当前位置:网站首页>OAK-D树莓派点云项目【附详细代码】
OAK-D树莓派点云项目【附详细代码】
2022-04-23 15:57:00 【OAK中国_官方】
编辑:OAK中国
首发:oakchina.cn
喜欢的话,请多多️
前言
Hello,大家好,这里是OAK中国,我是助手君。
本文来自IBM工程师Richard Hopkins的教程,由OAK中国整理更新。
Part 1

OAK-D是一款超棒的深度相机和AI加速器, 它默认创建的深度流是1280 x 800像素。每个深度测量值都是一个16位无符号整数,代表以毫米为单位的深度(65535表示该像素没有深度信息可用)。在一台功能强大的电脑上,将这些数据与彩色相机结合起来,我相信有可能生成一些非常惊人的点云!
我对K9(作者的机器人项目)的第一个应用是研究如何使用摄像头来增强他的碰撞检测能力;为此,我不需要彩色点云——每秒钟生成一千万个点的点云无疑会让我的树莓派超负荷。 随着我更多地学习使用OAK-D,也许有可能直接在OAK-D上生成点云,但目前让我们看看我是否能做一些简单的事情。
减小最小深度检测距离
第一个任务是减少OAK-D能够探测深度的最小距离。默认情况下,这意味着最小深度为69厘米,而相机可以聚焦到19.6厘米。造成这种差异的原因是,相机能够检测到的两幅图像的最大差异是96像素。 当然,如果你把图像变小,这96个像素的差距就会变得更加显著,相机的潜在最小深度也会变小。
因此,为避免碰撞而改进深度检测的最简单方法是在设置OAK-D管道时降低黑白深度相机的分辨率。 这有一个额外的好处,就是减少了树莓派要处理的图像数据量。正如你在视频中所看到的,我的快速原型在不到30厘米的范围内工作得很好!
降低分辨率并移除“无深度”数据
第二步是进一步降低分辨率,使K9能够将数据转换为点云。 最后我决定使用skimage.measure.blockreduce来降低图像的分辨率。 我没有对整个区块的像素值进行平均,而是选择使用区块内的最小值(即测量的最近距离)。 这给出了一个 "最坏的情况",并使区块缩小算法能够自动删除没有深度信息的像素。
去除瞬时噪声
对图像进行20倍的抽取,可以很好地去除图像中的未知深度信息。 它还将其体积从每秒1000万点减少到更容易管理的6400点。 然而,图像中仍有一些随机噪声的证据,所以我决定利用剩余的少量点来平均最后两帧的值。最终的结果是相当可靠的,可以在视频中看到。 下一步,生成一个点云!
Part 2
在这篇文章的Part 1,我从OAK-D 3D相机中获取了深度信息流到树莓派中,并通过对640 x 400的数据馈送进行抽取,选择每20x20像素最接近的深度测量,大大减少了数据量。这给了我一个32x20的深度图,用于每秒10次的点云转换。点云将使K9能够以比目前更精细的纹理和更大的距离了解它面前的东西。
为什么要使用点云?
尽管来自OAK-D的深度数据的分辨率比K9耳朵上的11美元激光雷达要高得多,而且工作距离也远得多,但仅仅测量一切事物的深度并不能帮助机器人立即了解其周围的环境。为什么不能? 嗯,因为你想一想,当地板开始离机器人很近,然后退到远处,但地板并不是障碍物! 机器人怎么能分辨出地板和它要撞上的东西之间的区别?
一种方法可能是将机器人放在一个完全平坦和空旷的地板上,测量地板的深度,并在他移动时从传感器读数中减去这些深度测量值。如果在你期望看到地板的地方的测量值是不正确的,那么这将表明有障碍物需要避开。这种技术的缺点是,一个斜坡可能会导致整个地板被识别为障碍物。 此外,它没有解决另一个重要的问题——如果远处有障碍物,它们之间有间隙,机器人如何判断它是否能穿过这个间隙?
