当前位置:网站首页>Sorting and replying to questions related to transformer
Sorting and replying to questions related to transformer
2022-04-23 15:27:00 【moletop】
transformer
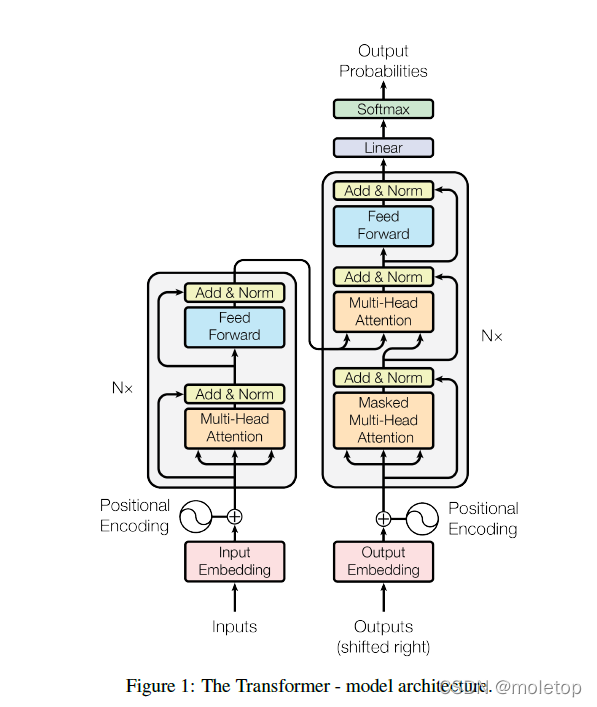
motivation :
RNN characteristic : Give you a sequence , The calculation is step by step from left to right . For sentences , It's a word by word , Right. t One word counts one ht, Also known as his hidden state , It's from the previous word ht-1 and Current t The word itself determines . In this way, the historical information learned before can be passed through ht-1 In the present , Then do some calculations with the current word and get the output .
problem : Because it's timing transmission , Lead to 1. Difficult to parallel 2. The early learned information will be lost , If you don't want to lose , That may require a big ht, But if you make one more big ht, Every time should be saved , The overhead of memory is relatively large .
——> Pure use attention Mechanism can greatly improve the parallelism
- Consider using CNN Replace the recurrent neural network :CNN It is difficult to model long sequences , Every convolution calculation is to look at a small window , Take pixels as an example , If two pixels are far apart , Then you need many layers of convolution , To fuse these two distant pixels . And for transformer Come on , I can see all the pixels at once , Relatively speaking, there is no such problem . But convolution has the advantage of being able to do multiple output channels . Each channel can think that it can recognize different patterns . therefore muti-headed attention To be mentioned , It is used to simulate the effect of multiple output channels of convolutional neural network , It can also be said to be a multi-scale concept , Let the model learn from multiple different scale spaces .
structure
encoder:
The left part ,N be equal to 6 Exactly the same layer Every layer There are two of them sub-layers. first sub-layer Namely multihead self attention, The second one is actually MLP. Then each sublayer is connected with a residual , Finally, I used one LayerNorm. So the output of each sublayer is LayerNorm(x + Sublayer (x)).
details : Because the input and output of the residual should be the same size , So for the sake of simplicity , The dimension of each output is not set 512, That is, every word , No matter what floor , It's all done 512 The length of a is . This and CNN perhaps MLP It's different , These two are either the dimension reduction or the dimension reduction of space , The dimension of the channel is pulled up . So this also makes the model relatively simpler , If you want to adjust parameters, just adjust this 512 And the one in front N = 6 Just fine .
Location code : There is no RNN Of transformer There seems to be no function to capture sequence information , It can't tell whether I bit the dog or the dog bit me . What shall I do? , The position information of the word can be combined when inputting the word vector , In this way, you can learn word order information
One way is to allocate one 0 To 1 The values between give each time step , among ,0 Indicates the first word ,1 Indicates the last word . Although this method is simple , But it will bring many problems . One of them is that you can't know how many words exist in a specific range . let me put it another way , The time step difference between different sentences has no meaning .
Another way is to linearly assign a value to each time step . That is to say ,1 Assign to the first word ,2 Assign to the second word , And so on . The problem with this approach is that , Not only will these values become very large , And the model will also encounter some sentences longer than all the sentences in the training . Besides , The data set does not necessarily contain sentences of corresponding length on all values , That is, the model probably hasn't seen any sample sentences of such length , This will seriously affect the generalization ability of the model .
In fact, the cycle is different sin and cos Calculated
decoder:
There is a third sublayer more than the encoder ( It's also a long attention mechanism , Residual error is also used , Also used layernorm) It's called masked muti-headed attention( Provide... For the next floor Q). The decoder uses an autoregressive , Some input of the current layer is the input of some time above , This means that when you make predictions , Of course, you can't see the output of those moments after . But do attention When , You can see the complete input , To avoid this happening , use mask The attention mechanism of . This ensures that the behavior is consistent when training and predicting .
Two kinds of mask:
1.padding mask: The length of the sequence we enter is not necessarily the same . For sequences longer than we expect , We just keep the content within the expected length . For a sequence whose length does not reach the desired length , We will use 0 To fill it , The position of filling is meaningless , We don't want attention The mechanism allocates any attention to it , So we add negative infinity to the filled position , Because we use it when calculating attention softmax function , Plus the position that is too negative infinity will be softmax Processing becomes 0).
2. For prediction mask: You can't see the following output .
LayerNorm
First look at batch Normlization

