当前位置:网站首页>MySQL集群模式與應用場景
MySQL集群模式與應用場景
2022-04-23 15:38:00 【dengk2013】
省流助手:
單庫模式:一個mysql數據庫承載所有相關數據。
讀寫分離集群模式:在原有的基礎上增加中間層,與後端數據集構成讀寫分離的集群。整體基礎結構:原有的主庫派生出字庫1,字庫2,
利用mysql原有的主從同步機制(即為:binlog日志同步),將主庫的數據變化在從庫中複現,保證數據同步。主庫一般用於寫入處理,
從庫負責讀取。細節:如果直接面對主庫進行操作無法完成讀寫分離,需要在前端分配分片中間件(阿裏mycat,京東ShardingSphere),
該中間件通過curd請求,來决定由哪個庫處理。MHA中間件實現高可用(即:主服務器壞了,MHA中間件可以將某個從錶提昇為主服務器)。
所有節點數據均保持同步。適用於讀多寫少,單錶不過千萬的互聯網應用。
分庫分錶(分片)集群模式:一個mysql數據庫撐不住的情况下。將數據庫的數據分到不同的節點數據庫(即:節點數據庫的數據合起來為完整的數據體)。
需要用到中間件進行路由。(對sql進行解析,將請求發到對應的數據庫,分發請求的過程叫路由)。不具備高可用性。
為什麼大廠做垂直分錶?
一張錶的字段太多需要做垂直分錶。
什麼是水平分錶?
以行為單比特對數據進行拆分(範圍法,hash法)。特點:所有的錶結構完全相同。用於解决數據量大的存儲問題。
什麼是垂直分錶?
將錶按列拆分成2張以上的小錶,通過主外鍵關聯獲取數據。
為什麼要這麼做?
需要了解mysql的InnoDB處理引擎。
行數據稱為:row
管理數據基本單比特稱為頁:page;每一頁的默認大小:16k
保存頁的單比特稱為區:Extent。
關系:區由連續頁組成,頁由連續行組成。1024/16=64(即:一個1M的區有64個頁)
InnoDB1.0後新特性,壓縮頁。
壓縮頁:對數據底層進行壓縮,使實際大小小於邏輯大小。
在跨頁檢索數據的過程中,壓縮和解壓縮的效率低。在錶設計時,盡可能在頁內多存儲行數據,减少跨頁檢索,增加頁內檢索。
分析:
1行數據為1K,1頁16K,即1頁16條數據,1億的數據需要625萬頁
垂直分頁後,1行數據為64字節(1K=1024字節),即1頁256條數據,1億的數據需要40萬頁。分頁後的數據根據id等關系進行快速提取。
通過將重要字段單獨剝離成小錶,讓每頁容納更多行數據,頁减少後,縮小數據掃描範圍,達到提高執行效率的目的。
垂直分錶條件:
1.單錶數據達千萬
2.字段超20個,且包含vachar,CLOB,BLOB等字段
字段放大小錶的依據:
小錶:數據查詢、排序時需要的字段;高頻訪問的小字段
大錶:低頻訪問字段;大字段
自增主鍵在分布式環境下不適用。
由於自增主鍵必須連續,所以按範圍法進行分片,ID的數量已固定。無法進行動態擴展。會產生“尾部熱點”效應。
尾部熱點:即按範圍法進行分片後,前面的分片已儲存數據,最後一個分片的壓力很大。
Hash分片的效率更高。
使用UUID替代自增主鍵嗎?不可以、
涉及數據庫底層機制:
1.uuid,唯一無序。無序導致索引重排。主鍵有序的情况下,B+樹只需要在原有的數據後面追加即可。
怎麼解决?分布式且有序的主鍵生成算法?
雪花算法(SnowFlake),推特公司。
結構:符號比特(1bit)+時間戳(41bit)+機器ID(10bit)+序列(12bit)
使用方法:直接調用JAR包
雪花算法需要注意時間回撥帶來的影響。可能出現id重複的可能
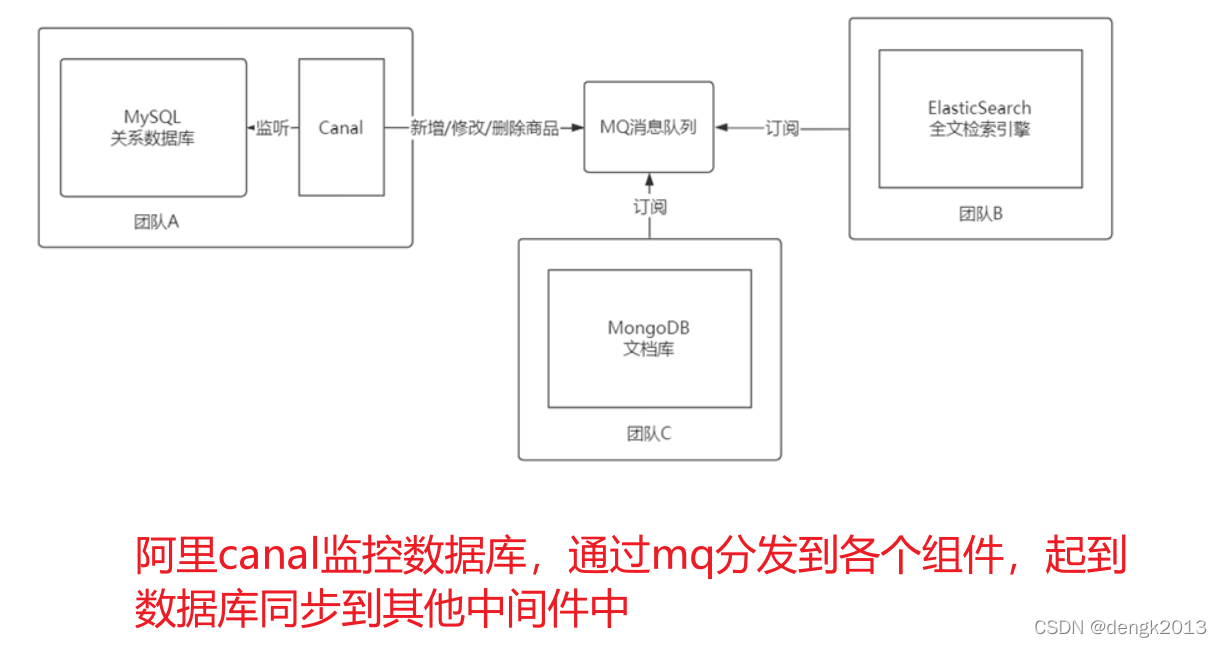
阿裏canal

