当前位置:网站首页>SQL optimization for advanced learning of MySQL [insert, primary key, sort, group, page, count]
SQL optimization for advanced learning of MySQL [insert, primary key, sort, group, page, count]
2022-04-23 17:38:00 【Everything will always return to plain】
Catalog
1、 insert data
If we need to insert multiple records into the database table at one time , It can be optimized from the following three aspects .
1、 Bulk insert data
Insert into student values (5, ' Xiao Ming ',20011019), (6, ' Xiaohong ',19991019), (7, ' Little green ',20001019);2、 Manually control transactions
start transaction; Insert into student values (5, ' Xiao Ming ', 20011019), (6, ' Xiaohong ', 19991019), (7, ' Little green ', 20001019); Insert into student values (8, ' Xiao Ming ', 20011019), (9, ' Xiaohong ', 19991019), (10, ' Little green ', 20001019); Insert into student values (11, ' Xiao Ming ', 20011019), (12, ' Xiaohong ', 19991019), (13, ' Little green ', 20001019); commit;3、 Insert primary key in order , Performance is better than out of order insertion .
The primary key is inserted out of order : 8 1 9 21 88 2 4 15 89 5 7 3 Insert primary key in order : 1 2 3 4 5 7 8 9 15 21 88 89
Mass insert data
If you need to insert a large amount of data at one time ( such as : Millions of records ), Use insert Statement insertion performance is low , You can use MySQL Database provides load Insert instructions . The operation is as follows :
1 、 Create a table structure
CREATE TABLE `tb_user` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `username` VARCHAR(50) NOT NULL, `password` VARCHAR(50) NOT NULL, `name` VARCHAR(20) NOT NULL, `birthday` DATE DEFAULT NULL, `sex` CHAR(1) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) ) ENGINE = INNODB DEFAULT CHARSET = utf8;2、 Set parameters
-- When the client connects to the server , Add parameters -–local-infile mysql –-local-infile -u root -p -- Set global parameters local_infile by 1, Turn on the switch to import data from the local load file set global local_infile = 1;
3、load Load data , Remember to switch to the relevant database first
load data local infile 'C:/Users/jie/Desktop/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n';
My little broken computer runs well , I don't know how your computer runs .
notes : stay load when , The performance of primary key sequential insertion is better than that of out of order insertion


2、 Primary key optimization
2.1 How data is organized
stay InnoDB In the storage engine , Table data is organized and stored according to the primary key sequence , The tables in this way of storage are called index organization tables (index organized table IOT).
stay InnoDB In the engine , Data lines are recorded in logical structures page On page , And the size of each page is fixed , Default 16K.
That means , The rows stored in a page are also limited , If the inserted data row row Store not small on this page , Will be stored in the next page , Pages are connected by pointers .
2.2 Page splitting
The page can be empty , You can fill half , You can also fill in 100%. Each page contains 2-N Row data ( If a row of data is too large , Line overflow ), Arrange according to the primary key .
1、 Primary key sequence insertion effect
Request page from disk , Insert primary key in order , When the first page is full , Write the second page , Pages are connected by pointers , When the second page is full , Then write to the third page , And so on .
2、 The primary key is inserted out of order
The first and second pages are full of data .
Insert again at this time id by 50 The record of , Because the leaf nodes of the index are in order . In order , It should be stored and then 47 after , So it will not be written to the new page .

however !47 The first page is full , Then a new page will be opened at this time , To store 50, But it will not directly 50 Deposit on page 3 , Instead, the data in the second half of the first page , Move to 3 page , Then insert... On the third page 50.

mobile data , And insert id by 50 After the data of , So at this time , The data order between these three pages is problematic . The next page of the first page , It should be page three , The next page of the data on the third page is the second page . therefore , here , Need to reset the linked list pointer .

The above phenomenon , be called " Page splitting ", It is a performance consuming operation .
2.3 Page merge
Now there are three pages of data .
Let's now delete the second page 4 Data .
notes : When deleting a row of records , In fact, the record has not been physically deleted , Just the record is marked (flaged) For deletion and its space becomes allowed to be used by other record declarations .

