当前位置:网站首页>波士顿房价预测
波士顿房价预测
2022-08-10 14:17:00 【ㄣ知冷煖*】
目录
前言
对于波士顿房价数据集的预测实战一、波士顿房价预测实战
1-1、数据集介绍&数据集导入&分割数据集
from keras.datasets import boston_housing
# 预测20世纪70年代中期波士顿郊区房屋价格的中位数
# 数据点比较少,只有506个,分为404个训练样本和102个测试样本
# 输入数据的每个特征都有不同的取值范围。
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
# 查看训练数据
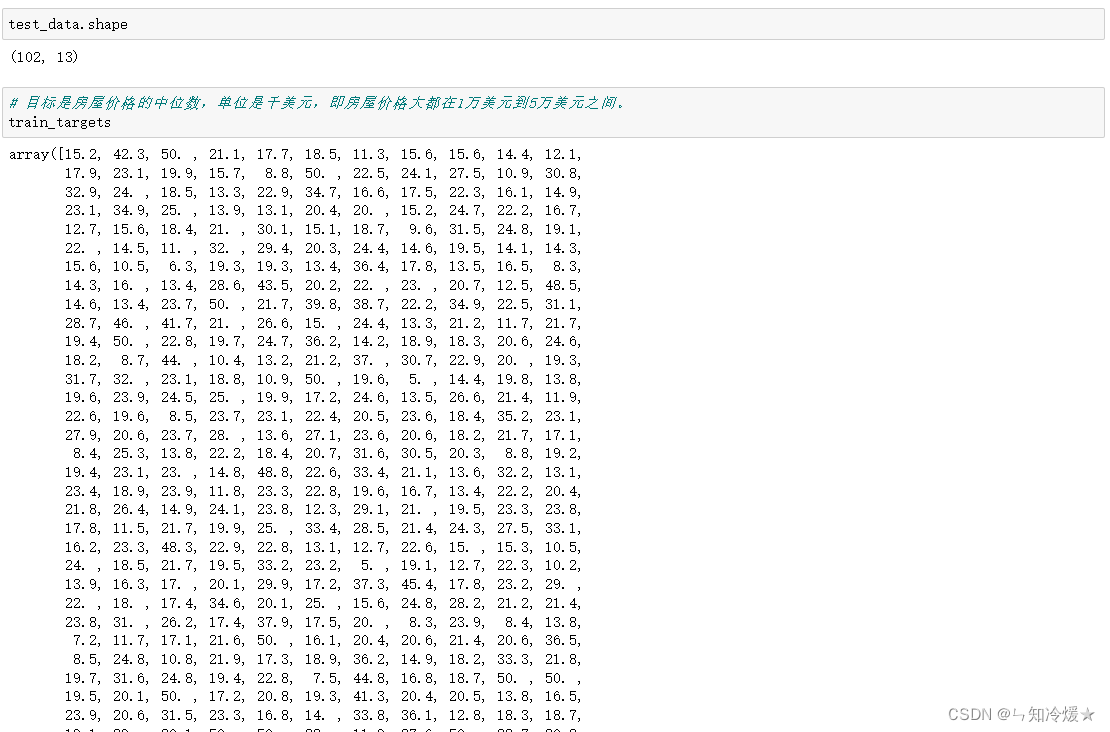
输出:可以看到数据量较少,数据维度是13维的。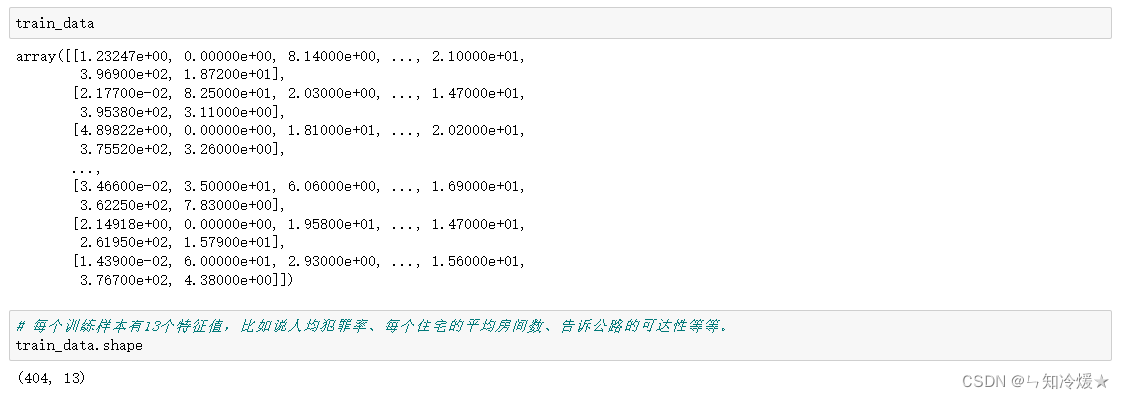
1-2、数据标准化
def normalize(train_data):
"""
数据标准化
"""
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
return mean, std, train_data
mean, std, train_data = normalize(train_data)
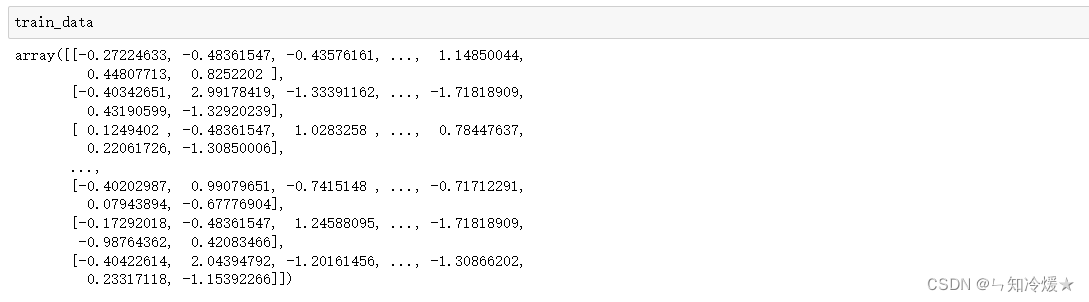
# 注意:测试数据标准化的均值和标准差都必须是在训练数据上计算得到的。
test_data -= mean
test_data /= std
# 查看标准化后的数据
输出:
1-3、构建网络
import keras
def build_model():
"""
搭建网络
mse:损失函数采用均方误差,即mse。
mae:训练过程中采用的监控指标,mae,即平均绝对误差。
"""
model = keras.models.Sequential()
model.add(keras.layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))
model.add(keras.layers.Dense(64, activation='relu'))
model.add(keras.layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
1-4、K折交叉验证&取出所有的训练损失、训练平均绝对误差、验证损失、验证平均绝对误差