版权声明
本文为[dengk2013]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231537380354.html
边栏推荐
- Multitimer V2 reconstruction version | an infinitely scalable software timer
- 推荐搜索 常用评价指标
- shell脚本中的DATE日期计算
- Differential privacy (background)
- Node.js ODBC连接PostgreSQL
- 网站压测工具Apache-ab,webbench,Apache-Jemeter
- Common interview questions of operating system:
- MySQL installation process (steps for successful installation)
- Detailed explanation of MySQL connection query
- Summary of interfaces for JDBC and servlet to write CRUD
猜你喜欢

大厂技术实现 | 行业解决方案系列教程

山寨版归并【上】
How to design a good API interface?
What if the server is poisoned? How does the server prevent virus intrusion?
Sword finger offer (1) -- for Huawei

移动金融(自用)
Explanation 2 of redis database (redis high availability, persistence and performance management)

regular expression
电脑怎么重装系统后显示器没有信号了
机器学习——逻辑回归
随机推荐
For examination
【backtrader源码解析18】yahoo.py 代码注释及解析(枯燥,对代码感兴趣,可以参考)
编译,连接 -- 笔记
Elk installation
ICE -- 源码分析
PHP 的运算符
Collation of errors encountered in the use of redis shake
Educational codeforces round 127 A-E problem solution
The wechat applet optimizes the native request through the promise of ES6
Go并发和通道
函数(第一部分)
服务器中毒了怎么办?服务器怎么防止病毒入侵?
T2 iCloud日历无法同步
Detailed explanation of redirection and request forwarding
Explanation 2 of redis database (redis high availability, persistence and performance management)
重定向和请求转发详解
CVPR 2022 优质论文分享
kubernetes之常用Pod控制器的使用
怎么看基金是不是reits,通过银行购买基金安全吗
激活函数的优缺点和选择