当前位置:网站首页>Database indexes and their underlying data structures
Database indexes and their underlying data structures
2022-08-11 10:03:00 【The last three-legged beast】
Indexed CRUD
-- view indexshow index from table name;-- create indexcreate index index name on table name (column name);-- delete indexdrop index index name on table name (column name);Creating and deleting indexes are extremely time-consuming operations with large data, because a lot of space is used to create (delete) the corresponding data structures.So most of the time we prepare the index at the very beginning of creating the table
Data structure of the index
The existence of the index is to make the data search more efficient, so we need a suitable data structure to store the data
Inappropriate data structure
When it comes to finding the fastest, most of us think of a hash table with a time complexity of O(1), but although a hash table is faster to query a single data, it is not efficient when querying a range of data.to the request.
Although the binary search tree can query single data and range data, the data is likely to form a form similar to a single fork tree. In this case, the time complexity will increase to linear complexity. At the same time, when searchingThe recursion depth is also unacceptable to the server.
What about the AVL tree and red-black tree after the binary search tree is upgraded?Although the AVL tree and the red-black tree avoid the possible linear complexity of the search, they still have a large depth under the stacking of a large amount of data, and consume a lot of space when querying.
In this case, the B+ tree came into being. Before understanding the B+ tree, we need to understand the B tree (some people also write it as the B-tree)
B-tree brief introduction
Just a brief introduction to the advantages of the B-tree, and will not go into the details of insertion and deletion methods, data storage methods in nodes
B-tree is an n-ary tree, and each node has multiple data, first a complete graph:
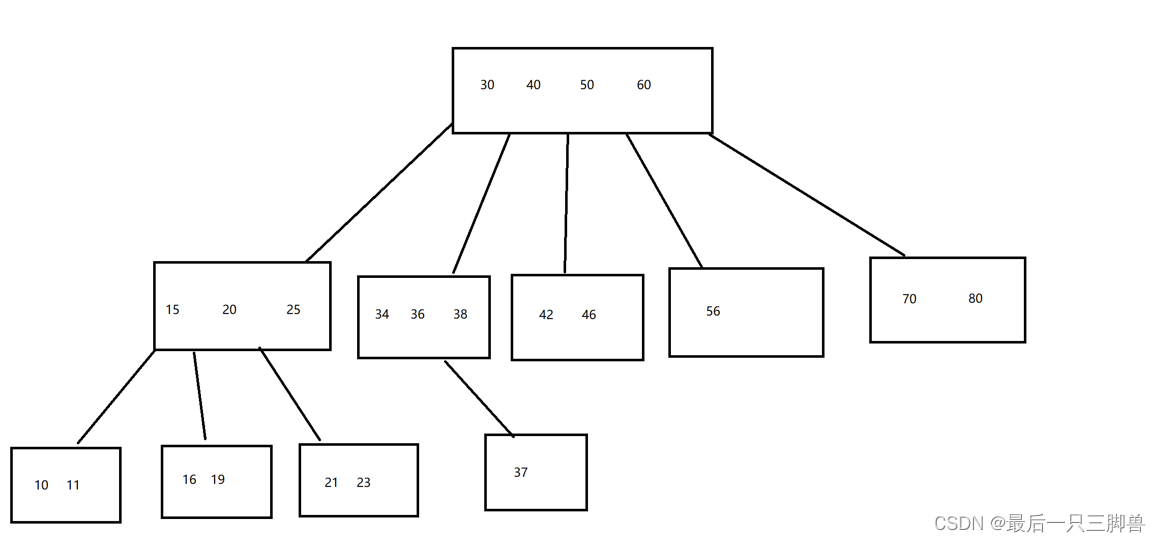
Take 30 and 40 in the parent node as an example, 34, 36, 38 belong to the numbers between 30 and 40, so use the nodes in the range of 30 and 40 to store them. If a node has a number, it willThere are a+1 child nodes.This is how the data in the B-tree is stored
B+ tree brief introduction
After introducing the B-tree, let's understand the storage method of the B+ tree and analyze why the B+ tree is so favored by the database
The B+ tree is also an n-ary tree like the B tree, but it is very different from the B tree. The complete picture is as follows:
![[External link image transfer failed, the origin site may have anti-leech mechanism, it is recommended to save the imageDirect upload(img-ZSzG561F-1660093289930)(C:\Users\yang\AppData\Roaming\Typora\typora-user-images\image-20220809173241303.png)]](/img/4b/aed2636a7b487ffe7a0f54097e553d.png)
- B+ tree has a number of nodes in a node, then its child nodes have a number
- The number used as the right boundary in the parent node will appear again in the child node. As shown in the figure above, the number 15 as the right boundary between the root node 8 and 15 is stored in the child node again.
- Because each time the number to the right of the boundary is taken to the child node, the leaf node of the B+ tree stores all the numbers.We finally connect the leaf nodes in the form of a linked list.
Understanding the data storage method of B+ tree, let us briefly talk about the advantages of B+ tree:
- First of all, as an n-ary tree, its depth is greatly reduced compared to a binary tree.
- The leaf nodes of the B+ tree store all the data. When we search for a range, we can traverse the required range directly through the linked list as long as we find a number.
- Because the leaf nodes store all the data, all our search operations can be performed on the leaf nodes, and we only need to store the index in the non-leaf node, and the data represented by the index is all stored in the leaf node.Since the index is just a string of numbers, the space occupation is very small, so the search greatly reduces the hard disk IO, which is also impossible for trees such as red-black trees!
Although we don't talk about the insertion efficiency of B+ tree here, we can intuitively feel the difficulty of data insertion and deletion, but as mentioned at the beginning, the database needs more search efficiency, and this exchange is worthwhile, but if it is a database with extremely frequent inserts and deletes, indexes should not be used.
边栏推荐
- 分割学习(loss and Evaluation)
- PowerMock for Systematic Explanation of Unit Testing
- Software custom development - the advantages of enterprise custom development of app software
- 你觉得程序员是一个需要天赋的职业吗?
- Convolutional Neural Network System,Convolutional Neural Network Graduation Thesis
- WooCommerce电子商务WordPress插件-赚美国人的钱
- 如何开手续费低靠谱正规的期货账户呢?
- 神经痛分类图片大全,神经病理性疼痛分类
- 【每日一题】640. 求解方程
- 神经网络需要的数学知识,神经网络的数学基础
猜你喜欢

