当前位置:网站首页>Scripy tutorial - (2) write a simple crawler
Scripy tutorial - (2) write a simple crawler
2022-04-23 20:22:00 【Winding Liao】
Scrapy course - (2) Write a simple reptile
Purpose : Crawl through all the book names on this page , Price ,url, Inventory , Comments and cover pictures . This paper is based on Website For example
Check robotstxt_obey
Create good scrapy project After , Come first settings.py find ROBOTSTXT_OBEY, And set it to False.
( This action means not complying with the website's robots.txt, Please apply after obtaining the approval of the website . Note : This website is a sample practice website .)
Look at the location of the elements
Back to the example website , Press F12 Open developer tools .

Start with 2 A little exercise to familiarize yourself with xpath ~
First , The title of the book is h3 Inside a tag Inside , Location xpath as follows :
// parse book titles
response.xpath('//h3/a/@title').extract()
// extract Can parse out all title The name of
// If you use extract_first() Will resolve the first title The name of
Then check the price location ,xpath as follows :
// parse book price
response.xpath('//p[@class="price_color"]/text()').extract()
lookup url Is quite important , Because we have to find all the books first url, Further in request all url, And get the information we want , Its xpath as follows :
response.xpath('//h3/a/@href').extract_first()
// Output results : 'catalogue/a-light-in-the-attic_1000/index.html'
Request The first book
Then observe url It can be found that , What has just been resolved is the suffix of the book website , That means we have to add the prefix , Is a complete url. So here , Let's start writing the first function.
def parse(self, response):
// Find all the books url
books = response.xpath('//h3/a/@href').extract()
for book in books:
// Combine URL prefix with suffix
url = response.urljoin(book)
yield response.follow(url = url,
callback = self.parse_book)
def parse_book(self, response):
pass
Parse Data
def parse_book(self, response):
title = response.xpath('//h1/text()').extract_first()
price = response.xpath('//*[@class="price_color"]/text()').extract_first()
image_url = response.xpath('//img/@src').extract_first()
image_url = image_url.replace('../../', 'http://books.toscrape.com/')
rating = response.xpath('//*[contains(@class, "star-rating")]/@class').extract_first()
rating = rating.replace('star-rating', '')
description = response.xpath('//*[@id="product_description"]/following-sibling::p/text()').extract_first()
View the analysis results
Here you can use yield To view the analysis results :
// inside parse_book function
yield {
'title': title,
'price': price,
'image_url': image_url,
'rating': rating,
'description': description}
Complete a simple crawler
def parse(self, response):
// Find all the books url
books = response.xpath('//h3/a/@href').extract()
for book in books:
// Combine URL prefix with suffix
url = response.urljoin(book)
yield response.follow(url = url,
callback = self.parse_book)
def parse_book(self, response):
title = response.xpath('//h1/text()').extract_first()
price = response.xpath('//*[@class="price_color"]/text()').extract_first()
image_url = response.xpath('//img/@src').extract_first()
image_url = image_url.replace('../../', 'http://books.toscrape.com/')
rating = response.xpath('//*[contains(@class, "star-rating")]/@class').extract_first()
rating = rating.replace('star-rating', '')
description = response.xpath('//*[@id="product_description"]/following-sibling::p/text()').extract_first()
yield {
'title': title,
'price': price,
'image_url': image_url,
'rating': rating,
'description': description}
Execution crawler
scrapy crawl <your_spider_name>
版权声明
本文为[Winding Liao]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204232021221091.html
边栏推荐
- Rédaction de thèses 19: différences entre les thèses de conférence et les thèses périodiques
- STM32 Basics
- PostgreSQL basic functions
- go-zero框架数据库方面避坑指南
- selenium. common. exceptions. WebDriverException: Message: ‘chromedriver‘ executable needs to be in PAT
- . Ren -- the intimate artifact in the field of vertical Recruitment!