# 因为在本例子中,数据较少,选择不同的训练集和验证集,验证分数会有较大的波动,这种情况下最好使用K折交叉验证,最后求K个验证分数的平均值。
import numpy as np
k=4
num_epochs = 500
all_loss = []
all_val_loss = []
all_mae = []
all_val_mae = []
num_val_samples = len(train_data) // k
for i in range(k):
print('-'*20+str(i)+' Start'+'-'*20)
val_data = train_data[i*num_val_samples:(i+1)*num_val_samples]
val_targets = train_targets[i*num_val_samples:(i+1)*num_val_samples]
partial_train_data = np.concatenate((train_data[:i*num_val_samples],train_data[(i+1)*num_val_samples:]))
partial_train_targets = np.concatenate((train_targets[:i*num_val_samples],train_targets[(i+1)*num_val_samples:]))
model = build_model()
# batch_size: 一次训练所选取的样本数。
history = model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=1, verbose=0,
validation_data=(val_data, val_targets))
all_loss.append(history.history['loss'])
all_val_loss.append(history.history['val_loss'])
all_mae.append(history.history['mae'])
all_val_mae.append(history.history['val_mae'])
print('-'*20+str(i)+' End'+'-'*20)
1-5、计算平均mae&绘制验证mae分数&绘制验证loss分数
