当前位置:网站首页>Detailed explanation of MySQL connection query
Detailed explanation of MySQL connection query
2022-04-23 15:14:00 【Fighter_ two thousand and thirteen】
Preface
I remember when I first worked for a few years , Just wrote an article about Mysql Blog posts connected to query , It simply thinks that the records of the association table should be Cartesian product first , And then based on where filter , Now it seems a little ridiculous . Just recently saw 《mysql How it works 》 This book , So for Mysql The principle and process of connection query are summarized again .
One 、 What is a join query
Join query refers to multi table Association query .
Sample tables and data preparation :
CREATE TABLE `t1` (
`m1` int,
`n1` char(1)
) ;
CREATE TABLE `t2` (
`m2` int,
`n2` char(1)
) ;
INSERT INTO t1 VALUES(1,'a'),(2,'b'),(1,'c');
INSERT INTO t2 VALUES(2,'b'),(3,'c'),(4,'d');
Typical writing :
SELECT * FROM t1 [INNER | LEFT | RIGHT] JOIN t2
ON t1.m1 = t2.m2
WHERE t1.n1 = 'c';
among ,ON Indicates the association condition of two tables ,WHERE Is the filter condition of query results .
If you don't add any association conditions and WHERE Conditions , The result is two tables The cartesian product . such as :
SELECT * from t1, t2
Be careful ️:
The result set of the query here is exactly the same as the result of Cartesian product of two table records , and The query process does not operate on Cartesian product of two table records .
Two 、 Classification of join queries
1、inner join: Internal connection
The last number of data rows returned is in inner join The number of data rows in the two tables at the same time . Any piece of data that only exists in a certain table , Will not return ,
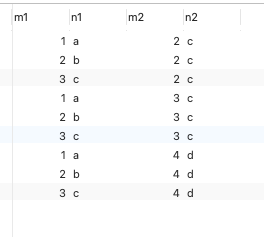
SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2;
-- Equivalent to
SELECT * FROM t1 , t2 WHERE t1.m1 = t2.m2;
Query results :
2、 External connection query
External connection query is divided into Left outer connection query and Right outer connection query .
left join: Left connection , Also known as left outer join, We usually put outer Omit . Shorthand for left join
left The table on the left is the main table ,left The table on the right is the slave table . Return the number of result rows left The number of rows in the left table is the last data row , For some data rows in the left table, when the matching data row record cannot be found in the right table , When returning results, these lines are usually followed by null Fill in .
-- Left outer connection query , With JOIN Table on the left t1 To drive the table
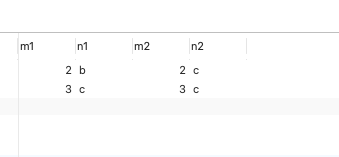
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2;
Query results :
right join: The right connection , Also known as right outer join, We usually put outer Omit . Shorthand for right join
right The table on the right is the main table ,right The table of coordinates is the slave table . Return the number of result rows right The number of rows in the table on the right is the data row on the left , For some data rows in the main table, when the matching data row record cannot be found from the table , When returning results, these lines are usually followed by null Fill in .
-- Right outer connection query , With JOIN The table on the right t2 To drive the table
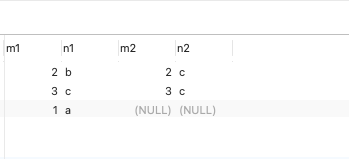
SELECT * FROM t1 RIGHT JOIN t2 ON t1.m1 = t2.m2;
Query results :

3、 ... and 、 Drive table and driven table
1、 What is a driving watch , What is driven watch ?
The drive table is in SQL Statement execution , Always read first . And the driven table is in SQL Statement execution , Always read after .
After the drive table data is read , Put in join_buffer after , Then read the data in the driven table , To match the data in the drive table . If it matches, it will be returned as a result set , Or throw it away .
2、 How to distinguish between driven tables and driven tables ?