Like this, when the total deleted records of the page reach MERGE_THRESHOLD( The default is... Of the page 50%),InnoDB Will start looking for the closest page ( Before or after ) See if you can merge two pages to optimize space usage .
This is the time to physically delete data , Then merge the pages , If you insert new data at this time . Then write directly to the third page .
The phenomenon of merging pages that occurs in this , It's called " Page merge ".
notes :
MERGE_THRESHOLD: The threshold for merging pages , You can set it yourself , Specify... When creating a table or index .
2.4 Key design principles
-
Meet business needs , Try to reduce the length of the primary key .
-
When inserting data , Try to insert in order , Choose to use AUTO_INCREMENT Since the primary key .
-
Try not to use UUID Make primary keys or other natural primary keys , Such as ID card No .
-
During business operation , Avoid modifying the primary key .
3、order by Optimize
MySQL Sort , There are two ways :
Using filesort : Through table index or full table scan , Read the data lines that meet the conditions , Then in the sort buffer sortbuffer Complete the sorting operation in , All sorts that do not return sorting results directly through index are called FileSort Sort .
Using index : Through the sequential scan of the ordered index, the ordered data can be returned directly , This is the case using index, No need for extra sorting , High operating efficiency .
For the above two sorting methods ,Using index High performance , and Using filesort Low performance , When we optimize sorting operations , Try to optimize for Using index.
test :
I now use the above to import millions of data tb_user Do a test .
Let's do the following SQL:
explain select id,birthday ,sex from tb_user order by sex,birthday ;
because sex, birthday There's no index , So when sorting again at this time , appear Using filesort, Low sorting performance . Then let's create a joint index for them .
create index idx_user_sex_birthday_aa on tb_user(sex,birthday); After creating the index , Let's do it again explain sentence .
After indexing , Sort again , From the original Using filesort, Change into Using index, The performance is relatively high .
Now let's try to sort in descending order .
explain select id,birthday ,sex from tb_user order by sex desc ,birthday desc ;
Also appear Using index, But at this time Extra In the Backward index scan, This represents the reverse scan index , Because in MySQL The index we created in , The leaf nodes of the default index are sorted from small to large , At this time, when we query and sort , It's from big to small , therefore , At the time of scanning , It's reverse scanning , Will appear Backward index scan.
stay MySQL8 In the version , Support descending index , We can also create a descending index .
create index idx_user_sex_birthday_ab on tb_user(sex desc ,birthday desc );After creation , Let's sort the query in descending order again .

This will be Using index.
In another case, the query is based on sex, birthday In descending order, in ascending order , A descending order
explain select id,birthday ,sex from tb_user order by sex asc ,birthday desc ;
Because when you create an index , If the order is not specified , By default, they are sorted in ascending order , And when you query , An ascending order , A descending order , And then there will be Using filesort.
At this time, we can create another index according to the sorting .
create index idx_user_sex_birthday_ac on tb_user(sex asc ,birthday desc ); And then execute SQL Statement query .
This is just another Using index.
By the above test , We come to the conclusion that order by Optimization principle :
Establish the appropriate index according to the sorting field , When sorting multiple fields , Also follow the leftmost prefix rule .
Try to use overlay index .
Multi field sorting , One ascending, one descending , At this time, you need to pay attention to the rules when creating the federated index (ASC/DESC).
If inevitable filesort, When sorting large amounts of data , You can appropriately increase the size of the sorting buffer sort_buffer_size( Default 256k).
4、group by Optimize
First of all, I'll put tb_user Delete all table indexes first .
drop index idx_user_sex_birthday_aa on tb_user;
drop index idx_user_sex_birthday_ab on tb_user;
drop index idx_user_sex_birthday_ac on tb_user;Next , Without index , The implementation is as follows SQL, Query execution plan :
explain select sex , count(*) from tb_user group by sex ;
then , We are aiming at sex, name, birthday Create a federated index .
create index idx_user_sex_name_birthday on tb_user(sex , name , birthday);Then , Perform the same... As before SQL View execution plan .

