当前位置:网站首页>MySQL Cluster Mode and application scenario
MySQL Cluster Mode and application scenario
2022-04-23 15:39:00 【dengk2013】
Flow saving assistant :
Single library mode : One mysql The database carries all relevant data .
Read write separation cluster mode : Add an intermediate layer on the original basis , It forms a read-write separated cluster with the back-end data set . Overall infrastructure : The original main library is derived from the word library 1, Word stock 2,
utilize mysql The original master-slave synchronization mechanism ( That is to say :binlog Log synchronization ), Reproduce the data changes of the master database in the slave database , Ensure data synchronization . The main library is generally used for write processing ,
Read from library . details : If you operate directly on the main database, you cannot complete the read-write separation , You need to allocate sharded middleware at the front end ( Ali mycat, JD.COM ShardingSphere),
The middleware passes curd request , To decide which library to handle .MHA Middleware to achieve high availability ( namely : The main server is broken ,MHA Middleware can promote a table from the master server ).
All node data is kept synchronized . It is suitable for reading more and writing less , A single watch is no more than ten million Internet applications .
Sub database and sub table ( Fragmentation ) Cluster pattern : One mysql When the database doesn't hold . Divide the data of the database into different node databases ( namely : The data of the node database is combined into a complete data body ).
Middleware is needed for routing .( Yes sql To analyze , Send the request to the corresponding database , The process of distributing requests is called routing ). No high availability .
Why do big factories make vertical tables ?
There are too many fields in a table. You need to make a vertical table .
What is a horizontal scale ?
Split data in behavioral units ( Range method ,hash Law ). characteristic : All tables have exactly the same structure . Used to solve the storage problem of large amount of data .
What is a vertical sub table ?
Split the table into columns 2 More than one small watch , Get data through primary foreign key Association .
Why do you do this ?
Need to know mysql Of InnoDB Processing engine .
Row data is called :row
The basic unit of management data is called page :page; The default size of each page :16k
The unit in which the page is saved is called the area :Extent.
Relationship : The area consists of consecutive pages , A page consists of consecutive lines .1024/16=64( namely : One 1M There are 64 A page )
InnoDB1.0 New features after , Compress pages .
Compress pages : Compress the underlying data , Make the actual size smaller than the logical size .
In the process of retrieving data across pages , The efficiency of compression and decompression is low . At table design time , Store as many rows of data as possible in the page , Reduce cross page retrieval , Add in page search .
analysis :
1 The row data is 1K,1 page 16K, namely 1 page 16 Data ,1 Billion data needs 625 Ten thousand pages
After vertical paging ,1 The row data is 64 byte (1K=1024 byte ), namely 1 page 256 Data ,1 Billion data needs 40 Ten thousand pages . The data after paging is based on id And so on .
By splitting important fields into small tables , Let each page hold more rows of data , After page reduction , Reduce the data scanning range , Achieve the purpose of improving execution efficiency .
Vertical tabulation conditions :
1. The data of a single table reaches ten million
2. The field is over 20 individual , And contains vachar,CLOB,BLOB Etc
The field is enlarged according to the table :
Watch : Data query 、 Fields required for sorting ; Small fields for high frequency access
The big table : Low frequency access field ; Large field
Self incrementing primary key is not applicable in distributed environment .
Since self incrementing primary keys must be continuous , Therefore, the segmentation is carried out according to the range method ,ID The number of has been fixed . Cannot dynamically expand . Will produce “ Tail hot spot ” effect .
Tail hot spot : That is, after slicing according to the range method , The previous slice has stored data , The pressure of the last slice is very high .
Hash Slicing is more efficient .
Use UUID Replace self incrementing primary key ? Can not be 、
Involving the underlying mechanism of the database :
1.uuid, The only disorder . Disorder causes index rearrangement . When the primary keys are in order ,B+ The tree only needs to be appended to the original data .
How to solve ? Distributed and orderly primary key generation algorithm ?