更好的解决方案是使用三角学,根据深度测量值在相机图片中的位置,将深度测量值“投影”到内存中的3D地图中。如果我们知道机器人的摄像头的位置(或者更准确地说,深度地图的测量位置),那么所有的深度测量值都可以根据它们在图片中的位置从该点投影出来。 例如,从图像中间以下的测量值会向下投影,测量值离中间越远,投影的角度就越大。
如果测量质量好,数学计算正确,那么当机器人看到地面时,该点将被投影出来,其高度正好是摄像机的高度,但为负数。 如果你把投影点的高度值和摄像机的高度值相加,你应该得到一个非常接近零的数字——这意味着机器人可以安全地穿越该点。 如果你得到的高度是一个明显的正数,那么在距离摄像机的那个深度就可能有障碍物。 另外,如果你得到一个明显的负数,那么你的机器人可能正在接近一个楼梯或一个大洞。
在我们的案例中,根据原始深度图像的分化程度,这导致需要将25万(640 x 400)或(32 x 20)640的深度测量值投射到 "点云 "中,每秒10次。 这很有可能是每秒超过200万个点,也有可能是只有7000个点。 现在,在一台强大的计算机上,250万可能是可能的,但在树莓派上,我认为我们可能不得不走向低端!
那么,有什么最快的方法可以做到这一点呢?当我看到一个必须快速处理图像数据的问题时,我总是选择名为numpy的Python库。Numpy在处理多维数组方面非常有效——而图片只是大的二维数组。
使用numpy,我能够开发出一些相当高效的Python代码,将OAK-D相机看到的全部复杂内容转化为简单的数字字符串,以便传输到K9的短期存储器。 在那里,K9可以使用这些快速变化但简单的数据来确定哪些方向对它来说是安全的。
它是如何工作的?
Numpy是一个出色的Python库,它使你能够快速处理多维数组。 这是一种神奇的、强大的、快速的能力——而且它在树莓派上也能工作。
开发这段代码是一个挑战,因为我知道我需要使用numpy来使代码高效,这意味着要避免循环。 使用numpy直接转换一个数组和使用几个for循环来迭代一个numpy数组之间的性能差异就像白天和黑夜。 原生 "numpy比numpy/循环混合运算快100倍并不罕见。 在树莓派上,每一个机器周期都很重要,在这种情况下,这可能意味着给他缓慢而粗糙的环境感应与精细的高度反应的感应之间的区别。 如果numpy代码非常高效,我可能能够处理100倍的数据,因此,与其将传感器流减去20倍,我们可能只需减去2倍即可。
校准代码
我为K9使用的树莓派4足够强大,以至于我能够使用托管在树莓派上的Jupyter Notebook来迭代和渐进地开发代码。 Jupyter Notebook是一个Python解释器,使你能够在同一时间内反复编写、记录和测试代码。通过合适的库,你还可以在笔记本中显示图形和图像。我正是用这个功能来生成下面的图片,并在编程时使用摄像机的实时流来创建代码。
这意味着树莓派和OAK-D相机可以放在休息室里(那里有一大片平坦的地板),而我可以在沙发上的Mac上用笔记本开发。使用Notebook是使用numpy进行开发的一种快速的方法。 你可以在笔记本中看到你正在做什么。 下面一连串的图片显示了我用来开发代码的渐进式方法。
为了开发代码,我基本上清空了我们休息室的地板,这样我就有了一个很好的空旷的平坦空间。相机被放在一个三脚架上,与它在机器人上的高度一致。为了使我能够校准算法,我使用了三个茶叶罐,我知道它们有150毫米高和100毫米宽。为了加快速度,我把饮料杯垫放在地板上,形成一个大的网格。 这使我能够快速移动茶叶罐,而不需要每次都测量它们与摄像机的距离。


如果我可以把相机看到的东西转化为三个大小合适的罐头,在我的网格上的正确位置,我就知道我的点云算法是有效的。 这是我开始使用的图片。图中有三个罐子,但即使是人也不容易把它们挑出来——还注意到地板是如何退到远处的。