We are interested in an existing SQL sentence , How should we judge this SQL Which statement represents the driving table ? Which represents the driven table ?
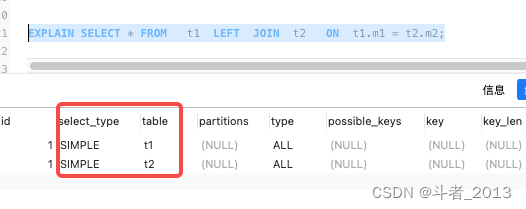
have access to explain Command to check SQL Statement execution plan . In the output execution plan , The table in the first row is the drive table , The table in the second row is the driven table .
In the following example , Left outer connection , The left table t1 It's the drive meter .
3、mysql How to select the driver table ?
left joinLeft outer connection query , The left table is the driver table ;right joinRight outer connection query , The right table is the drive table ;inner joinInternal connection query , The small table is the driving table ;
What is the so-called small watch ?
Tables with fewer records , Or there are fewer tables after single table filtering conditions , Or return a table with fewer fields ?
Here is the judgment of size , Refer to The amount of data actually involved in the associated query join_buffer To distinguish the size of , Instead of judging by the number of all data rows in the table .
therefore , We should not blindly believe that a table with a small number of data rows in the table participating in the associated query must be a driving table 、 A table with a large number of data rows must be a driven table .
Only in the inner join query, you need to determine the driving table according to the large table and small table , And this process is actually caused by Mysql The query optimizer determines , There is no need for the user to intervene or specify . We just need to know roughly what the driver table is based on .
Please refer to this article for details :MySQL Drive table and driven table in
Four 、 Connection process analysis
Use the following query as an example to analyze :
SELECT * from t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
In this query contain 3 Filter conditions :
- t1.m1> 1;
- t1.ml = t2.m2;
- t2.n2 < ‘d’;
Classification of query criteria :
1、 Single table filter conditions , among t1.m1> 1、t2.n2 < 'd’ Single table filter conditions
2、 Associated filter conditions ,t1.ml = t2.m2 This is the association filter condition
The execution process of this connection query is roughly as follows .
step 1、 Select the driver table , Select the scheme with the least cost according to all single table filtering conditions involved in the driving table to execute single table query .
Single table query : Select the least expensive access method to execute single table query statements .
( That is to say, from const、 ref、 ref_or_null、 range、 index_merge、index、all Among these execution methods, select the one with the least cost to execute the query ).
t1 Query process of :
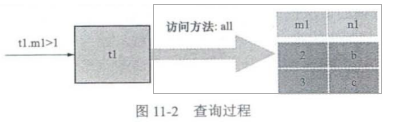
from t1 Found in t1.m1> 1 There are two records of , The sub table is m1=2,m1=3;
step 2、 step 1 Every record obtained from the driver table in , We all need to get to t2 Query matching records in the table .
The so-called matching record , It refers to the records that meet the filtering conditions .
Because it's based on t1 Look for the records in the table t2 The records in the table , therefore t2 A watch can also be called Was the driver table .
take t1 The query records in the table are based on the association conditions t1.ml = t2.m2 Turn to specific query criteria , combining t2 All single table query criteria are from t2 Query matching records in the table .
From t1 The first record obtained from the query in the table , That is to say t1.m1=2 when , Filter conditions t1.m1 = t2m2 Equivalent to
t2.m2=2, So at this time t2 A watch is equivalent to having t2.m2=2、t2.n2<‘d’ These two filter conditions , And then to t2 Execute single table query in table ;
From t1 The second record obtained from the query in the table , That is to say t1.m1=3 when , Filter conditions t1. m1=t2.m2 Time is like
When t2. So at this time A watch is equivalent to having t2.m2=3 、t2.n2<‘d’ These two filter conditions , And then to Introduction to Zhong Lianzhong 181 11.1
Execute single table query .