- JDBC database addition, deletion, query and modification tool class
- selenium.common.exceptions.WebDriverException: Message: ‘chromedriver‘ executable needs to be in PAT
- ArcGIS JS version military landmark drawing (dovetail arrow, pincer arrow, assembly area) fan and other custom graphics
- Recommend an open source free drawing software draw IO exportable vector graph
猜你喜欢

WordPress插件:WP-China-Yes解决国内访问官网慢的方法
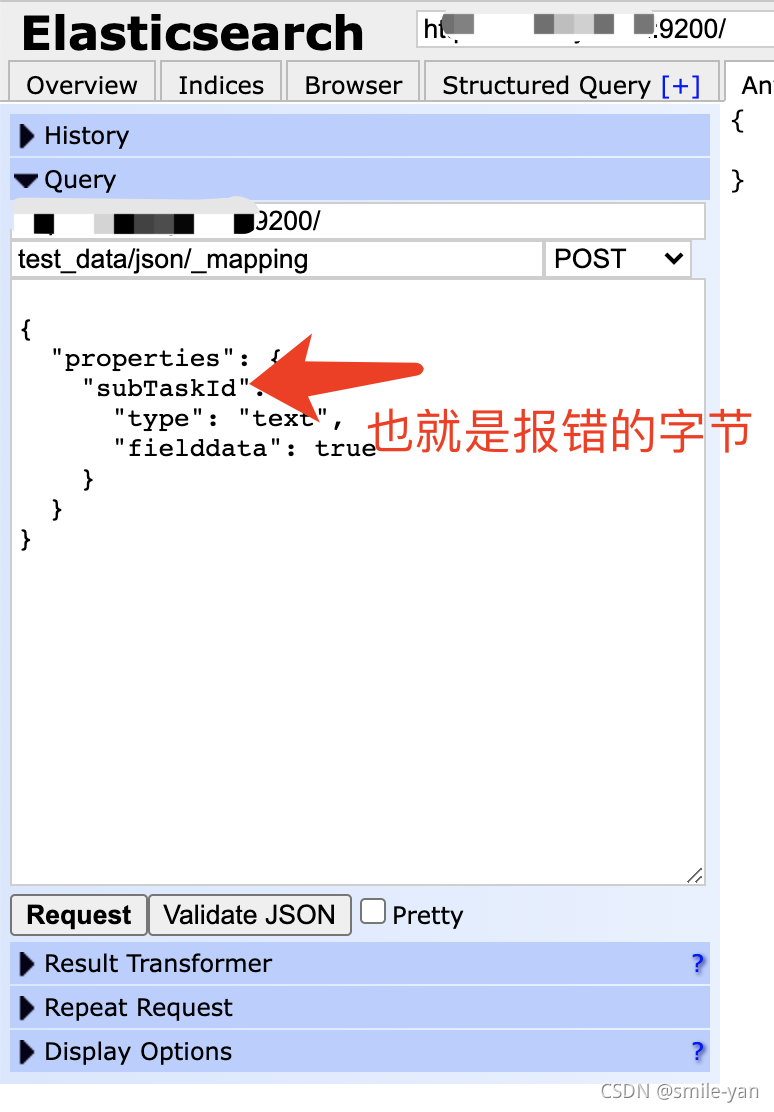
Es keyword sorting error reason = fielddata is disabled on text fields by default Set fielddata = true on keyword in order

Don't bother tensorflow learning notes (10-12) -- Constructing a simple neural network and its visualization
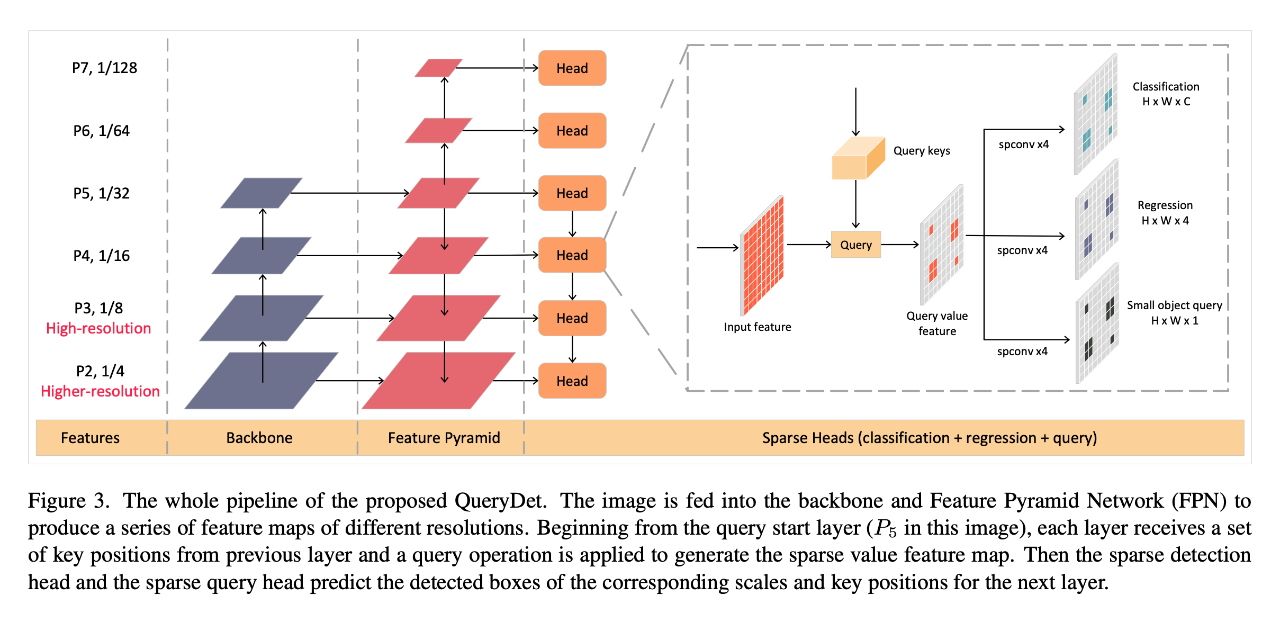