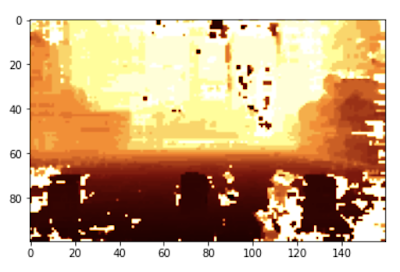
经过相当多的调整,我能够计算出这个点云版本——正如你所看到的,地板已经消失了,我们只能看到三个罐子,它们显然是坐在地板上。 这对机器人来说,处理起来就容易多了。
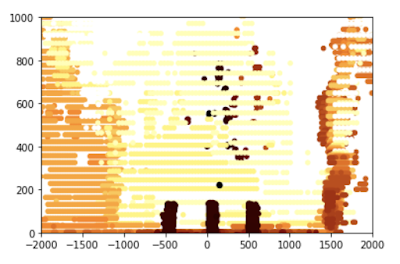
为了微调机器人的感觉,我能够使用笔记本只在图中分离出一个罐子;鉴于我知道这个罐子的大小,我能够微调算法。
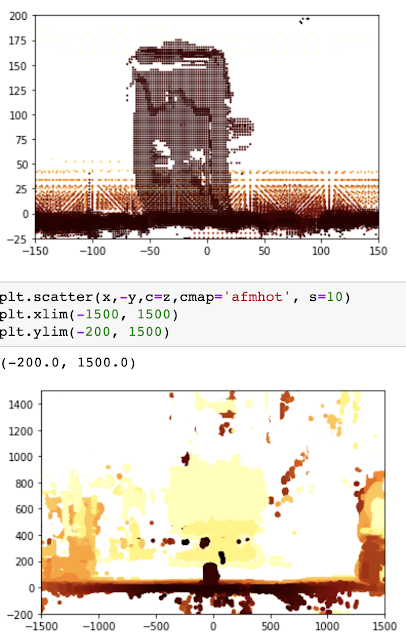
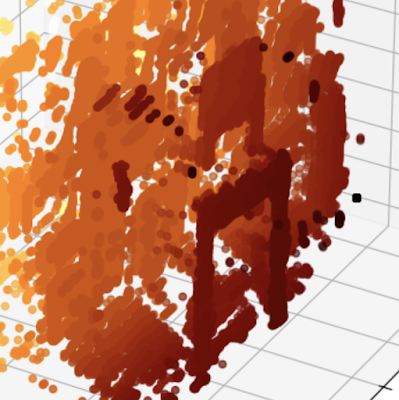
一旦Jupyter Notebook在简单的罐子上工作得很好、很准确,是时候在一个更随机的环境中尝试一下了,所以我把它指向一张餐椅,并在笔记本中以3D方式绘制生成的点云(而不是我在校准算法时使用的2D可视化)。 这段代码并没有在K9中使用,但它给人一种计算结果的良好感觉。
代码
代码很短,但很密集--大部分的处理都是在25行内完成的。 K9是一个相当简单的机器人模型--他大约有50厘米宽,80厘米高。 他不能以任何有意义的方式躲避或改变形状,所以对于路线规划和碰撞检测的目的,我们需要知道的是在机器人前面的各个点上最近的障碍物是哪里。 K9可以安全地忽略高度小于5厘米的障碍物,或者是那些在空中开始超过80厘米的障碍物。因此,为了保持简单,代码将K9两边两米的区域翻译成10厘米分辨率的网格。 对于每一个10厘米的小块,都记录了与最近的障碍物的距离。
如果你有一个更复杂的机器人或无人机,那么将网格(在下面的步骤5中达成)翻译成八叉树表示,就不需要步骤6了。 如果K9变得足够复杂,需要开始组装其周围环境的全貌,那么我将使用他的短期记忆Redis数据库来存储八叉树。
这段代码有注释,但下面的演练可能有助于理解它在做什么:
- 前45行只是将OAK-D相机设置为较低分辨率深度模式和每秒10帧。这样做是为了减少数据量,也是为了减少相机可以检测到的最小深度。
- 第51行抽取输入深度图(抽取变量描述了这种情况发生的程度,从1到20的数字已经过测试,工作正常)
- 第54到64行完成了将深度图图像中的每个点(被视为2D阵列)转换为三维点(x,y和z)的艰巨工作。
- 第65至71行将结果点过滤为机器人需要担心的点(机器人两侧超过两米且高于800毫米的点被忽略——这是因为K9高80厘米)
- 然后,线72至80将x、y、z点排列成一个40×8的10厘米正方形二维网格(400厘米×80厘米)。然后计算网格每一段内所有点的平均距离。
- 第83行到第87行采用40×8的网格,并进一步简化为一维40位数组;这通过简单地决定40列中的每一列中哪个块是最近的来完成。
由从第50行开始的所有处理只有在树莓派上才能有效工作,这是因为使用了numpy和相关的库,将二维深度图处理成三维数组,然后再回落到单维数组。 单维深度数组使K9很容易知道他在哪里可以尝试旅行,哪里不可以。
!/usr/bin/env python3
# coding: utf-8
import cv2
import depthai
import numpy as np
import pandas as pd
device = depthai.Device('', False)
body_cam = device.create_pipeline(config={
"streams": ["depth"],
"ai": {
"blob_file": "/home/pi/depthai/resources/nn/face-detection-retail-0004/face-detection-retail-0004.blob.sh14cmx14NCE1",