The execution process of the whole connection query is as follows :
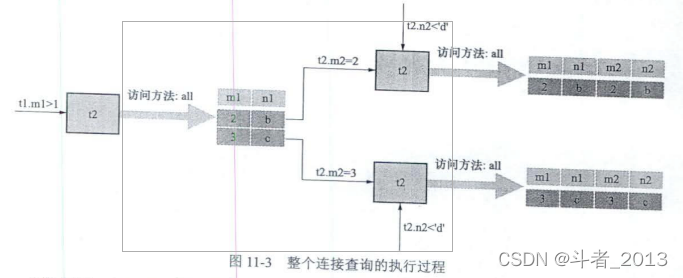
Be careful ️:
It needs to be emphasized here , Not all the driver table records that meet the conditions are queried and put in one place , Then go to the query in the driven table .
Let's think about it , If there are many records in the driving table that meet the conditions , That will require a lot of storage space , This is clearly unreasonable .
mysql In connection queries , It's using Every time a drive table record is obtained, immediately look for a matching record in the driven table .
Summary :
Process of connection query :
step 1、 Select the driver table , Use the filter conditions associated with the driver table , Select the lowest cost single table access method to execute the single table query of the driving table .
step 2、 For steps 1 Each record in the result set obtained from the query driven table in , Find the matching records in the driven table .
The same two table Association query is shown in the figure :
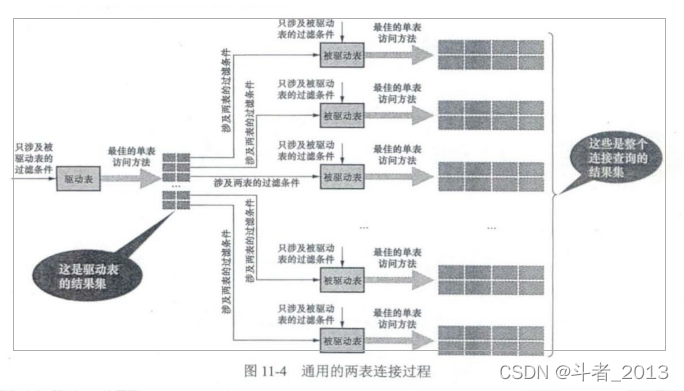
If there is 3 Connect tables , So the steps 2 The result set obtained in is like a new driver table , Then the first 3 Just a watch
Become a driven table , Then repeat the above process .
5、 ... and 、ON and WHERE The difference between
-
Where Filter conditions in clause
WHERE The filter conditions in the clause, whether internal or external , Anything that doesn't match WHERE None of the records in the filter clause will be added to the last result set .
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2 where t2.n2 < 'd' ;
Query results :
because t2.n2 < 'd’ The query criteria are where clause , The query result must meet

- ON Filter conditions in clause
For records in the externally connected drive table , If a match cannot be found in the driven table ON The record of the filter condition in the clause .
Then the drive table record will still be added to the result set , Each field of the corresponding driven table record uses NULL Value padding .
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2 AND t2.n2 < 'd' ;
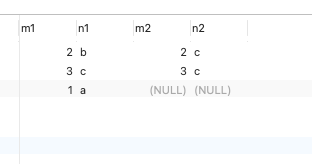
ON Single table filter condition in clause :
The single table filter conditions for the drive table are placed in ON Clause is invalid , Only on the WHERE clause .
Single table filter conditions for driven tables , Put it in ON clause , Even if the driven table has no records, it returns , Will also use NULL Fill the fields with values .
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2 AND t1.n1 < 'b' ;
According to the query results, we found that ,ON Clause for the driving table t1 The single table filter condition of is invalid .
