当前位置:网站首页>3.1-Classification-probabilistic generative model
3.1-Classification-probabilistic generative model
2022-08-11 07:52:00 【A boa constrictor. 6666】
一、分类(Classification)
- for the classification task,Similar to regression,The same is to find a function f,His input is an object x,The output is a category class n
- There are many such classification tasks in reality,比如:
- 信用评分
- 输入:收入,存款,职业,年龄,past financial situation
- 输出:接受或拒绝
- 医学诊断
- 输入:current symptoms、年龄、性别、Past medical records
- 输出:哪种疾病
- 手写字符识别
- 输入:手写字符
- 输出:The corresponding numerically encoded character
- 人脸识别
- 输入:face image
- 输出:corresponding person
- 信用评分
1.1 应用示例
- The following is an example of the classification of Pokémon,Every Pokémon can be used7properties to describe:Total,HP,Attack,Defense,SP Atk,SP Def,Speed.Below we will use these attributes to predict what category a Pokémon will belong to.
- Suppose we haven't learned how to use classification to solve this problem,At this time, we solve this problem by means of regression,See what happens below.Take the problem of binary classification as an example:
- The regression model as shown will penalize those that are too correct,Output those points where the value is too large,The result obtained in this way is not good.

- 理想的选择(Ideal Alternatives)
- 定义一个模型g(x),当输入x时,输出大于0就输出class 1,否则输出class 2
- lossThe function is used to count the number of times the prediction was wrong in the training set
- The way to find the optimal solution is the perceptron(Perceptron),支持向量机(SVM),生成模型(Generative Model)

生成模型(Generative Model)
- estimated from the training setx发生的概率P(x),This is the generative model.
- 先验概率(Prior):P(C1)和P(C2)It can be calculated based on the existing training set
高斯分布(Gaussian distribution):Any Pokémon can be represented by a set of their attribute vectors,下面我们取Defense,SP DefA two-dimensional vector of these two attributes to represent a Pokémon.Because of the turtle in the test set we cannot know its prior probabilityP(x),Therefore we assume that the existing training set is sampled from a Gaussian distribution,So now we can estimate what the prior probability is for this turtle.
for a Gaussian distribution,它的输入是一个向量x,The output is a sampling probabilityFont metrics not found for font: .,The shape of its function is given by the mean𝝁和协方差矩阵𝜮确定








最大似然估计(Maximum Likelihood):Since each point is independently sampled from a Gaussian distribution,而这79One point is that it is possible to sample from a different Gaussian distribution.for different Gaussian distributions,There will be different degrees of similarity(Different Likelihood).So we need to find a similarityFont metrics not found for font: .The highest Gaussian distributionFont metrics not found for font: .
The picture on the right is the average value of the water-type and normal-type Pokémon we actually calculated𝝁和协方差矩阵𝜮


二、预测
- The graph on the right is the accuracy we get based on the model's predictions on the test set,2The accuracy of each parameter is 47%,7The accuracy of each parameter is 54%,Obviously our model works very poorly,Continued optimization is required.


- 修正模型(Modifying Model):A common practice is that different classes can share the same covariance matrix𝜮,This way we can reduce the variance by reducing the parameters of the model(variance),This results in a simpler model.其中u1和u2The algorithm has not changed,而𝜮became before𝜮1和𝜮2The weighted average sum between the two.结果从53%提高到了73%



三、总结
- The figure on the left is a three-step analysis process for the task of classification,The picture on the right is that the probability distribution model we use is not necessarily a Gaussian distribution,If we have a binary classification problem,可以使用伯努利分布(Bernoulli distributions);If all dimensions are assumed to be independent,Then a Naive Bayes classifier can be used(Naive Bayes Classifier).


- 后验概率(Posterior Probability):After deriving from a whole bunch of boring math,我们得到了最终的P(C1|x)的数学表达式.但是为了得到w和b,在生成模型中,我们估计了𝑁1,𝑁2, 𝜇1, 𝜇2, Σ这么多的参数,It seems a little far-fetched,Why don't we just look for it right from the startw和b呢?We will delve into this issue in the next chapter on logistic regression.