"blob_file_config": "/home/pi/depthai/resources/nn/face-detection-retail-0004/face-detection-retail-0004.json",
'shaves' : 14,
'cmx_slices' : 14,
'NN_engines' : 1,
},
"camera": {
"mono": {
# 1280x720, 1280x800, 640x400 (binning enabled)
# reducing resolution decreases min depth as
# relative disparity is decreased
'resolution_h': 400,
'fps': 10
}
}
})
if body_cam is None:
raise RuntimeError("Error initializing body camera")
decimate = 5
max_dist = 4000.0
height = 400.0
width = 640.0
cx = width/decimate/2
cy = height/decimate/2
fx = 1.4 # values found by measuring known sized objects at known distances
fy = 2.05
x_bins = pd.interval_range(start = -2000, end = 2000, periods = 40)
y_bins = pd.interval_range(start= 0, end = 800, periods = 8)
data_packets = body_cam.get_available_data_packets()
for packet in data_packets:
if packet.stream_name == 'depth':
frame = packet.getData()
# Reduce size of depth map
frame = skim.block_reduce(frame,(decimate,decimate),np.min)
height, width = frame.shape
# Convert depth map to point cloud with valid depths
column, row = np.meshgrid(np.arange(width), np.arange(height), sparse=True)
valid = (frame > 200) & (frame < max_dist)
z = np.where(valid, frame, 0)
x = np.where(valid, (z * (column - cx) /cx / fx) + 120 , max_dist)
y = np.where(valid, 325 - (z * (row - cy) / cy / fy) , max_dist)
# Flatten point cloud axes
z2 = z.flatten()
x2 = x.flatten()
y2 = y.flatten()
# Stack the x, y and z co-ordinates into a single 2D array
cloud = np.column_stack((x2,y2,z2))
# Filter the array by x and y co-ordinates
in_scope = (cloud[:,1]<800) & (cloud[:,1] > 0) & (cloud[:,0]<2000) & (cloud[:,0] > -2000)