# 回归问题常常使用的损失函数是均方误差
# 常用的回归指标是平均绝对误差,即MAE
# 如果可以用的数据很少,则可以使用K折交叉验证可靠的评估模型
# 如果可用的训练数据较少,则尽量使用较少的隐藏层(即只有一个或者两个隐藏层),这样可以避免过拟合。
# 如果数据被分为多个类别,那么中间层过小可能会导致信息瓶颈
# all_val_mae: (4,500)
average_mae_history = [np.mean([x[i] for x in all_val_mae]) for i in range(num_epochs)]
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=list(range(1, len(average_mae_history)+1)), y=average_mae_history,
mode='lines',
name='average_mae_history'))
fig.show()
输出: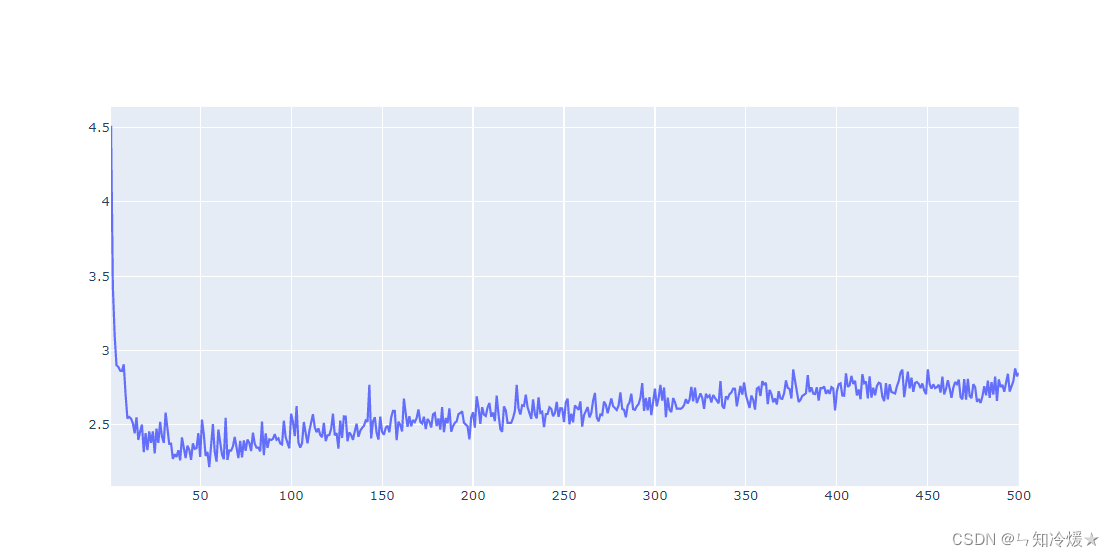
前10天数据拟合落差太大,无法对10天后的数据进行有效的观察。所以从第10天开始输出:
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=list(range(10, len(average_mae_history)+1)), y=average_mae_history[10:],
mode='lines',
name='average_mae_history'))
fig.show()
输出: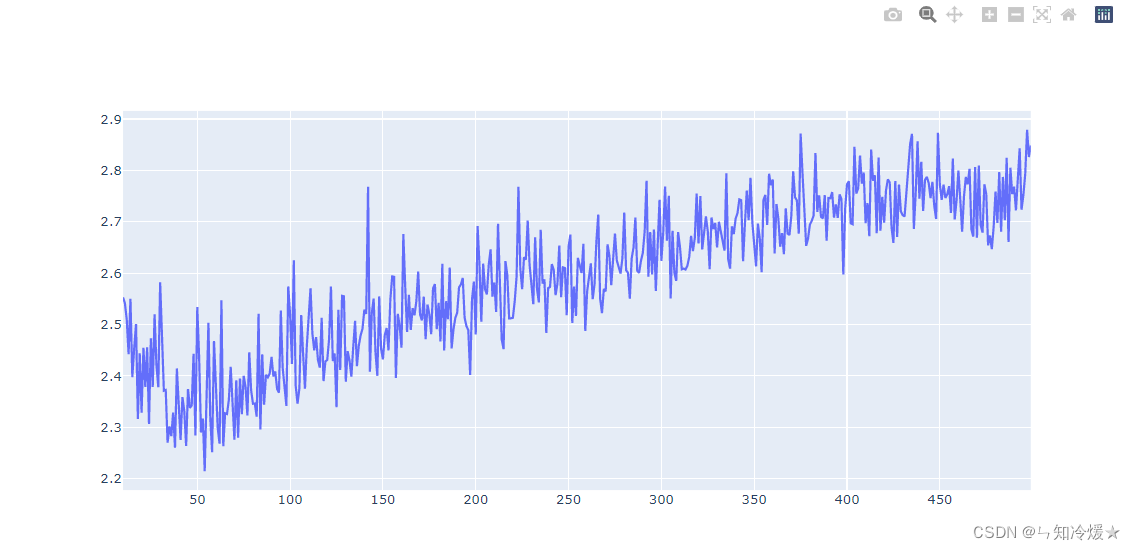
绘制验证集loss:
average_mse_history = [np.mean([x[i] for x in all_val_loss]) for i in range(num_epochs)]
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=list(range(10, len(average_mse_history)+1)), y=average_mse_history[10:],
mode='lines',
name='average_mse_history'))
fig.show()
输出: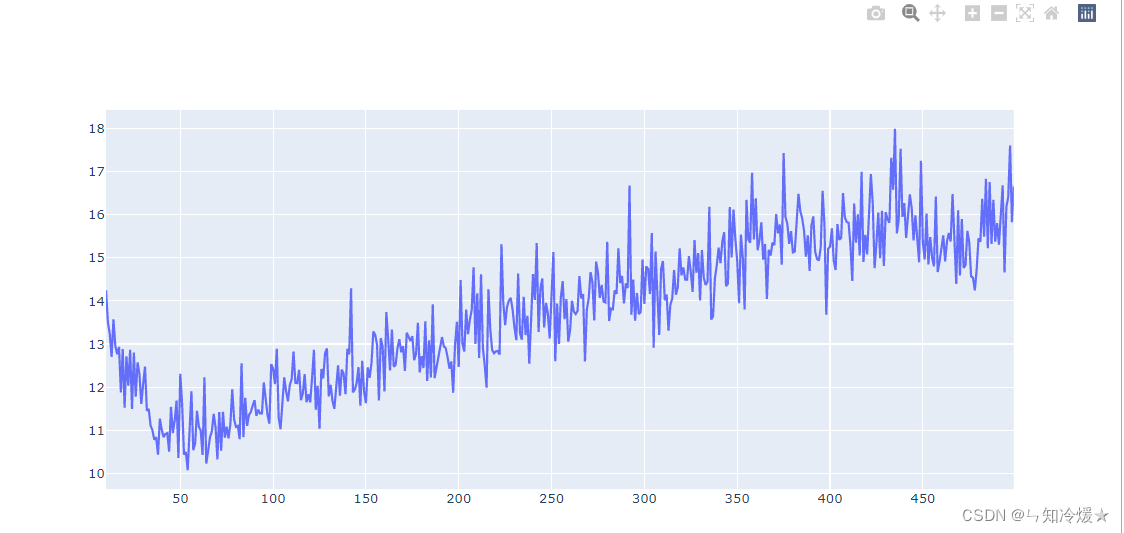
1-6、找到最好的训练轮次&批次
# 根据1-5的探索可知,大概在40轮次到90轮次的损失是最低的,所以我们选择40-90轮次进行调参。
for i in range(40, 91):
for j in [16, 32, 64]:
model = build_model()