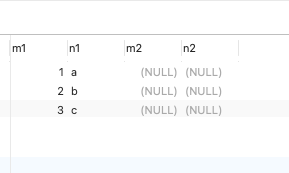
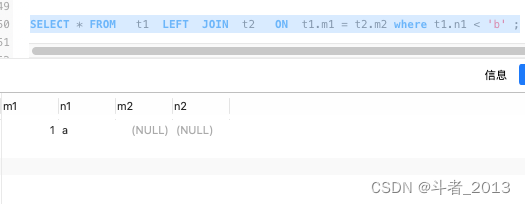
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2 where t1.n1 < 'b' ;
Single table query criteria for driving tables , Need to put in where Conditions are valid .
It should be noted that , This ON Clause is specifically for " The records in the external connection drive table when the driven table cannot find a matching record Whether the driver table record should be added to the result set " This scenario proposes Of . therefore , If you put ON Clause into inner join ,
MySQL Will make it look like WHERE Treat , in other words In the inner connection WHERE Clause and ON Clause is equivalent .
Be careful ️:
ON Clause except for the associated fields of the two tables , You can also add query criteria .
For driving tables ,ON In addition to the association relationship , Other single table query criteria for driving tables are invalid ( be based on Mysql8.0 verification ).
For driven tables ,ON The condition in can return without matching , Each field of the corresponding driven table record uses NULL Value padding .
Recommended use :
1、ON Clause, try to configure only association conditions ;
2、 The single table query criteria of the driving table are only in WHERE Clause .
3、 Single table query criteria of driven table , If you want to return without matching NULL value , Then add to ON clause ; Otherwise, it is uniformly configured in WHERE clause .
6、 ... and 、 Conversion of inner connection and outer connection
Because everything does not meet WHERE None of the conditional records in the clause will participate in the connection . So as long as where Clause in the search criteria “ The column of the driven table is not NULL” Search criteria for , Then, the external connection cannot find a match in the driven table ON The driving table records of clause conditions are excluded from the final result set .
-- Short for inner connection , Is full of where Conditions
SELECT * from t1,t2 WHERE t1.m1 = t2.m2
-- Standard writing of inner connection ,on Indicates the association condition ,where Indicates the query criteria
SELECT * from t1 INNER JOIN t2 ON t1.m1 = t2.m2
-- External connection query by limiting that the connection condition is not empty , Realize the equivalent writing of inner connection
SELECT * from t1 LEFT JOIN t2 ON t1.m1 = t2.m2 WHERE t2.m2 IS NOT NULL;
Be careful ️:
If ON The connection condition is in the drive table t1.m1 It can be for null, Then the writing method is not tenable .
You can also not display a column of the specified driven table IS NOT NULL search criteria , Just implicitly include this restriction .
Like the following 2 individual sql It is equivalent. . Because in WHERE Clause specifies the driven table t2 Of m2 = 2, The result is limited t2.m2 Not empty , So it is equivalent to inner join query .
SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2 WHERE t2.m2 = 2;
-- Equivalent to
SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2 WHERE t2.m2 = 2;
Conversion rules :
Only need external connection query where The condition specifies a non in the driven table null The column of is not null , It is equivalent to inner join query . It doesn't have to be ON The associated field in the condition is not null.
This is used in external connection query , designated where The columns in the driven table contained in the clause are not null The condition of value is called Null reject (reject-NULL).
In the driven table WHERE Clause meets the null rejection condition , External connection and internal connection can be converted to each other .
The benefit of this transformation is that the optimizer can evaluate the cost of different join sequences of tables , Select the lowest cost join order to execute the query .
7、 ... and 、 Block based nested loop connections
The kind of... Described above “ The drive table only accesses 1 Time , However, the driven table may be accessed multiple times , The number of accesses depends on the number of records in the result set after performing a single table query on the drive table " The connection execution mode of is called Nested loop connection Nest Loop , This is the simplest and most clumsy join query algorithm .
Nested loop connection Nest Loop It can be divided into three categories :
- Index Nested-Loop Join: Index nested loop join
- Simple Nested-Loop Join: Simple nested loop join
- Block Nexted-Loop Join: Block based nested loop connections
Index Nested-Loop Join: Index nested loop join
explain : When fetching from the driven table , The index of the driven table is used , Instead of scanning all the data in the driven table .