in_scope = np.repeat(in_scope, 3)
in_scope = in_scope.reshape(-1, 3)
scope = np.where(in_scope, cloud, np.nan)
# Remove invalid rows from array
scope = scope[~np.isnan(scope).any(axis=1)]
# Index each point into 10cm x and y bins (40 x 8)
x_index = pd.cut(scope[:,0], x_bins)
y_index = pd.cut(scope[:,1], y_bins)
# Place the depth values into the corresponding bin
binned_depths = pd.Series(scope[:,2])
# Average the depth measures in each bin
totals = binned_depths.groupby([y_index, x_index]).mean()
# Reshape the bins into a 8 x 40 matrix
totals = totals.values.reshape(8,40)
# Determine the nearest segment for each of the 40
# horizontal segments
closest = np.amin(totals, axis = 0 )
# Round the to the nearest 10cm
closest = np.around(closest,-2)
# Turn into a 1D array
closest = closest.reshape(1,-1)
print(closest)
if cv2.waitKey(1) == ord('q'):
break
del body_cam
del device参考资料
https://docs.oakchina.cn/en/latest/
https://www.oakchina.cn/selection-guide/
OAK中国
| OpenCV AI Kit在中国区的官方代理商和技术服务商
| 追踪AI技术和产品新动态
戳「+关注」获取最新资讯
版权声明
本文为[OAK中国_官方]所创,转载请带上原文链接,感谢
https://blog.csdn.net/oakchina/article/details/124352068
边栏推荐
- JS regular détermine si le nom de domaine ou le chemin de port IP est correct
- IronPDF for .NET 2022.4.5455
- 5 minutes, turn your excel into an online database, the magic cube net table Excel database
- [section 5 if and for]
- 捡起MATLAB的第(10)天
- API IX JWT auth plug-in has an error. Risk announcement of information disclosure in response (cve-2022-29266)
- Accumulation of applet knowledge points
- 撿起MATLAB的第(9)天
