当前位置:网站首页>groutine
groutine
2022-04-23 13:59:00 【面试被拒1万次】
go的并发编程
并发两个goroutine中同时操作了 一个共享资源,引发的竞争行为
1. 使用原子函数
2. 使用互斥锁
3. 使用通道
并发和并行

并发是同一个时间段内做很多事(同时发生),比如一个线程管理多个goroutine,一个时间段内会执行多个goroutine, 这个时间段内,这些任务可能同时执行,也可能不是同时执行(所以并发在概念上 包括“并行”)
并行是同一时刻做很多事(同一时刻),多个线程管理多个gotoutine
多线程程序在单核上运行,就是并发;多线程程序在多核上运行,就是并行。
了解并发模型之前(了解goroutine 和 线程的区别)
Goroutine:是建立在线程之上的轻量级的抽象。它允许我们以非常低的代价在同一个地址空间中并行地执行多个函数或者方法。相比于线程,它的创建和销毁的代价要小很多,并且它的调度是独立于线程的
- goroutine与线程区别
- 内存消耗更小
Goroutine所需要的内存通常只有2kb,而线程则需要1Mb(500倍) - 创建和销毁消耗小
Goroutine的创建和销毁都是自己管理,
线程的创建和销毁是 需要内核管理的,消耗更大 - 上下文切换
线程是抢占式的,一段时间内线程执行完成,其他线程抢占cpu,需要保存很多线程状态,用来再次执行的时候恢复线程,
goroutine 的调度是协同式,不需要切入内核,只需要保存少量的寄存器信息需要保存和恢复
go 的CSP 并发模型
并发的两种形式:
“不要使用共享内存通信,要使用通信来共享内存”
- 多线程共享内存
普通的线程并发模型,线程的通信使用共享内存的方式进行,在访问共享数据(例如数组,Map,或者某个结构体或对象的时候)使用锁(互斥锁,自旋锁,读写锁,原子锁)来访问。 - csp模型,使用通信来共享内存
通过goroutine和channel来通信-
goroutine 是go的 并发执行单位,生成一个goroutine
go func()
-
channel 是goroutine之间的通信机制,就是goroutine之间的管道
ch:= make(chan type)
-
并发模型代码:
func send(wg *sync.WaitGroup,send chan<- int){
defer wg.Done()
send <- 1
}
func received(wg *sync.WaitGroup,received <-chan int){
defer wg.Done()
<- received
}
func main(){
ch:= make(chan int)
var wg sync.WaitGroup
go send(&wg,ch)
go received(&wg,ch)
wg.wait()
}
Go并发模型的实现原理(MPG调度模型)
多线程模型
- M:1 (多个用户级线程 对应 一个内核线程)
M(多个用户级线程) :这种管理方式都是在用户态管理,存在一个线程库,包含了线程的创建,调度,管理和销毁。在这个线程库中除了正常执行的任务线程之外,还有一个专门负责线程调度的线程。线程的同步,切换 等工作都是自己完成
1(内核线程):对操作系统内核而言,感知不到线程的存在,感知的是一个进程,并不知道多线程的存在
模型优点:
- 灵活性: 因为操作系统不知道线程的存在,所以在任何操作系统上都能应用
- 线程切换快: 在用户态进行切换,无序进入内核状态
- 不用修改操作系统:实现简单
模型缺点:
-
编程变得诡异:因为用户态线程需要相互合作才能运转,这样在写程序的时候必须斟酌在什么时候让出CPU给其他线程使用
-
健壮性差: 在执行过程中,如果一个线程受阻,他讲无法将控制权交出来,导致整个进程都无法前进