model.fit(train_data, train_targets, epochs=i, batch_size=j, verbose=0)
test_mse_score,test_mae_score = model.evaluate(test_data, test_targets)
print('轮次:{
}, 一次训练所取的样本数:{
}, mse: {
}, mae: {
}'.format(i, j, test_mse_score, test_mae_score))
# 这里的mae和loss每次训练都会有误差,所以大概选40-90轮次这个范围就ok,不用太纠结具体数值。

二、调参总结
调参总结:
1、训练轮次:房价预测是较为复杂的模型,先选择较大的轮次,这里设置为500,观察数据在验证集上的表现,训练是为了拟合一般数据,所以当模型在验证集上准确率下降时,那就不要再继续训练了。在验证集上大概在40轮次到90轮次的损失是最低的,所以选择这个范围内的训练轮次。
2、隐藏层数设置:同隐藏单元的设置规则,数据简单,则设置的层数较少,如果数据复杂,可以多加几层来观察数据的整体表现。
3、Trick:带有打乱数据的重复K折验证,如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复K折验证(当然这里的话这个Trick是不行的!这里是时间序列数据,是不可以被打乱的。)
4、尝试调节模型的其他方法:添加dropout、添加L1或者L2正则化、反复做特征工程(添加或者是删除没有信息量的特征)
总结
周二早上,昨天睡了很久很久,做了一个很长很长的梦。
边栏推荐
- 司空见惯 - 股市狠狠下跌后,何時能反弹?
- [JS Advanced] Creating sub-objects and replacing this_10 in ES5 standard specification
- 普林斯顿微积分读本05第四章--求解多项式的极限问题
- 2022年网络安全培训火了,缺口达95%,揭开网络安全岗位神秘面纱
- Summary of tensorflow installation stepping on the pit
- 符合信创要求的堡垒机有哪些?支持哪些系统?
- R语言使用gt包和gtExtras包优雅地、漂亮地显示表格数据:gtExtras包的gt_highlight_rows函数高亮(highlight)表格中特定的数据行、配置高亮行的特定数据列数据加粗
- How to code like a pro in 2022 and avoid If-Else
- NAACL 2022 | 简单且高效!随机中间层映射指导的知识蒸馏方法