Snowflake algorithm (SnowFlake), Twitter .
structure : Sign bit (1bit)+ Time stamp (41bit)+ machine ID(10bit)+ Sequence (12bit)
Usage method : Call directly JAR package
Snowflake algorithm needs to pay attention to the impact of time callback . May appear id The possibility of repetition
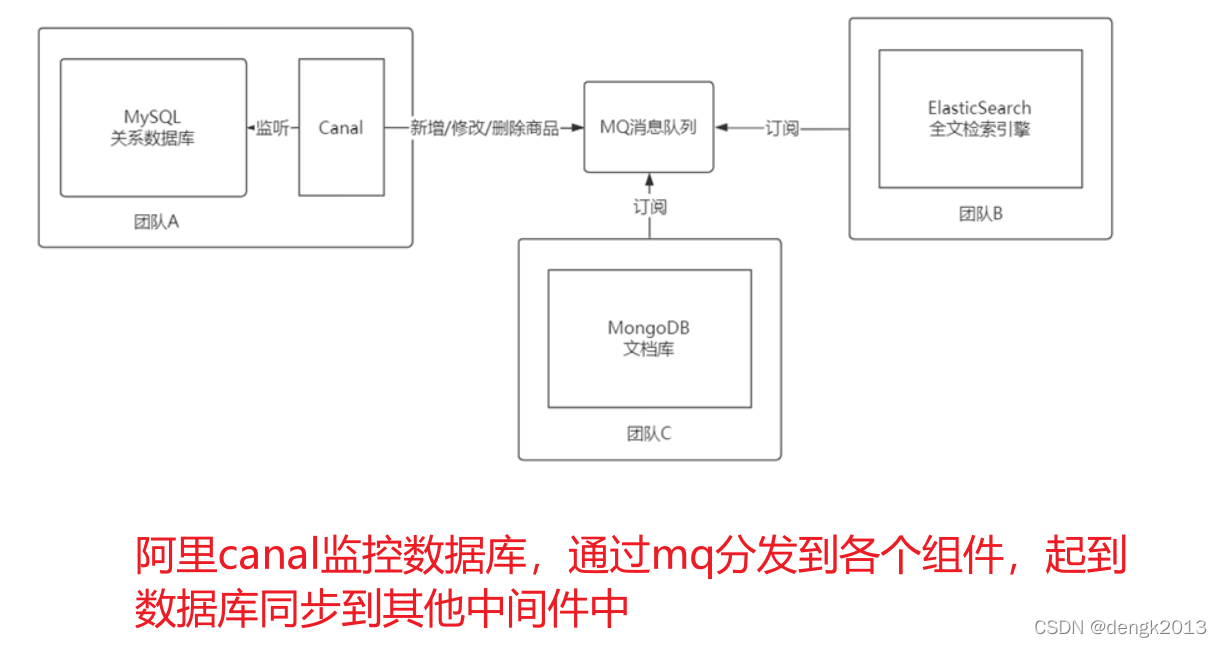
Ali canal

版权声明
本文为[dengk2013]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231537380354.html
边栏推荐
- Rsync + inotify remote synchronization
- Do keyword search, duplicate keyword search, or do not match
- 大厂技术实现 | 行业解决方案系列教程
- Special analysis of China's digital technology in 2022
- Advantages, disadvantages and selection of activation function
- 控制结构(一)
- 深度学习——超参数设置
- 【AI周报】英伟达用AI设计芯片;不完美的Transformer要克服自注意力的理论缺陷
- Demonstration meeting on startup and implementation scheme of swarm intelligence autonomous operation smart farm project
- Go并发和通道
猜你喜欢



随机推荐
Mobile finance (for personal use)
Detailed explanation of kubernetes (IX) -- actual combat of creating pod with resource allocation list
时序模型:门控循环单元网络(GRU)
现在做自媒体能赚钱吗?看完这篇文章你就明白了
JSON date time date format
网站某个按钮样式爬取片段
Explanation of redis database (I)
c语言---指针进阶
移动金融(自用)
怎么看基金是不是reits,通过银行购买基金安全吗
cadence SPB17. 4 - Active Class and Subclass
[leetcode daily question] install fence
【Leetcode-每日一题】安装栅栏
网站压测工具Apache-ab,webbench,Apache-Jemeter
Hj31 word inversion
Connectez PHP à MySQL via aodbc
CAP定理
Summary of interfaces for JDBC and servlet to write CRUD
Codejock Suite Pro v20.3.0
计算某字符出现次数