Use the following SQL To explain Index Nested-Loop Join The execution process of this associated query
explain select * from A as a inner join B as b on a.id = b.id

Based on the above query plan , We can see that B A table is a driver table ,A A table is a driven table . Next, let's explain in detail the specific execution process of this associated link .
1、 obtain B The first row of data in the table , Then get the... Of that line from this line id Value .
2、 Hold id The value of A Search the table to meet the id Row of values , Now we use A The primary key index in the table . When you find it, put A This row in the table and B The rows in the table are spliced together , As the final result set , Return to the client .
That's it B The first row of data in the table and A Tabular inner join The process .
3、 repeat 1、2、3 step , Straight handle B All rows of the table are traversed , Just finished this join The process .
So here are the steps Index Nested-Loop Join The process of execution .
Be careful :
Go to the driven table A When getting data from , Using the A The index in the table , It's not about A Scan all the data in the table , Go back and B To match the data in the table .
Simple Nested-Loop Join: Simple nested loop join
explain : When querying in the driven table , Index not used , Instead, use full table query .
select * from A as a inner join B as b on a.code = b.code;
hypothesis A A table is a small table, that is, a driving table ,B A table is a large table, that is, a driven table
I'm going to A When the table is driven to find data in the table , Can't pass A The index in the table to get the data . So you need to A All the data in the table are scanned , And then with B In the table code Value to match . So every time you deal with B A line in the table ,A All the data in the table should be scanned once . This is more efficient than what we mentioned earlier Index Nested-Loop Join A lot slower .
however ,MySQL In this case, this slow way is not adopted , Instead, it adopts what we will say below Block Nexted-Loop Join The way in which they relate . That's why we didn't see... In the query plan above Simple Nested-Loop Join Why .
Block Nexted-Loop Join: Block based nested loop connections
explain : Via connection buffer (Join Buffer) Cache drive table data , Batch and driven tables are matched .
In the process of two table connection using nested loop connection algorithm , The driven table needs to be accessed multiple times .
If there is too much data in the driven table and the index cannot be used for access , That's equivalent to reading this from disk
A watch many times , This I/O The price is very high . Therefore, we need to find ways to minimize the number of accesses to the driven table .
As I said before , How many records are there in the drive table result set , How many times it is possible to load the driven table from disk into memory .
Whether we can load the records in the driven table into memory , Match multiple records in the drive table at one time ?
This greatly reduces the cost of loading the driven table from disk repeatedly .
therefore Mysql Designed Join Buffer ( Connection buffer ) The concept of .
Let's take this query as an example :
SELECT * from t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
There is no Join Buffer ( Connection buffer ) front , Query driven table :
-- The first 1 Second scan drive table
SELECT * from t2 WHERE t2.n2 < 'd' AND t2.m2 = 2;
-- The first 2 Second scan drive table
SELECT * from t2 WHERE t2.n2 < 'd' AND t2.m2 = 3;
use Join Buffer ( Connection buffer ) after , Query driven table :
SELECT * from t2 WHERE t2.n2 < 'd' AND t2.m2 in (2,3);
add to Join Buffer ( Connection buffer ) after , Not every time you get a record of the driven table, you immediately query the matching records in the driven table . Instead, the query results of the driving table are loaded into Join Buffer ( Connection buffer ) after , Then go to the driven table to query .
Join Buffer It is a fixed size of memory requested before executing the connection query . First, put several records in the result set of the drive table in this Join Buffer in , Then start scanning the driven table , The record of each driven table is associated with Join Buffer Match multiple drive table records in , Because the matching process is completed in memory , Therefore, this can significantly reduce the number of driven tables I/O cost .
The best situation is Join Buffer Large enough , It can accommodate all records in the result set of the drive table . In this way, you only need to access the driven table once to complete the connection operation .
MySQL This is added to Join Buffer The nested loop join algorithm is called Block based nested loop connections (Block Nested-Loop Join) Algorithm .
The association process at this time is like this :
1、 It is preferred to list the drivers that meet the conditions B All the data is loaded into join buffer in ( Because the driving table is usually a small table , More save a space ).
2、 Scan driven table A, Take out the rows in the table and join buffer Drive table in B Match and query the data in . On the matching, it remains the result of the left back , Or throw it away .
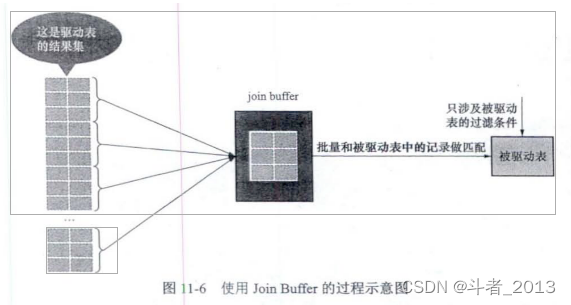
MySQL Will drive the table B Data in , Put in batches into join buffer in . Each time new data is placed in join buffer Before , The last data will be cleared . also , Every time you put in new data , Will drive the table again A Scan the data in and join buffer in Data association matching .
here , If properly increased join buffer Size , You can reduce the number of times to put in batches , It can also reduce the number of scans of the driven table . Therefore, under certain circumstances , Appropriate increase join_buffer_size Value , Can provide join Query efficiency .
8、 ... and 、 Optimization of join query
1、 The inner join query can be optimized by selecting the driving table
The positions of the internally connected driving table and the driven table can be converted to each other , And left ( Outside ) Connect and right ( Outside ) The connected drive table and driven table are fixed .
As a result, the inner join may reduce the overall query cost by optimizing the join order of the table, while the outer join cannot optimize the join order of the table .
commonly mysql The query optimizer of will automatically select the small table in the inner join query as the driving table .
2、 By establishing an index on the query conditions of the driven table
1、 Query optimization for driving tables
Because of the steps 1 Targeted at t1 The filter condition for is t1.m1> 1, So it can be m1 Index on field .
t1.m1> 1.
2、 Query optimization for driven tables
For driven tables t2 Query criteria for , contain 2 A field t2.m2=2、t2.n2<‘d’
You can build a joint index , You can also index separately , Single index is preferentially established on the condition of equivalent query .
Be careful ️:
There is an old misunderstanding here , Simply think of query optimization for associated queries , It is necessary to establish an index for the fields in the association condition to improve the query efficiency .
It can't be said to be completely wrong , But it's essentially right Join The cognition of query conditions is generally .
Queries against driven tables , Only using the index can improve the query efficiency , As for whether the fields in the association condition are not mandatory .
3、 Optimize by overriding indexes
Only the necessary fields are returned , Improve overlay index hit , Avoid the consumption of back table query , At the same time reduce Join Buffer ( Connection buffer ) Space consumption of .
The query list and filter criteria of the join query may only involve some columns of the driven table . If these columns are all part of a secondary index , Then you can use the overlay index , Avoid the consumption of back table query .
4、 Via connection buffer Join Buffer Optimize
Appropriate increase join buffer Size , You can reduce the number of times that the drive table data is placed in batches , It can also reduce the number of scans of the driven table . Therefore, under certain circumstances , Appropriate increase join_buffer_size Value , Can provide join Query efficiency .
summary
1、 In essence , Join is to take out the records in each table and match them in turn , And send the matched combination to the client . If you don't add any filter conditions , The resulting set is the Cartesian product .
2、 Connection query is divided into inner connection and outer connection , The external connection can be divided into left external connection and right external connection .
3、 The fundamental difference between inner connection and outer connection is , The record in the drive table does not conform to on Clause ,
The inner connection will not add the record to the final result set , And the external connection will .