- 锂电池技术
猜你喜欢

正则表达式(包含各种括号,echo,正则三剑客以及各种正则工具)

强意识 压责任 安全培训筑牢生产屏障

如何完成新媒体产品策划?
Stream通过findFirst()查找满足条件的一条数据
【量化交易行情不够快?】一文搞定通过Win10 wsl2 +Ubuntu+redis+pickle实现股票行情极速读写

AWS 安全基础知识
Send a post request at the front desk can't get the data
Lack of comparators, op amps come to the rescue!(Op amp is recorded as a comparator circuit)
Open source SPL wipes out tens of thousands of database intermediate tables
使用决策树对鸢尾花进行分类
随机推荐
C#实现访问OPC UA服务器
AWS Security Fundamentals
日志@Slf4j介绍使用及配置等级
R语言使用gt包和gtExtras包优雅地、漂亮地显示表格数据:gtExtras包的gt_highlight_rows函数高亮(highlight)表格中特定的数据行、配置高亮行的特定数据列数据加粗
黑客入门,从HTB开始
1004(树状数组+离线操作+离散化)
王学岗—————————哔哩哔哩直播-手写哔哩哔哩硬编码录屏推流(硬编)(26节课)
【JS高级】ES5标准规范之创建子对象以及替换this_10
简单的写一个防抖跟节流
Do not access Object.prototype method ‘hasOwnProperty‘ from target object....
等保2.0一个中心三重防护指的是什么?如何理解?
强意识 压责任 安全培训筑牢生产屏障
“Oracle 封禁了我的账户”
普林斯顿微积分读本05第四章--求解多项式的极限问题
系统的安全和应用(不会点安全的东西你怎么睡得着?)
文件系统设计
[target detection] small script: extract training set images and labels and update the index
Circle 创始人回应美财政部禁止 Tornado :隐私与安全之间关系紧张
CodeForces - 811A
《论文阅读》PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable