当前位置:网站首页>CVPR 2022 quality paper sharing
CVPR 2022 quality paper sharing
2022-04-23 15:43:00 【Polar chain AI cloud】
CVPR 2022 High quality paper sharing
A ConvNet for the 2020s
The paper :https://arxiv.org/abs/2201.0354
Code :https://github.com/facebookresearch/ConvNeXt

2020 Since then ,ViT It has always been a research hotspot .ViT The performance of image classification exceeds that of convolutional network , Various variants developed later will ViT Carry forward ( Such as Swin-T,CSwin-T etc. ), It is worth mentioning that Swin-T The sliding window operation in is similar to the convolution operation , Reduced computational complexity , bring ViT It can be used as a backbone network for other visual tasks ,ViT It's getting hotter . This paper explores where the convolution network loses , Where is the limit of convolution network . In this paper , The author gradually moved towards ResNet Add structure ( Or use trick) To improve the performance of convolution model , In the end ImageNet top-1 It's done 87.8%. The author believes that the network structure proposed in this paper is a new generation (2020 years ) Convolution network of (ConvNeXt), Therefore, the article is named “2020 Convolution network in the s ”.
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
The paper :https://arxiv.org/abs/2203.00867
Code :https://github.com/DQiaole/ZITS_inpainting

In recent years , Great progress has been made in image restoration . However , It is still challenging to restore damaged images with vivid texture and reasonable structure . Because of convolutional neural networks (CNN) My receptive field is limited , Some specific methods can only deal with regular textures , The overall structure will be lost . On the other hand , Attention based models can better learn the remote dependence of structural recovery , But they are limited by a large number of calculations in large image size reasoning . To solve these problems , This paper proposes to use additional structure restorer to gradually promote image restoration . The proposed model uses a powerful attention based method in a fixed low resolution sketch space Transformer Model to restore the overall image structure .
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
The paper :https://arxiv.org/pdf/2203.00962.pdf
Code :https://github.com/zhaozhengChen/ReCAM

This paper introduces a very simple and efficient method : Use the name ReCAM Of softmax Cross entropy loss (SCE) Reactivate with BCE Convergence of CAM. Given an image , This article USES the CAM Extract the characteristic pixels of each class , And use them with class tags SCE Learn another fully connected layer ( After the trunk ). After convergence , This paper is based on CAM Extract... In the same way as in ReCAM. because SCE The contrasting nature of , Pixel responses are decomposed into different categories , Therefore, the expected mask ambiguity will be less . Yes PASCAL VOC and MS COCO Our assessment shows that ,ReCAM It can not only generate high-quality masks , It can also be in any CAM The variant supports plug and play with little overhead .

版权声明
本文为[Polar chain AI cloud]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231532052441.html
边栏推荐
- Neodynamic Barcode Professional for WPF V11.0
- Leetcode学习计划之动态规划入门day3(198,213,740)
- Upgrade MySQL 5.1 to 5.67
- 基础贪心总结
- PHP classes and objects
- What if the package cannot be found
- One brush 314 sword finger offer 09 Implement queue (E) with two stacks
- 布隆过滤器在亿级流量电商系统的应用
- How did the computer reinstall the system? The display has no signal
- 一刷313-剑指 Offer 06. 从尾到头打印链表(e)
猜你喜欢
电脑怎么重装系统后显示器没有信号了
Special analysis of China's digital technology in 2022
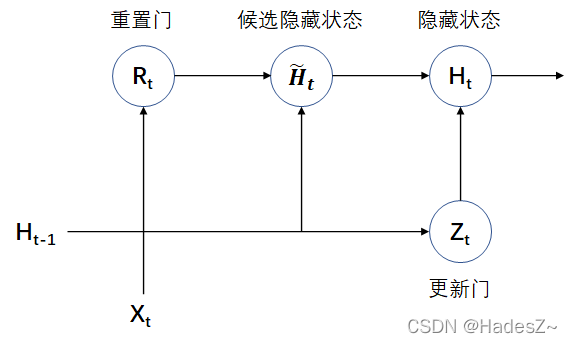
Timing model: gated cyclic unit network (Gru)
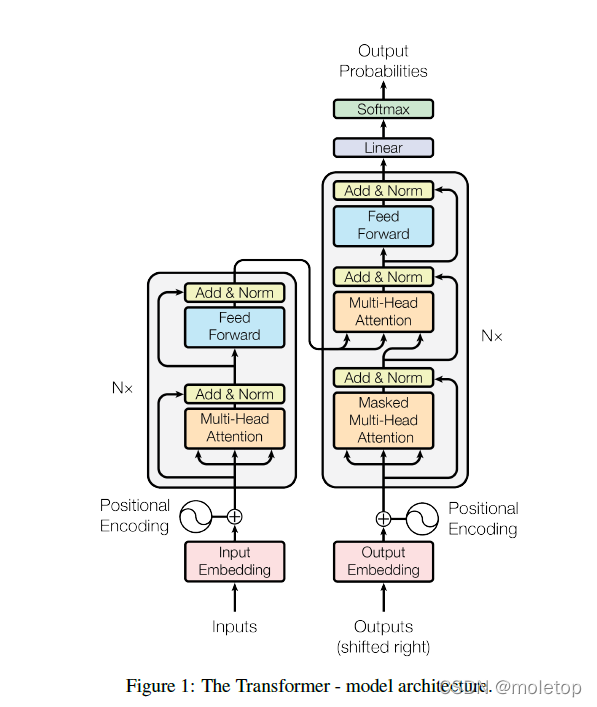
Sorting and replying to questions related to transformer
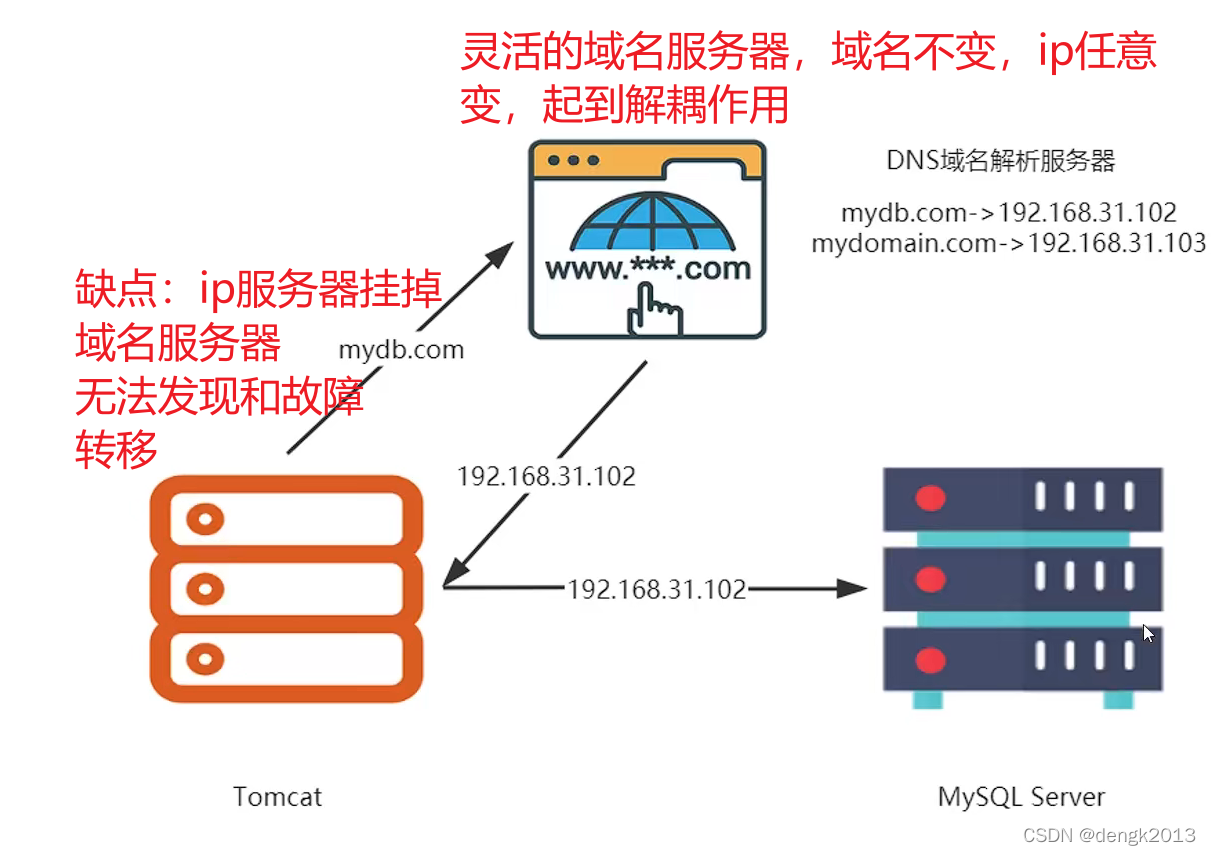
Why is IP direct connection prohibited in large-scale Internet
多级缓存使用