4、 The internal process of connection query is described in detail .
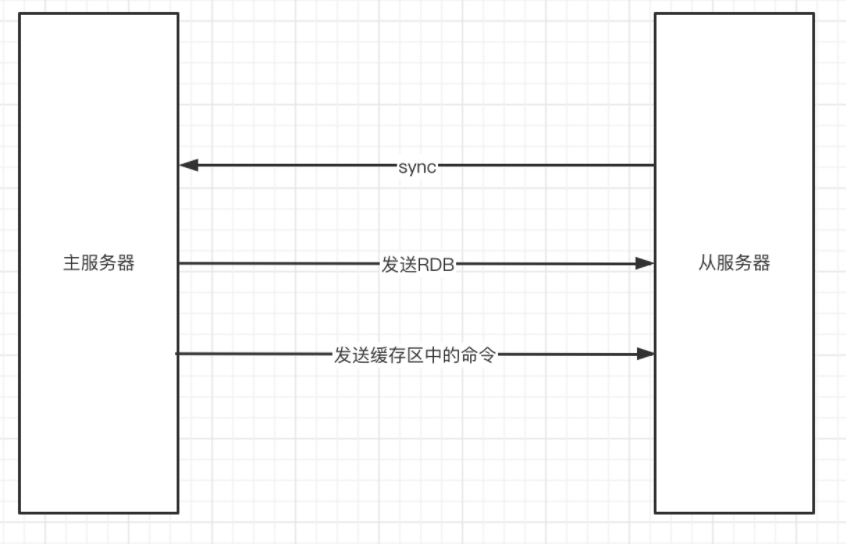
5、Mysql Internal buffer (Join Buffer) Cache drive table data , Reduce the number of scans of the driven table , Improve connection query performance .
6、 This paper introduces the optimization means of connection query .
版权声明
本文为[Fighter_ two thousand and thirteen]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231506175042.html
边栏推荐
- Compiling OpenSSL
- 封面和标题中的关键词怎么写?做自媒体为什么视频没有播放量
- async关键字
- Llvm - generate addition
- Role of asemi rectifier module mdq100-16 in intelligent switching power supply
- 8.2 text preprocessing
- Little red book timestamp2 (2022 / 04 / 22)
- Redis master-slave synchronization
- Sword finger offer (1) -- for Huawei
- API gateway / API gateway (III) - use of Kong - current limiting rate limiting (redis)
猜你喜欢

Leetcode exercise - 396 Rotation function
LeetCode149-直线上最多的点数-数学-哈希表

我的树莓派 Raspberry Pi Zero 2W 折腾笔记,记录一些遇到的问题和解决办法
Redis master-slave synchronization

Leetcode153 - find the minimum value in the rotation sort array - array - binary search
Tun model of flannel principle
asp. Net method of sending mail using mailmessage
LeetCode 练习——396. 旋转函数
UML学习_day2
Comment eolink facilite le télétravail
随机推荐
async关键字
Have you learned the basic operation of circular queue?
Flink DataStream 类型系统 TypeInformation
Tencent has written a few words, Ali has written them all for a month
Differential privacy (background)
Unity_ Code mode add binding button click event
asp. Net method of sending mail using mailmessage
adobe illustrator 菜單中英文對照
Example of time complexity calculation
How to use OCR in 5 minutes
Async void caused the program to crash
LeetCode 练习——396. 旋转函数
Kubernetes详解(十一)——标签与标签选择器
Application of skiplist in leveldb
Practice of unified storage technology of oppo data Lake
Common interview questions of operating system:
Design of digital temperature monitoring and alarm system based on DS18B20 single chip microcomputer [LCD1602 display + Proteus simulation + C program + paper + key setting, etc.]
Educational Codeforces Round 127 A-E题解
Explain TCP's three handshakes in detail
Alexnet model