Be careful : Finally, add the scaling factor and translation factor ( Parameters are learned by yourself ). This is a In order to ensure that the expression ability of the model does not decline due to normalization . Because the upper neurons may be studying very hard , But no matter how it changes , The output results are processed before they are handed over to the lower neurons , Will be roughly readjusted to this fixed range . But not every sample is suitable for normalization , After some special samples are normalized . Lost his learning value . On the other hand, it is important to ensure the nonlinear expression ability . Normalization maps almost all data to the unsaturated region of the activation function ( Linear area ), Only the ability to change linearly . Only the ability to change linearly , Thus, the expression ability of neural network is reduced . And then change it , Then the data can be transformed from linear region to nonlinear region , Restore the expressiveness of the model .
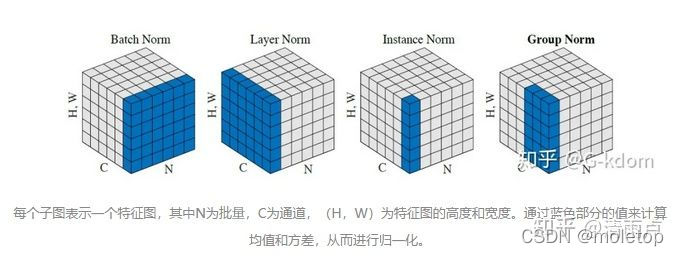
Why layerNorm better :
Normlization Purpose : An albino , Make it independent and identically distributed
batch Normlization It is the same channel of different samples for normalization ,layer Normlization Different channels of the same sample are normalized . For a characteristic graph , The two just cut in different directions , A horizontal , A vertical .RNN Text network is not suitable for BN Why :Normalize The object of (position) From different distributions .CNN Use in BN, To a batch Every one of them channel Do standardization . The same of multiple training images channel, The probability comes from a similar distribution .( For example, the graph of a tree , Initial 3 individual channel yes 3 A color channel , Will have similar tree shape and color depth ).RNN Use in BN, To a batch Every one of them position Do standardization . Multiple sequence The same position, It's hard to say from a similar distribution .( For example, film reviews , However, various sentence patterns can be used , It is difficult for words in the same position to obey similar distribution ) therefore RNN in BN It's hard to learn the right μ and σ. But if you're in a single sample of yourself normlization Words , There is no such thing .
Other Normlization:Weight Normalization( Parameter normalization ) Cosine Normalization ( Cosine normalization )
Reference resources :https://zhuanlan.zhihu.com/p/33173246
Complexity :
Here is the sticky chart , Reference link :https://zhuanlan.zhihu.com/p/264749298

版权声明
本文为[moletop]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231523160832.html
边栏推荐
- 软件性能测试报告起着什么作用?第三方测试报告如何收费?
- MultiTimer v2 重构版本 | 一款可无限扩展的软件定时器
- T2 iCloud日历无法同步
- Use of common pod controller of kubernetes
- Detailed explanation of kubernetes (XI) -- label and label selector
- Elk installation
- Openstack theoretical knowledge
- Will golang share data with fragment append
- JUC学习记录(2022.4.22)
- Sword finger offer (1) -- for Huawei
猜你喜欢
Lotus DB design and Implementation - 1 Basic Concepts
Openstack command operation

Functions (Part I)
T2 icloud calendar cannot be synchronized
The wechat applet optimizes the native request through the promise of ES6
电脑怎么重装系统后显示器没有信号了

Openfaas practice 4: template operation
setcontext getcontext makecontext swapcontext
Detailed explanation of MySQL connection query

深度学习——超参数设置
随机推荐
T2 iCloud日历无法同步
Detailed explanation of redirection and request forwarding
JUC learning record (2022.4.22)
移动app测试如何进行?
Kubernetes详解(九)——资源配置清单创建Pod实战
The wechat applet optimizes the native request through the promise of ES6
Example of time complexity calculation
X509 certificate cer format to PEM format
Lotus DB design and Implementation - 1 Basic Concepts
移动app软件测试工具有哪些?第三方软件测评小编分享
什么是CNAS认证?CNAS认可的软件测评中心有哪些?
TLS / SSL protocol details (28) differences between TLS 1.0, TLS 1.1 and TLS 1.2
TLS / SSL protocol details (30) RSA, DHE, ecdhe and ecdh processes and differences in SSL
Openstack theoretical knowledge
On the day of entry, I cried (mushroom street was laid off and fought for seven months to win the offer)
YML references other variables
Differential privacy (background)
Basic operation of circular queue (Experiment)
控制结构(一)
控制结构(二)