当前位置:网站首页>数据库 SQL 优化大总结之:百万级数据库优化方案
数据库 SQL 优化大总结之:百万级数据库优化方案
2022-08-11 09:33:00 【InfoQ】
select id from t where num = 0
select id from t where num=10 or Name = 'admin'
select id from t where num = 10
union all
select id from t where Name = 'admin'
select id from t where num in(1,2,3)
select id from t where num between 1 and 3
select num from a where num in(select num from b)
select num from a where exists(select 1 from b where num=a.num)
select id from t where name like ‘%abc%’
select id from t where num = @num
select id from t with(index(索引名)) where num = @num
select id from t where num/2 = 100
select id from t where num = 100*2
select id from t where substring(name,1,3) = ’abc’ -–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′) = 0 -–‘2005-11-30’
select id from t where name like 'abc%'
select id from t where createdate >= '2005-11-30' and createdate < '2005-12-1'
select col1,col2 into #t from t where 1=0
create table
oracle(rownum),sqlserver(top)条件是一个好的方法。下面是一个mysql示例:
while(1){
mysql_query(“delete from logs where log_date <= ’2012-11-01’ limit 1000”);
if(mysql_affected_rows() == 0){
break;
}
usleep(50000)
}
边栏推荐
猜你喜欢
Typora和基本的Markdown语法
基于 VIVADO 的 AM 调制解调(1)方案设计

神经网络需要的数学知识,神经网络的数学基础
![Array, string, date notes [Blue Bridge Cup]](/img/71/242804a93332fc545662b983f3aa2a.png)
Array, string, date notes [Blue Bridge Cup]
WooCommerce Ecommerce WordPress Plugin - Make American Money
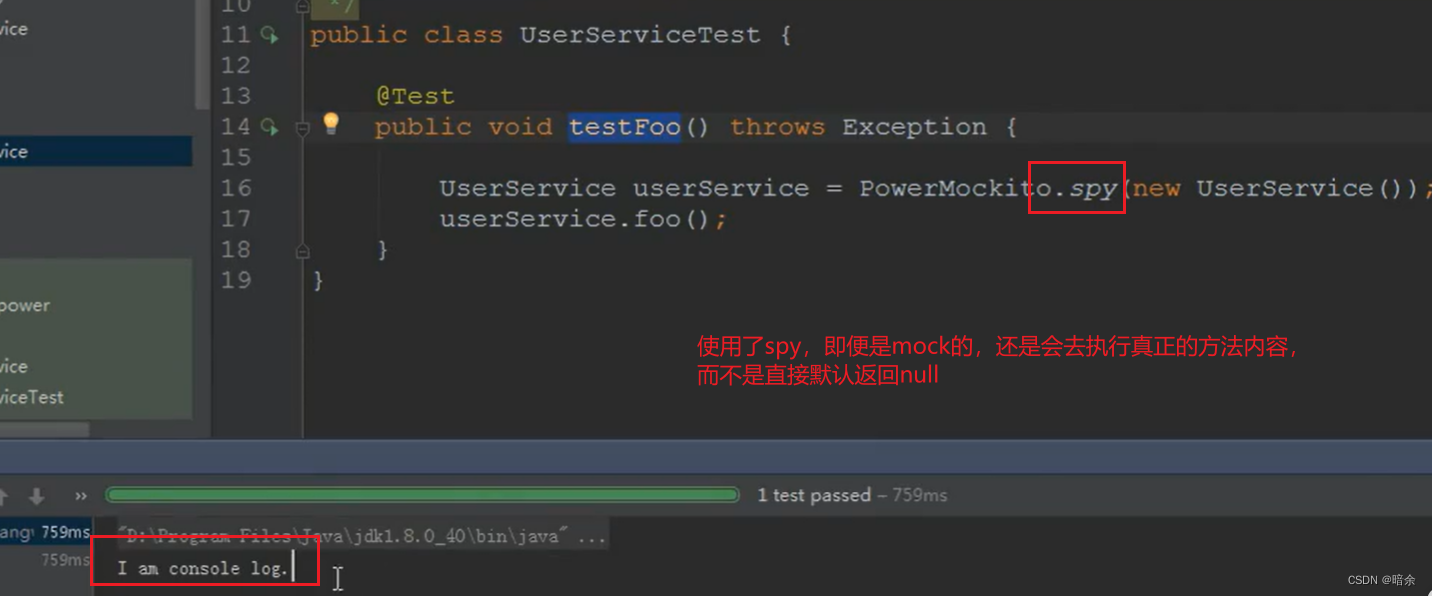
单元测试系统化讲解之PowerMock
nodejs worker_threads的事件监听问题
Redis的客户端连接的可视化管理工具

The no-code platform helps Zhongshan Hospital build an "intelligent management system" to realize smart medical care
How to use QTableWidget
随机推荐
Primavera Unifier -AEM 表单设计器要点
canvas文字绘制(大小、粗体、倾斜、对齐、基线)
ES6:数值的扩展
MySql事务
MySQL性能调优,必须掌握这一个工具!!!(1分钟系列)
canvas图形操作(缩放、旋转、位移)
清除微信小程序button的默认样式
ES6: Expansion of Numerical Values
Adobe LiveCycle Designer report designer
qspi 接口与普通四线SPI 接口什么区别?
零基础创作专业wordpress网站12-设置标签栏图标(favicon)
谁能解答?从mysql的binlog读取数据到kafka,但是数据类型有Insert,updata,
【wxGlade学习】wxGlade环境配置
新一代开源免费的轻量级 SSH 终端,非常炫酷好用!
unity shader 测试执行时间
5分钟快速为OpenHarmony提交PR(Web)
Validate the execution flow of the interceptor
oracle使用online_catalog收集数据,想看下online_catalog模式修改表字
腾讯电子签开发说明
无代码平台助力中山医院搭建“智慧化管理体系”,实现智慧医疗