边栏推荐
猜你喜欢

公牛10-11德里克·罗斯最强赛季记录
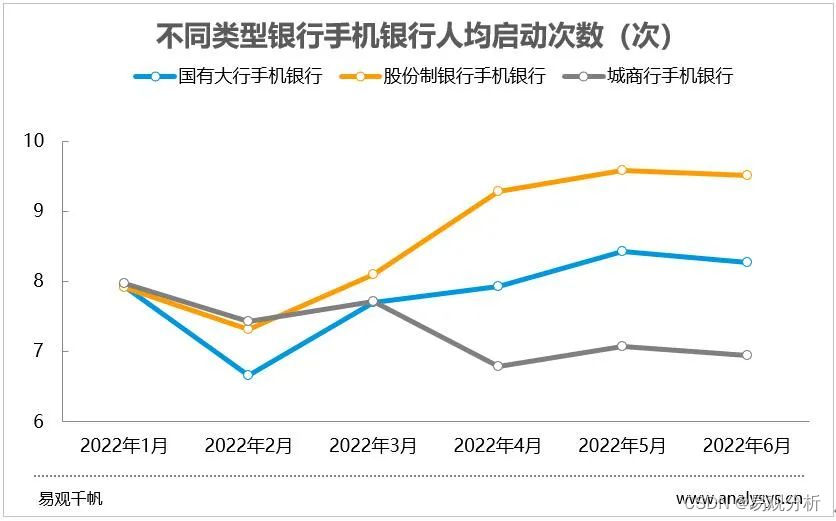
6月各手机银行活跃用户较快增长,创半年新高
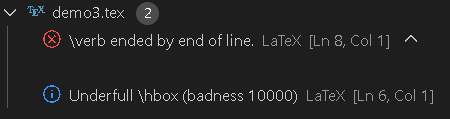
【LaTex-错误和异常】\verb ended by end of line.原因是因为闭合边界符没有在\verb命令所属行中出现;\verb命令的正确和错误用法、verbatim环境的用法
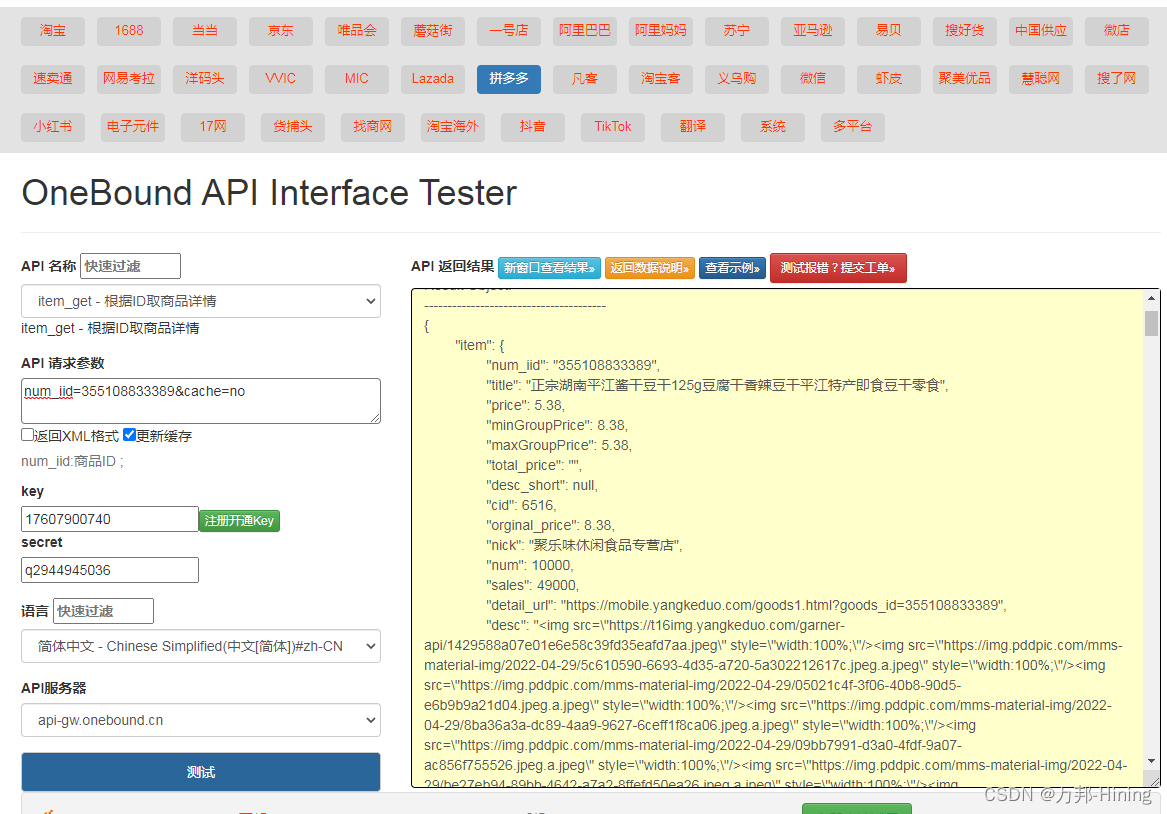
Pinduoduo API interface
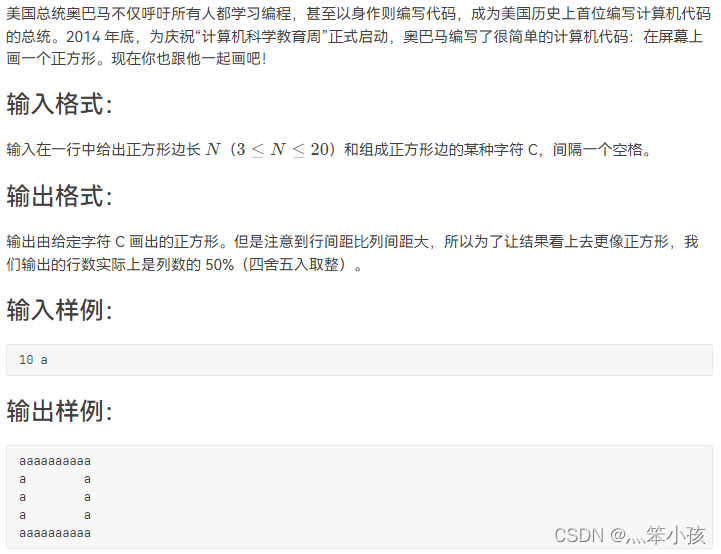
1036 Programming with Obama (15 points)
1056 组合数的和 (15 分)
Tensorflow中使用tf.argmax返回张量沿指定维度最大值的索引
1.1-回归
关于#sql#的问题:怎么将下面的数据按逗号分隔成多行,以列的形式展示出来

Tidb二进制集群搭建

随机推荐
js根据当天获取前几天的日期
TF中使用softmax函数;
3.2-分类-Logistic回归
What are the things that should be planned from the beginning when developing a project with Unity?How to avoid a huge pit in the later stage?
1046 划拳 (15 分)
2022-08-09 Group 4 Self-cultivation class study notes (every day)
Go语言实现Etcd服务发现(Etcd & Service Discovery & Go)
联想集团:2022/23财年第一季度业绩
TF generates (feature, label) set through feature and label, tf.data.Dataset.from_tensor_slices
为什么C#中对MySQL不支持中文查询
求职简历这样写,轻松搞定面试官
Item 2 - Annual Income Judgment
Discourse's Close Topic and Reopen Topic
【软件测试】(北京)字节跳动科技有限公司二面笔试题
TF中的四则运算
tf.reduce_mean()与tf.reduce_sum()
2.1-梯度下降
1081 检查密码 (15 分)
The most complete documentation on Excel's implementation of grouped summation
Tf中的平方,多次方,开方计算