当前位置:网站首页>KNN, kmeans and GMM
KNN, kmeans and GMM
2022-04-23 15:27:00 【moletop】
Knn,Kmeans and GMM
KNN
-
Classification algorithm
-
Supervised learning
-
K Value means - For a sample X, To classify it , First, from the dataset , stay X Look nearby for the nearest K Data points , Divide it into the category with the most categories .
problem : KNN The core of the algorithm is to find the location of the sample to be tested in the training sample set k A close neighbor , If the training sample set is too large , Then the traditional traversal of the whole sample to find k The nearest neighbor approach will lead to a sharp decline in performance .
improvement :1.kd-tree
- kd-tree Space for time ,** Use the sample points in the training sample set , Align... In turn along each dimension k Divide the dimensional space , Build a binary tree ,** The idea of divide and conquer is used to greatly improve the search efficiency of the algorithm . We know , The algorithm complexity of binary search is O(logN),kd-tree The search efficiency is close to ( Depending on the construction kd-tree Whether it is close to the balance tree ).
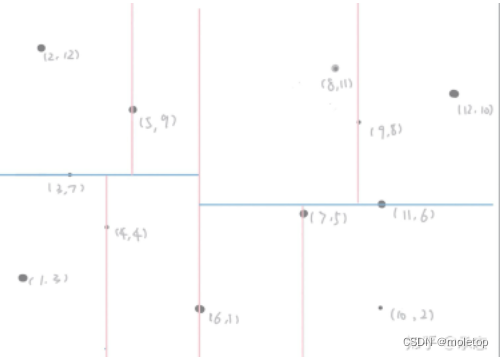
1. Every layer down the tree , We will change a dimension to measure . The reason is also simple , Because we want this tree to be K Dimensional space has a good expression ability , It is convenient for us to query quickly according to different dimensions .
2. Leaf node , Actually Represents a small space in the sample space .
3. In one query Go straight to K A recent sample
Excellent blog :https://zhuanlan.zhihu.com/p/127022333
-
ball-tree
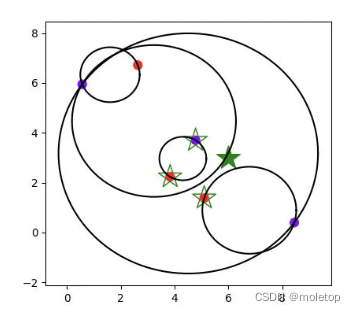
stay kd-tree in , One of the core factors leading to performance degradation is kd-tree The partitioned subspace in is a hypercube , The nearest neighbor is the Euclidean distance ( Super ball ), The possibility of a hypercube intersecting with a hypersphere is very high , All intersecting subspaces , All need to be checked , Greatly reduce the operation efficiency .
If The division area is also a hypersphere , The probability of intersection is greatly reduced . As shown in the figure below , by ball-tree Divide space by hypersphere , Remove edges and corners , The probability of intersection between dividing hypersphere and searching hypersphere is greatly reduced , Especially when the data dimension is very high , The efficiency of the algorithm has been greatly improved .
K-means
- clustering algorithm
- Unsupervised learning
- The dataset is null Label, Messy data
- K Value means - K It's a preset number , Divide the dataset into K A cluster of , We need to rely on human prior knowledge
k-means shortcoming
- Number of cluster centers K Need to be given in advance , But in practice, this K The choice of value is very difficult to estimate
- Kmeans The initial clustering center needs to be determined artificially , Different initial clustering centers may lead to different clustering results , For example, falling into local optimization .( have access to Kmeans++ Algorithm to solve )
- Sensitive to noise and outliers
improvement :
1.Kmeans++
- Step one : Randomly select a sample as the first cluster center c1;
- Step two : Calculate the shortest distance between each sample and the existing cluster center ( That is, the distance from the nearest cluster center ), use
D(x)Express ; The bigger this is , It means that the probability of being selected as the cluster center is high ; Last , Use the roulette method to select the next cluster center ;- Step three : Repeat step 2 , Know how to choose k Cluster centers .
After selecting the initial point , Just keep using the standard k-means The algorithm .