现在做自媒体能赚钱吗?看完这篇文章你就明白了
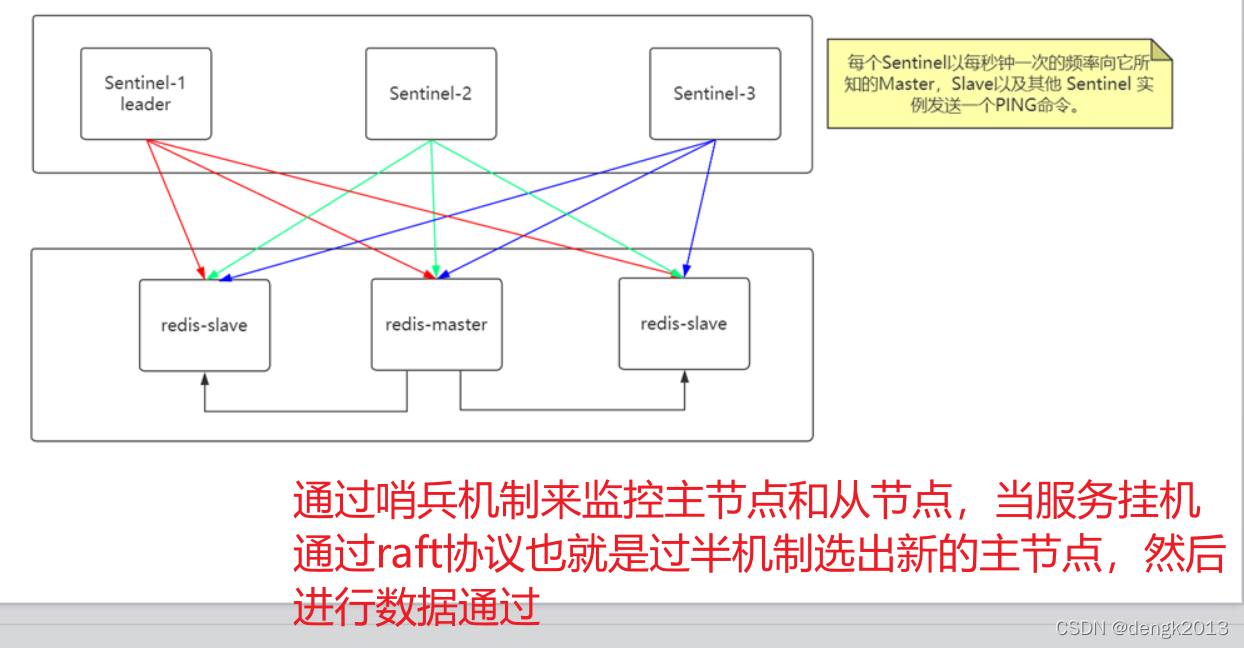
Redis主从复制过程
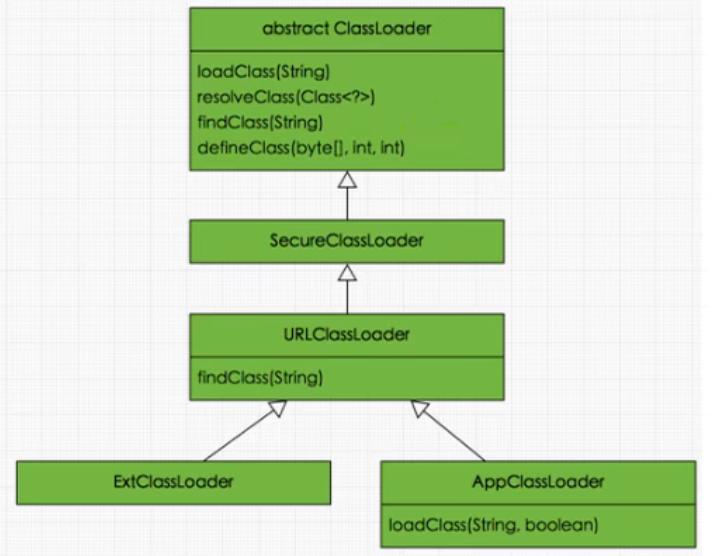
JVM-第2章-类加载子系统(Class Loader Subsystem)
Best practices of Apache APIs IX high availability configuration center based on tidb
随机推荐
软件性能测试报告起着什么作用?第三方测试报告如何收费?
现在做自媒体能赚钱吗?看完这篇文章你就明白了
WPS品牌再升级专注国内,另两款国产软件低调出国门,却遭禁令
小程序知识点积累
Extract non duplicate integers
Multi level cache usage
一刷312-简单重复set-剑指 Offer 03. 数组中重复的数字(e)
Best practices of Apache APIs IX high availability configuration center based on tidb
Cap theorem
一刷313-剑指 Offer 06. 从尾到头打印链表(e)
导入地址表分析(根据库文件名求出:导入函数数量、函数序号、函数名称)
控制结构(二)
大型互联网为什么禁止ip直连
pywintypes.com_error: (-2147221020, ‘无效的语法‘, None, None)
Why disable foreign key constraints
北京某信护网蓝队面试题目
Cookie&Session
木木一路走好呀
Go语言数组,指针,结构体
MultiTimer v2 重构版本 | 一款可无限扩展的软件定时器