前几天,小灰去贵州了
Primavera P6 Professional 21.12 Login exception case sharing
Primavera Unifier 高级公式使用分享

HDRP shader gets pixel depth value and normal information
Segmentation Learning (loss and Evaluation)
TIOBE - 2022年8月编程语言排行
深度神经网络与人脑神经网络哪些区域有一定联系?

Software custom development - the advantages of enterprise custom development of app software
服务器和客户端的简单交互

HDRP shader to get shadows (Custom Pass)
随机推荐
pycharm cancel msyql expression highlighting
神经网络图怎么分析,画神经网络结构图
力扣打卡----打家劫舍
如何开手续费低靠谱正规的期货账户呢?
Segmentation Learning (loss and Evaluation)
Dreamweaver网页作业——紫罗兰永恒花园动漫价绍网页 7页,含有table表格,js表单验证还有首页视频。以及列表页。浮
Simple strokes on the Internet
腾讯电子签开发说明
软件定制开发——企业定制开发app软件的优势
同态加密简介HE
困扰所有SAP顾问多年的问题终于解决了
pycharm 取消msyql表达式高亮
Deploying Robot Vision Models Using Raspberry Pi and OAK Camera
Array, string, date notes [Blue Bridge Cup]
深度神经网络与人脑神经网络哪些区域有一定联系?
Primavera Unifier 自定义报表制作及打印分享
海信自助机-HV530刷机教程
CreateJS加速地址
三次握手与四次挥手
[UE] 入坑