2. Two points K_means
solve K-Means The algorithm is sensitive to the initial cluster center , Two points K-Means The algorithm is an algorithm that weakens the initial centroid , The specific steps are as follows :
Put all the sample data into a queue as a cluster ;
Select a cluster from the queue to K-means Algorithm partition ( The first iteration is equivalent to all samples K=2 Division ), It is divided into two sub clusters , And add the sub cluster to the queue to iterate the second step of operation , Until the suspension conditions are met ( Number of clusters 、 Minimum square error 、 Iterations, etc )
The cluster in the queue is the final cluster set .
GMM
-
And K The mean algorithm is similar to , The same is used EM The algorithm is iterative . The Gaussian mixture model assumes that the data of each cluster conforms to the Gaussian distribution ( It's also called normal distribution ) Of , At present The distribution of data presented is the result of superposition of Gaussian distribution of each cluster .
-
The core idea of Gaussian mixture model is , Suppose the data can be seen as generated from multiple Gaussian distributions Of . Under this assumption , Each individual sub model is a standard Gaussian model , The average is ui And variance ∑i Is the parameter to be estimated . Besides , Each sub model has a parameter πi, It can be understood as weight or probability of generating data . The formula of Gaussian mixture model is :
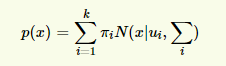
-
The process :
First , Initial random selection of the value of each parameter . then , Repeat the following two steps , Until it converges .1.E step . According to the current parameters , Calculate the probability that each point is generated by a certain sub model .
2.M step . Use E The estimated probability of the step , To improve the mean value of each sub model , Variance and weight .
in other words , We don't know the best K Each of the Gauss distributions 3 Parameters , I don't know every one of them Which Gaussian distribution is the data point generated . So every time I cycle , Fix the current Gaussian distribution first change , Obtain the probability of each data point generated by each Gaussian distribution . Then fix the generation probability to be the same , According to data points and generation probability , Get a better Gaussian distribution for a group . cycle , Until the parameters don't change , Or change very little , Then we get a reasonable set of Gaussian distribution .
GMM And K-Means comparison
Gaussian mixture model and K The same thing about the mean algorithm is :
- They are all clustering algorithms ;
- Need to be Appoint K value ;
- Is to use EM Algorithm to solve ;
- They can only converge to the local optimum .
And it's compared to K The advantage of mean algorithm is , We can give the probability that a sample belongs to a certain class ; Not just clustering , It can also be used to estimate the probability density ; And can be used to generate new sample points .
版权声明
本文为[moletop]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231523160709.html
边栏推荐
- Llvm - generate for loop
- 重定向和请求转发详解
- SSH connects to the remote host through the springboard machine
- 服务器中毒了怎么办?服务器怎么防止病毒入侵?
- PHP 的运算符
- MultiTimer v2 重构版本 | 一款可无限扩展的软件定时器
- Sword finger offer (1) -- for Huawei
- Explanation of redis database (IV) master-slave replication, sentinel and cluster
- Modify the default listening IP of firebase emulators
- The wechat applet optimizes the native request through the promise of ES6
猜你喜欢
Lotus DB design and Implementation - 1 Basic Concepts
Mysql database explanation (8)

Openfaas practice 4: template operation
On the day of entry, I cried (mushroom street was laid off and fought for seven months to win the offer)
重定向和请求转发详解
Sword finger offer (1) -- for Huawei
For 22 years, you didn't know the file contained vulnerabilities?

API gateway / API gateway (III) - use of Kong - current limiting rate limiting (redis)
Explanation 2 of redis database (redis high availability, persistence and performance management)
Basic operation of sequential stack
随机推荐
Educational Codeforces Round 127 A-E题解
重定向和请求转发详解
Node.js ODBC连接PostgreSQL
什么是CNAS认证?CNAS认可的软件测评中心有哪些?
GFS distributed file system (Theory)
What role does the software performance test report play? How much is the third-party test report charged?
Lotus DB design and Implementation - 1 Basic Concepts
What is CNAs certification? What are the software evaluation centers recognized by CNAs?
regular expression
Redis cluster principle
el-tree实现只显示某一级复选框且单选
Mysql database explanation (8)
C language super complete learning route (collection allows you to avoid detours)
Leetcode学习计划之动态规划入门day3(198,213,740)
Educational codeforces round 127 A-E problem solution
redis-shake 使用中遇到的错误整理
Explanation of redis database (III) redis data type
Machine learning - logistic regression
MultiTimer v2 重构版本 | 一款可无限扩展的软件定时器
PSYNC synchronization of redis source code analysis