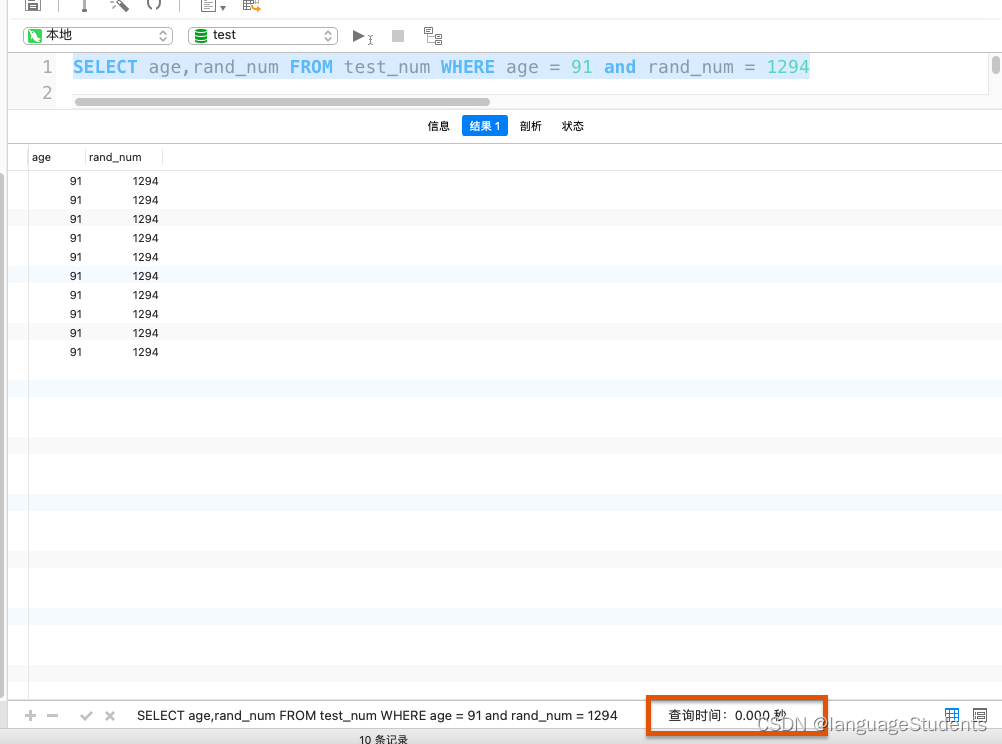
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qxzMDLgu-1659795260688)(/Users/xujiangtao/Desktop/截屏2022-08-06 21.44.42.png)]](/img/dc/ceb4b303eede81ab5b05443eeb673b.png)
4、前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
When the length of some fields is very large,Or field type columns for large spaces.适合使用前缀索引,减小索引文件大小,The speed of indexing
Sometimes very long character columns are indexed,这会让索引变得大且慢.Usually we can index the beginning part of the character.这样可以大大节约索引空间,从而提高索引效率,It also reduces the index selectivity(The same index value may contain multiple rows of data)
不能在order by和group by中使用.Nor can it be used as a covering index
5、聚簇索引
Except for clustered indexes,The other secondary indexes are stored
行指针,That is, the row primary key,找到主键,Then through the primary key clustered index back to the table to find the row data
The biggest difference from other indexes is that the index and data exist in the same area,When the index is found, it means that the data can be found.The primary key in our data table is the clustered index.No primary key is specified by default when a table is created,mysql的存储引擎InnodbA unique non-null index is chosen instead.如果没有这样的索引,innodbThe primary key is implicitly defined as a clustered index.
6、覆盖索引
This is not a specific index that can be added,It means that the data columns and query conditions you want to query all use indexes.It is no longer necessary to query data through the primary key back to the table.That is, the query column is consistent with the index column
Covering indexes can be effectively reducedIO,提高查询效率.
减少使用.
Select *
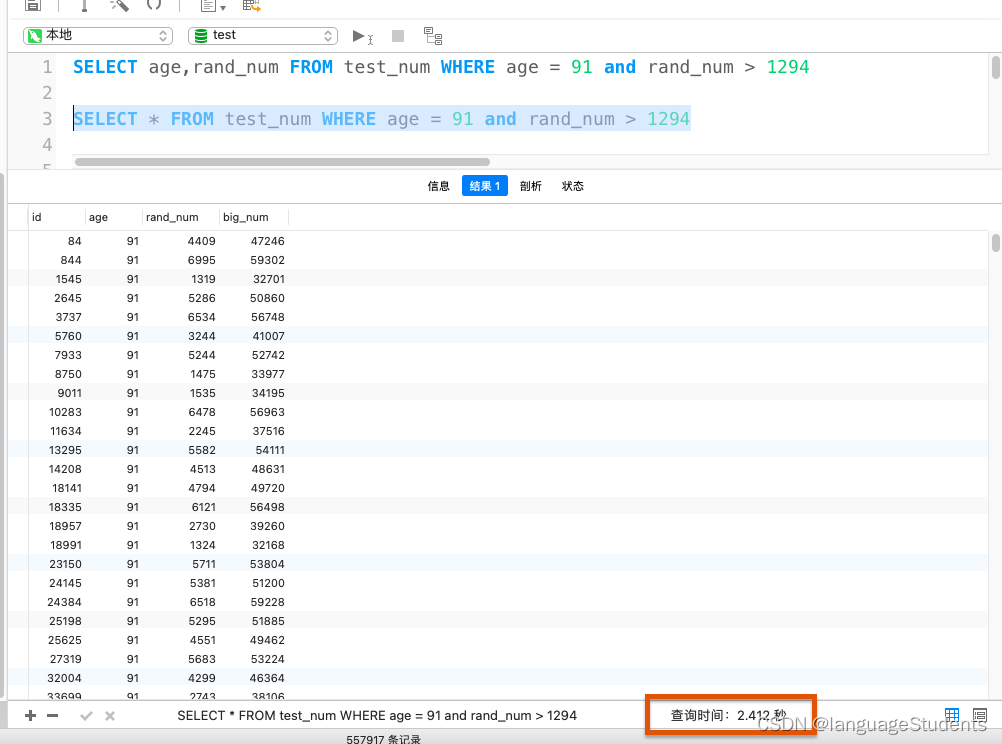
The following table has 50 million test data,一个使用select * One uses an index field.Comparison of query times,相差了n呗.This is the benefit of covering indexes.At the same time, try to avoid using itSelect *
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gP1pu13z-1659795260688)(/Users/xujiangtao/Desktop/截屏2022-08-06 21.23.23.png)]](/img/95/b6aaacf0414c5dd4832883c2a290ed.png)
索引失效场景
- 联合索引不满足最左匹配原则
- 使用
select * - Index columns participate in function calculations
- 除
123%Other fuzzy queries of this kind.%123、%123%都会失效 - 类型的隐式转换
- Comparison between indexed columns
- 使用条件not in、not exists 、is not null
边栏推荐
猜你喜欢


![[Semantic Segmentation] DeepLab Series](/img/3d/f06c04522db40ad17f7f725613a035.png)



随机推荐
antd组件中a-modal设置固定高度,内容滚动显示
富爸爸穷爸爸之读书笔记
正则表达式(包含各种括号,echo,正则三剑客以及各种正则工具)
领域驱动模型设计与微服务架构落地-从项目去剖析领域驱动
网络安全(加密技术、数字签名、证书)
Redis -- Nosql
Flask框架——基于Celery的后台任务
容器化 | 在 S3 实现定时备份
How to code like a pro in 2022 and avoid If-Else
It is reported that the original Meitu executive joined Weilai mobile phone, the top product may exceed 7,000 yuan
易观分析联合中小银行联盟发布海南数字经济指数,敬请期待!
SWIG教程《四》-go语言的封装
How to code like a pro in 2022 and avoid If-Else
Introduction to the Internet (2)
640. 求解方程 : 简单模拟题
微信扫码登陆(1)—扫码登录流程讲解、获取授权登陆二维码
数学建模学习视频及资料集(2022.08.10)
【吴恩达来信】强化学习的发展!
"Thesis Reading" PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable
QOS功能介绍