-
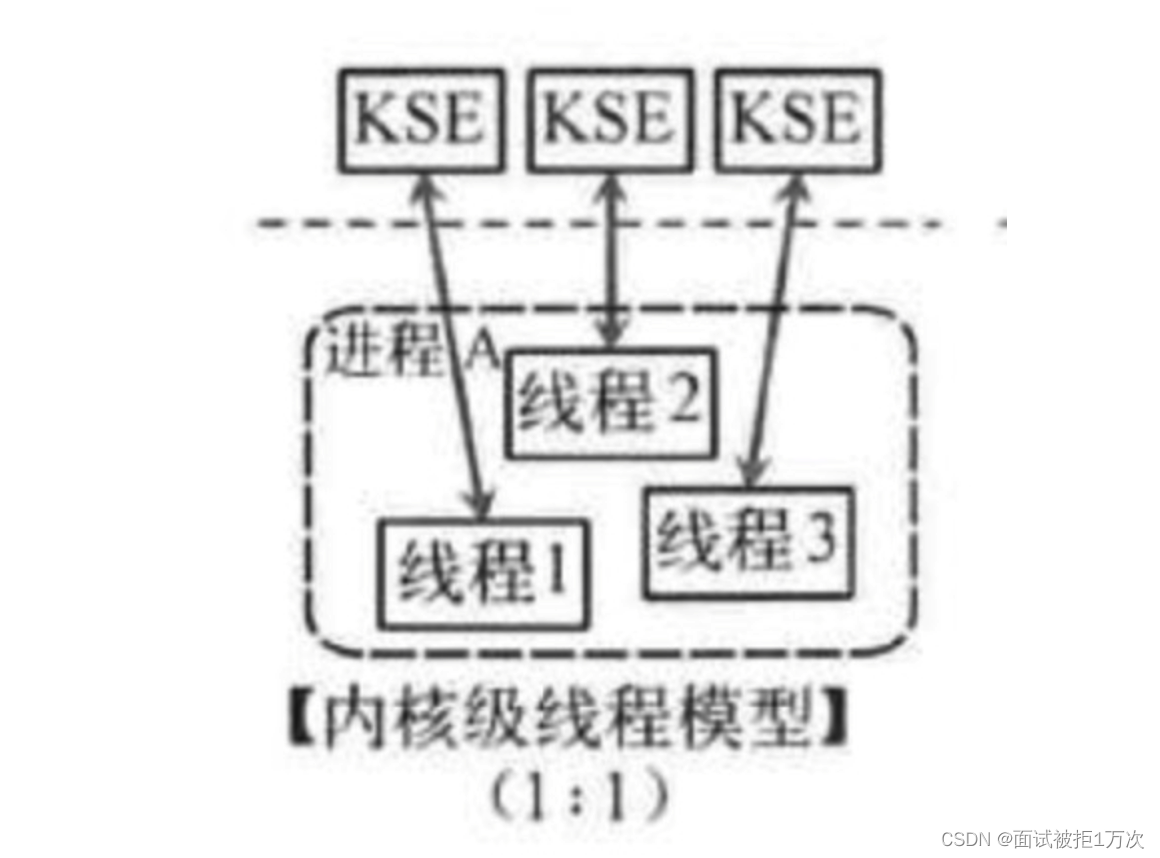
1:1 (一个用户线程对应一个内核线程)
内核级线程,就是线程创建,调度,管理,销毁都是在内核实现的,这样操作系统同时保有进程控制块和线程控制块
模型优点
用户编程简单:因为线程的复杂性由系统承担
模型缺点
- 效率较低:每次线程切换都需要内核,由操作系统调度
- 占用内核稀缺的内核资源:如果内核空间溢出,操作系统将停止运转
3.M:N (两级线程模型)
这种模型 介于用户级线程 和 内核级线程模型之间,一个进程对应多个内核级线程,但是进程中的线程不和内核线程一一对应。
模型会先创建多个内核级线程,然后用自身的用户级线程取对应创建多个内核级线程,自身的线程由用户线程自己调度,内核的线程由操作系统内核去调度

> go的线程MPG模型就是一个特殊的两级线程模型
Go线程实现模型MPG
M指的是Machine,一个M直接关联了一个内核线程。由操作系统管理。
P指的是**”processor”**,逻辑处理器,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。将等待执行的G与M对接。Go的运行时系统会适时地让P与不同的M建立或断开关联,以使P中的那些可运行的G能够及时获得运行时机.
(Processor)的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数runtime.GOMAXPROCS()进行设置
G指的是Goroutine,其实本质上也是一种轻量级的线程。包括了调用栈,重要的调度信息。

-
一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。
-
P的数量由环境变量中的GOMAXPROCS决定,通常来说它是和核心数对应,例如在4Core的服务器上回启动4个线程。G会有很多个,每个P会将Goroutine从一个就绪的队列中做Pop操作,为了减小锁的竞争,通常情况下每个P会负责一个队列。
-
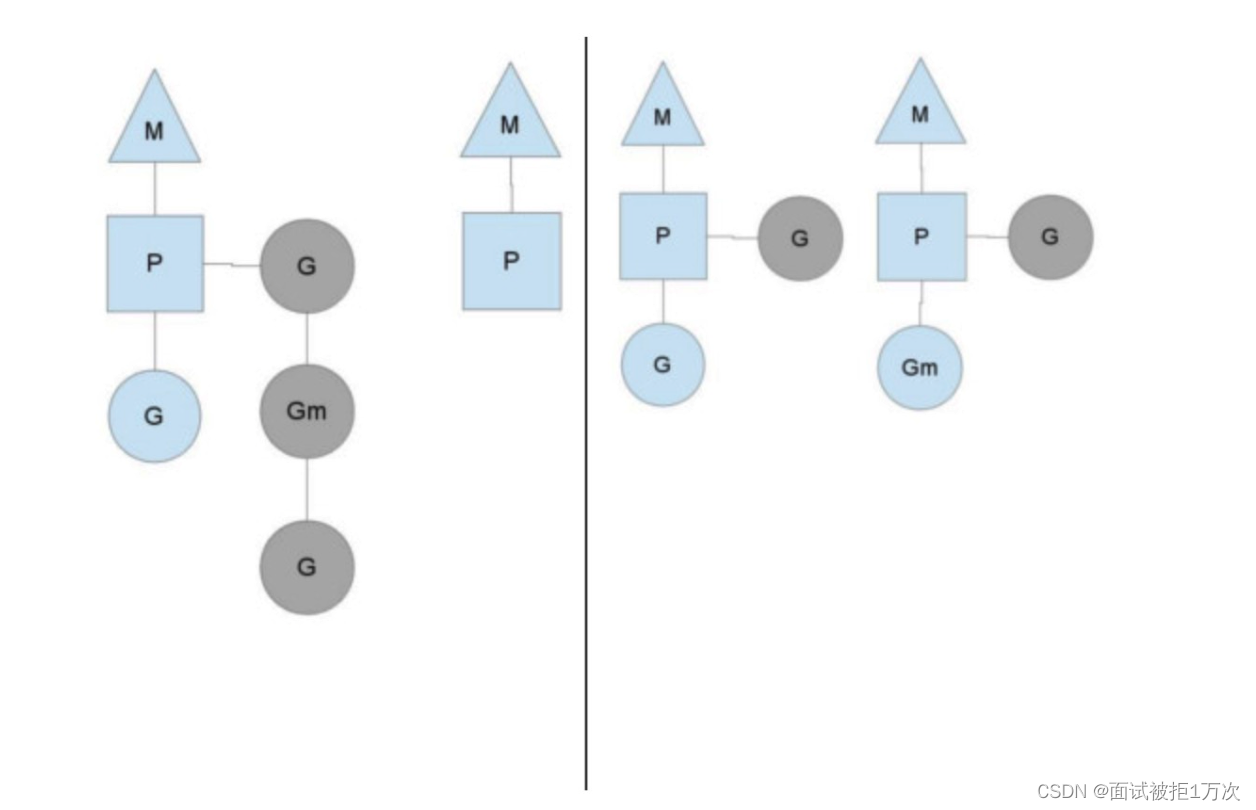
图中P正在执行的Goroutine为蓝色的;处于待执行状态的Goroutine为灰色的,灰色的Goroutine形成了一个队列runqueues
调度逻辑

goroutine 阻塞 :
一个很简单的例子就是系统调用sysall,一个线程肯定不能同时执行代码和系统调用被阻塞,这个时候,此线程M需要放弃当前的上下文环境P,以便可以让其他的Goroutine被调度执行。
如上图左图所示,M0中的G0执行了syscall,然后就创建了一个M1(也有可能本身就存在,没创建),(转向右图)然后M0丢弃了P,等待syscall的返回值,M1接受了P,将·继续执行Goroutine队列中的其他Goroutine。
当系统调用syscall结束后,M0会“偷”一个上下文,如果不成功,M0就把它的Gouroutine G0放到一个全局的runqueue中,然后自己放到线程池或者转入休眠状态。全局runqueue是各个P在运行完自己的本地的Goroutine runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
全局goroutine
上下文P会定期的检查全局的goroutine 队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。
该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!
版权声明
本文为[面试被拒1万次]所创,转载请带上原文链接,感谢
https://blog.csdn.net/m0_38023160/article/details/124325433
边栏推荐
- 19c environment ora-01035 login error handling
- MySQL [acid + isolation level + redo log + undo log]
- 专题测试05·二重积分【李艳芳全程班】
- Get the attribute value difference between two different objects with reflection and annotation
- leetcode--357. 统计各位数字都不同的数字个数
- SSM project deployed in Alibaba cloud
- [code analysis (7)] communication efficient learning of deep networks from decentralized data
- 函数只执行第一次的执行一次 once函数
- freeCodeCamp----arithmetic_ Arranger exercise
- Choreographer全解析
猜你喜欢

第一章 电商秒杀商品回顾

Business case | how to promote the activity of sports and health app users? It is enough to do these points well
Pytorch 经典卷积神经网络 LeNet

33 million IOPs, 39 microsecond delay, carbon footprint certification, who is serious?
![Three characteristics of volatile keyword [data visibility, prohibition of instruction rearrangement and no guarantee of operation atomicity]](/img/ec/b1e99e0f6e7d1ef1ce70eb92ba52c6.png)
Three characteristics of volatile keyword [data visibility, prohibition of instruction rearrangement and no guarantee of operation atomicity]

Express中间件③(自定义中间件)
3300万IOPS、39微秒延迟、碳足迹认证,谁在认真搞事情?

Dolphin scheduler integrates Flink task pit records

SQL learning | complex query
Elmo (bilstm-crf + Elmo) (conll-2003 named entity recognition NER)
随机推荐
Android: answers to the recruitment and interview of intermediate Android Development Agency in early 2019 (medium)
Analysis of cluster component gpnp failed to start successfully in RAC environment
Apache Atlas Compilation and installation records
[machine learning] Note 4. KNN + cross validation
JS 烧脑面试题大赏
freeCodeCamp----arithmetic_ Arranger exercise
JS force deduction brush question 103 Zigzag sequence traversal of binary tree
专题测试05·二重积分【李艳芳全程班】
函数只执行第一次的执行一次 once函数
Problems encountered in the project (V) understanding of operating excel interface poi
[VMware] address of VMware Tools
33 million IOPs, 39 microsecond delay, carbon footprint certification, who is serious?
2021年秋招,薪资排行NO
Force deduction brush question 101 Symmetric binary tree
SQL learning | complex query
【报名】TF54:工程师成长地图与卓越研发组织打造
The query did not generate a result set exception resolution when the dolphin scheduler schedules the SQL task to create a table
Leetcode | 38 appearance array
[code analysis (3)] communication efficient learning of deep networks from decentralized data
Record a strange bug: component copy after cache component jump