- Day (10) of picking up matlab
- Sortby use of spark operator
猜你喜欢
TIA博图——基本操作
撿起MATLAB的第(9)天
Codejock Suite Pro v20.3.0
matplotlib教程05---操作图像
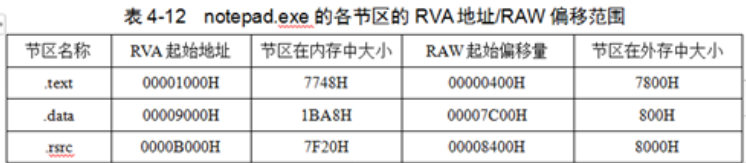
Import address table analysis (calculated according to the library file name: number of imported functions, function serial number and function name)
IronPDF for .NET 2022.4.5455
Day (9) of picking up matlab

Vision of building interstellar computing network
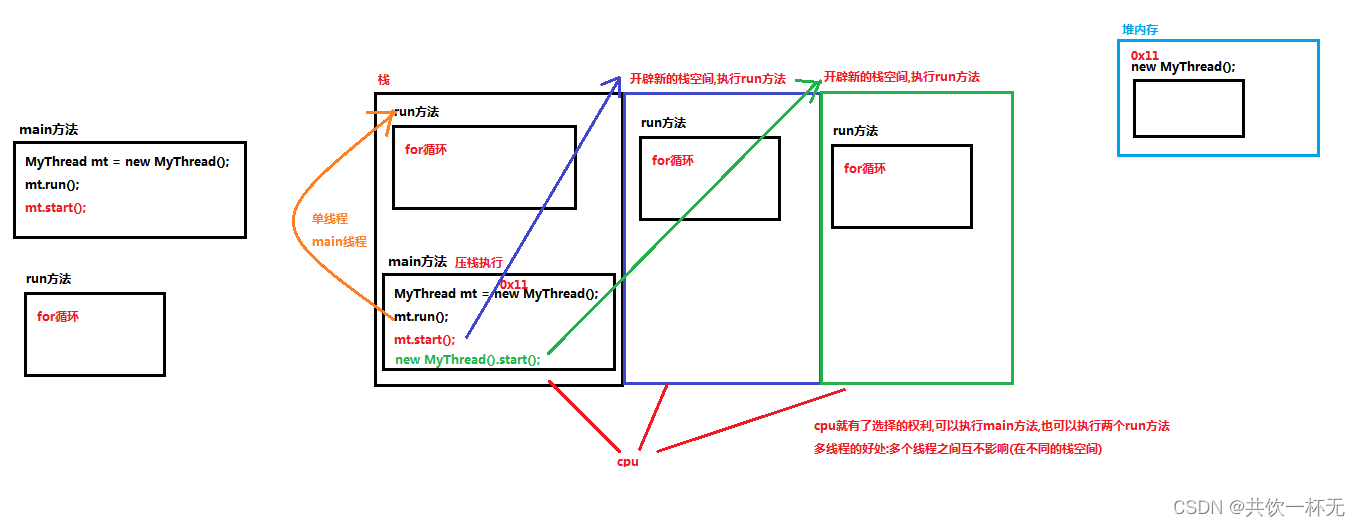
The principle and common methods of multithreading and the difference between thread and runnable
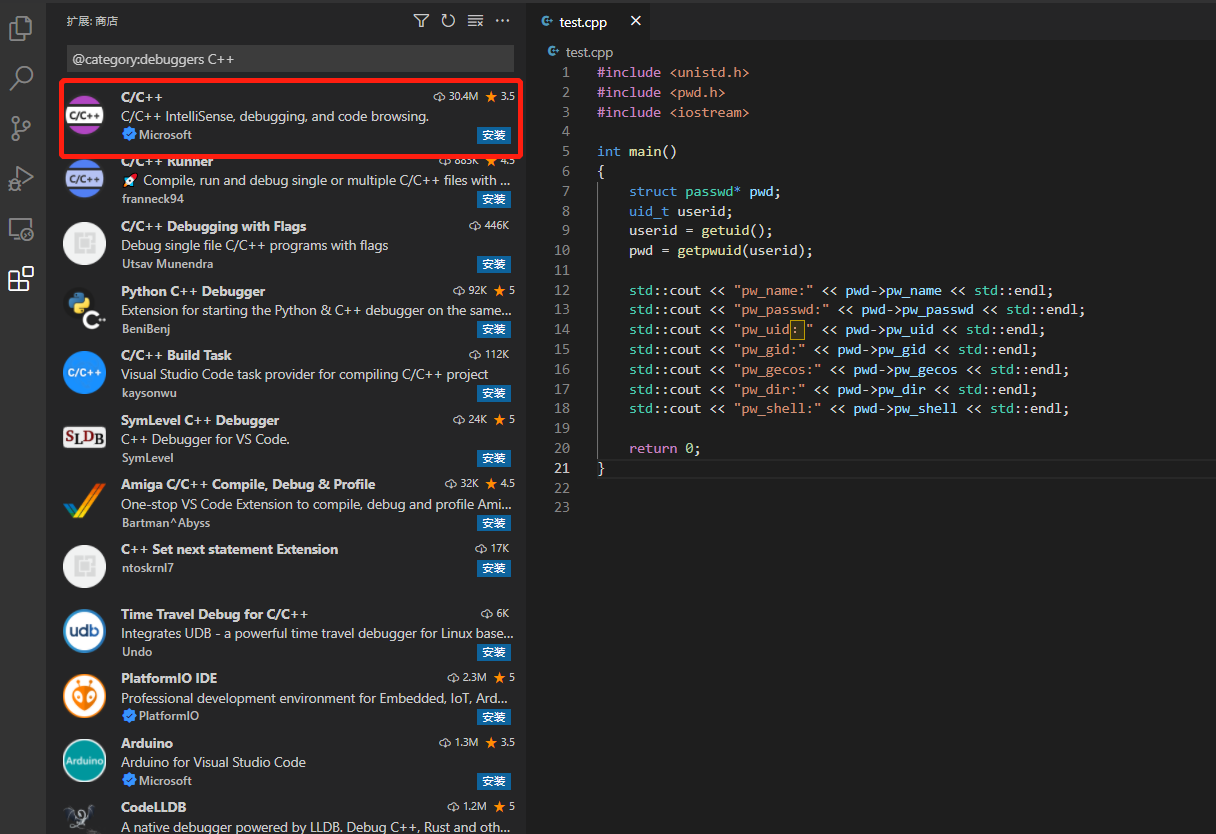
Master vscode remote GDB debugging
随机推荐
Timing model: gated cyclic unit network (Gru)
Leetcode-396 rotation function
Treatment of idempotency
Codejock Suite Pro v20. three
Compile, connect -- Notes
Go language, condition, loop, function
捡起MATLAB的第(4)天
TIA botu - basic operation
Import address table analysis (calculated according to the library file name: number of imported functions, function serial number and function name)
一文掌握vscode远程gdb调试
MySQL Cluster Mode and application scenario
单体架构系统重新架构
Go language, array, pointer, structure
matplotlib教程05---操作图像
5 minutes, turn your excel into an online database, the magic cube net table Excel database
API IX JWT auth plug-in has an error. Risk announcement of information disclosure in response (cve-2022-29266)
Spark 算子之partitionBy
布隆过滤器在亿级流量电商系统的应用
WPS brand was upgraded to focus on China. The other two domestic software were banned from going abroad with a low profile
Deletes the least frequently occurring character in the string