CVPR 2022 | QueryDet:使用级联稀疏query加速高分辨率下的小目标检测
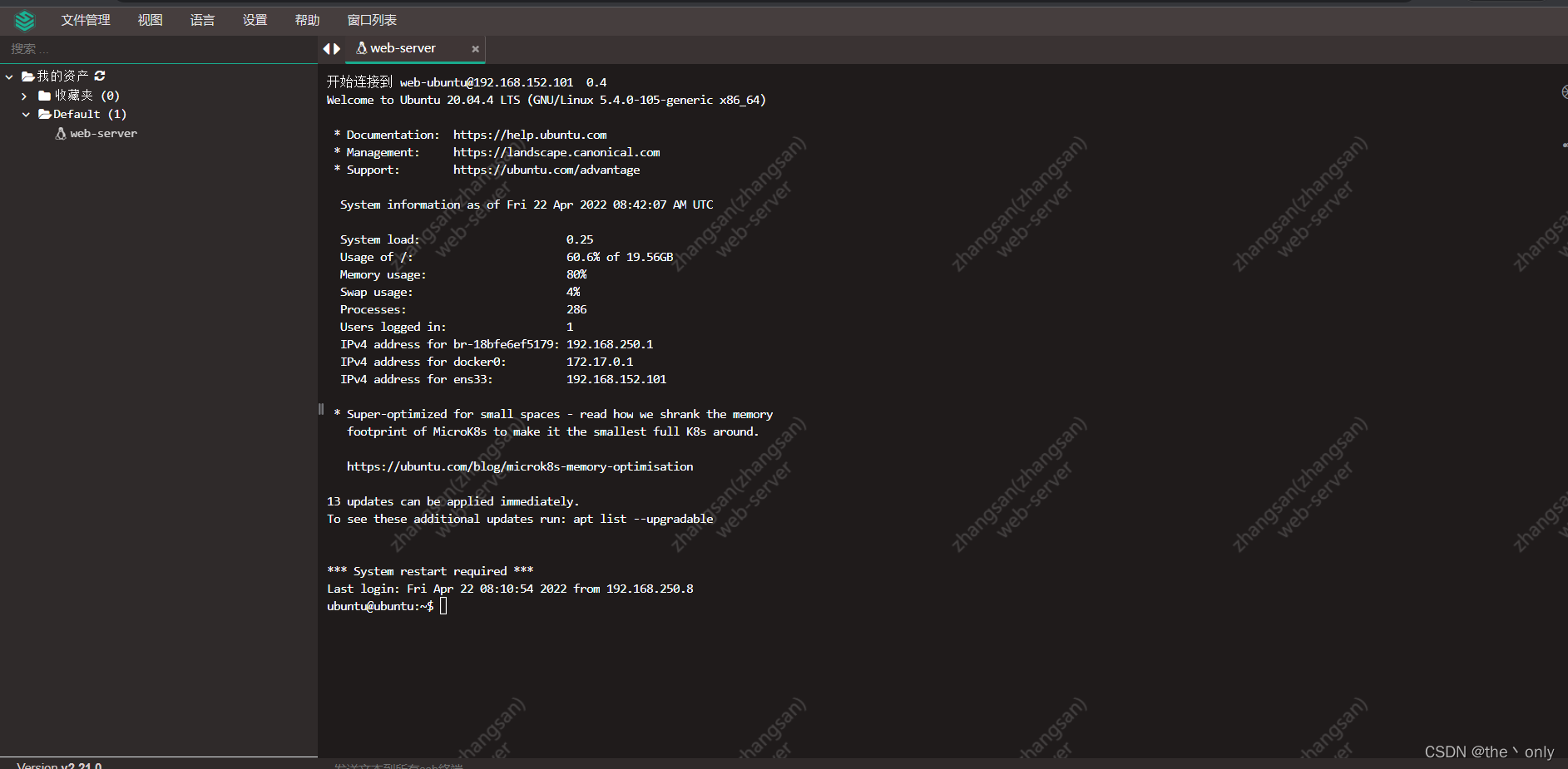
堡垒机、跳板机JumpServer的搭建,以及使用,图文详细
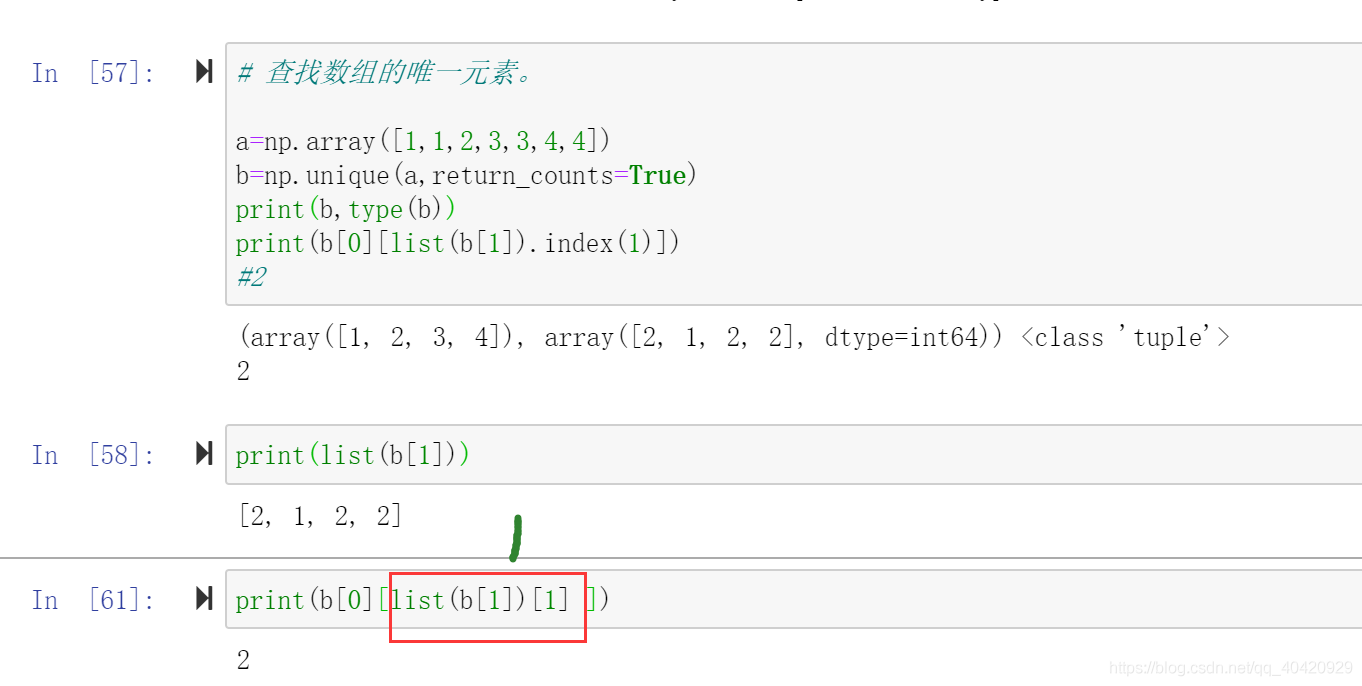
Operation of numpy array
Identification of bolt points in aerial photography based on perception
Some basic configurations in interlij idea

【目标跟踪】基于帧差法结合卡尔曼滤波实现行人姿态识别附matlab代码
16MySQL之DCL 中 COMMIT和ROllBACK
随机推荐
Redis的安装(CentOS7命令行安装)
【PTA】L2-011 玩转二叉树
Commit and rollback in DCL of 16 MySQL
Computing the intersection of two planes in PCL point cloud processing (51)
Customize timeline component styles
Building the tide, building the foundation and winning the future -- the successful holding of zdns Partner Conference
2022 - Data Warehouse - [time dimension table] - year, week and holiday
R语言使用timeROC包计算无竞争风险情况下的生存资料多时间AUC值、使用confint函数计算无竞争风险情况下的生存资料多时间AUC指标的置信区间值
nc基础用法
[target tracking] pedestrian attitude recognition based on frame difference method combined with Kalman filter, with matlab code
R语言ggplot2可视化:ggplot2可视化散点图并使用geom_mark_ellipse函数在数据簇或数据分组的数据点周围添加椭圆进行注释
Identification of bolt points in aerial photography based on perception
还在用 ListView?使用 AnimatedList 让列表元素动起来
ArcGIS js api 4. X submergence analysis and water submergence analysis
Common form verification
腾讯邱东洋:深度模型推理加速的术与道
[talkative cloud native] load balancing - the passenger flow of small restaurants has increased
PostgreSQL basic functions
Sqoop imports tinyint type fields to boolean type
How does onlyoffice solve no route to host