Then execute the following grouping query SQL, View execution plan
explain select sex , count(*) from tb_user group by name,birthday ;
explain select sex , count(*) from tb_user group by name ;
We found that , If only based on name grouping , Will appear Using temporary ; And if it's based on sex,name Two fields are grouped at the same time , Will not appear Using temporary. The reason is that for grouping operations , In the union index , It also conforms to the leftmost prefix rule .
therefore , In grouping operations , We need to optimize through the following two points , To improve performance :
During grouping operation , Efficiency can be improved by indexing .
When grouping , The use of index also satisfies the leftmost prefix rule .
5、limit Optimize
When the amount of data is large , If carried out limit Paging query , In the query , The later , The lower the efficiency of paging query . Let's take a look at the implementation limit Comparison of paging query time :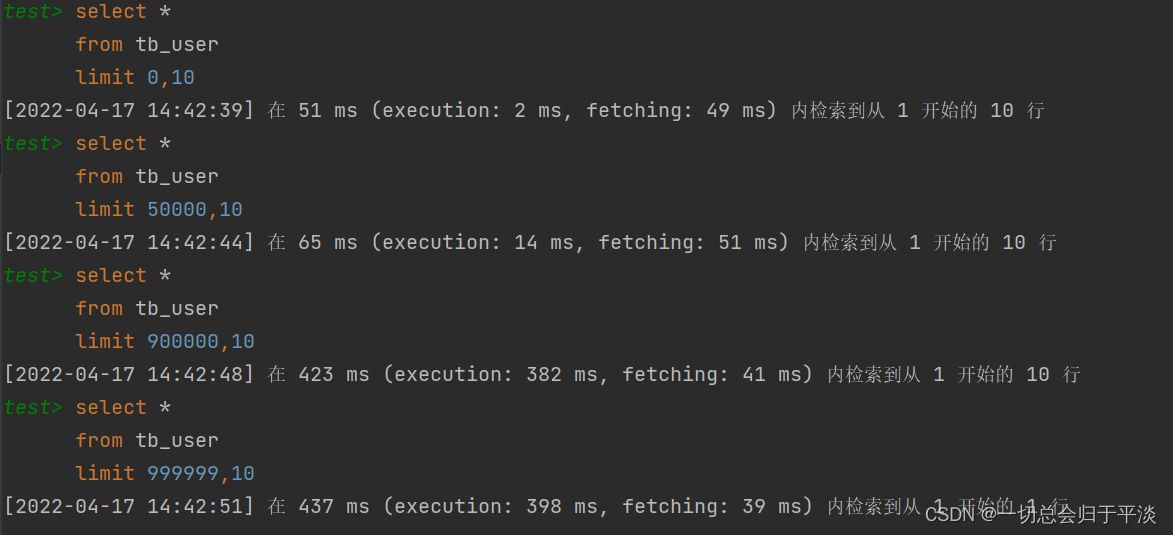
Through the test, we will see , The later , The lower the efficiency of paging query , That's the problem with paging queries .
Optimization idea : General paging query , adopt establish Overlay index It can better improve the performance , It can also be done through Overlay index plus subquery Form optimization .
explain select * from tb_user t , (select id from tb_user order by id limit 999999,10) a where t.id = a.id;6、count Optimize
MyISAM The engine stores the total number of a table on disk , So execute count(*) It will return this number directly , It's very efficient ; But if it's conditional count,MyISAM It's also slow .
InnoDB The engine is in trouble , It performs count(*) When , You need to read the data line by line from the engine , And then the cumulative count .
If you want to improve significantly InnoDB Tabular count efficiency , The main optimization ideas :
Count yourself , With the aid of redis In this way, the non relational database , But if it's conditional count It's more troublesome again .
count() It's an aggregate function , For the returned result set , Judge line by line , If count The argument to the function is not null, Add... To the cumulative value 1, Otherwise, we will not add , Finally return the cumulative value .
| count usage | meaning |
|---|---|
| count( Lord key ) | InnoDB The engine will traverse the entire table , Put each line of Primary key id Take out all the values , Return to the service layer . After the service layer gets the primary key , Accumulate directly by line ( The primary key cannot be null) |
| count( word paragraph ) | No, not null constraint : InnoDB The engine will traverse the whole table and get the field values of each row , Return to the service layer , The service layer determines whether it is null, Not for null, Count up . Yes not null constraint :InnoDB The engine will traverse the whole table and get the field values of each row , Return to the service layer , Accumulate directly by line . |
| count( Count word ) | InnoDB The engine traverses the entire table , But no value . For each row returned by the service layer , Put a number “1” go in , Accumulate directly by line . |
| count(*) | InnoDB The engine doesn't take out all the fields , It's optimized , No value , The service layer accumulates directly by line . |
In order of efficiency ,count( Field ) < count( Primary key id) < count(1) ≈ count(*), So try to
Amount of use count(*).
版权声明
本文为[Everything will always return to plain]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231736239209.html
边栏推荐
- Open futures, open an account, cloud security or trust the software of futures companies?
- 48. 旋转图像
- Signalr can actively send data from the server to the client
- 2. Electron's HelloWorld
- How does matlab draw the curve of known formula and how does excel draw the function curve image?
- Self use learning notes - connected and non connected access to database
- ASP. Net core configuration options (Part 2)
- ASP. Net core configuration options (Part 1)
- ClickHouse-数据类型
- Node template engine (EJS, art template)
猜你喜欢
.Net Core3. 1 use razorengine NETCORE production entity generator (MVC web version)
92. 反转链表 II-字节跳动高频题
01 - get to know the advantages of sketch sketch

C语言函数详解
JVM类加载机制
![[ES6] promise related (event loop, macro / micro task, promise, await / await)](/img/69/ea3ef6063d373f116a44c53565daa3.png)
[ES6] promise related (event loop, macro / micro task, promise, await / await)
Advantages and disadvantages of several note taking software

Net standard
48. 旋转图像
Compare the performance of query based on the number of paging data that meet the query conditions

随机推荐
Deep understanding of control inversion and dependency injection
Use of Shell sort command
剑指 Offer 03. 数组中重复的数字
The system cannot be started after AHCI is enabled
PC uses wireless network card to connect to mobile phone hotspot. Why can't you surf the Internet
470. Rand10() is implemented with rand7()
C# Task. Delay and thread The difference between sleep
Detailed explanation of C webpai route
Ouvrir des contrats à terme, ouvrir des comptes en nuage ou faire confiance aux logiciels des sociétés à terme?
MySQL进阶学习之SQL优化【插入,主键,排序,分组,分页,计数】
48. 旋转图像
Use of shell awk command
C语言函数详解
402. Remove K digits - greedy
Shell - introduction, variables, and basic syntax
Conversion between hexadecimal numbers
386. Dictionary order (medium) - iteration - full arrangement
Using quartz under. Net core -- operation transfer parameters of [3] operation and trigger
Metaprogramming, proxy and reflection
239. Maximum value of sliding window (difficult) - one-way queue, large top heap - byte skipping high frequency problem