当前位置:网站首页>【自然语言处理】【向量表示】PairSupCon:用于句子表示的成对监督对比学习
【自然语言处理】【向量表示】PairSupCon:用于句子表示的成对监督对比学习
2022-08-10 18:40:00 【BQW_】
论文地址:https://arxiv.org/pdf/2109.05424.pdf
相关博客:
【自然语言处理】【对比学习】SimCSE:基于对比学习的句向量表示
【自然语言处理】BERT-Whitening
【自然语言处理】【Pytorch】从头实现SimCSE
【自然语言处理】【向量检索】面向开发域稠密检索的多视角文档表示学习
【自然语言处理】【向量表示】AugSBERT:改善用于成对句子评分任务的Bi-Encoders的数据增强方法
【自然语言处理】【向量表示】PairSupCon:用于句子表示的成对监督对比学习
一、简介
学习高质量的句子嵌入是 NLP \text{NLP} NLP中的基础任务。目标是在表示空间中将相似句子映射在相近的位置,将不相似的句子映射至较远的位置。近期的研究通过在 NLI \text{NLI} NLI数据集上训练取得了成功,该数据集上的任务是将句子对分类为三种类别中的一种:entailment、contradiction或者neutral。
尽管结果还不错,但先前的工作都有一个缺点:构成contradiction对的句子可能并需要属于不同的语义类别。因此,通过优化模型来区分entailment和contradiction,对于模型编码高级类别概念是不足够的。此外,标准的siamese(triplet)损失函数仅能从独立的句子对 ( triplets ) (\text{triplets}) (triplets)中学习,其需要大量的训练样本来实现有竞争力的效果。siamese损失函数有时能够将模型带入糟糕的局部最优解,其在高级语义概念编码上的效果会退化。
在本文中,受到自监督对比学习的启发,并提出了联合优化具有实例判别 (instance discrimination) \text{(instance discrimination)} (instance discrimination)的成对语义推理目标函数。作者将该方法称为 Pairwise Supervised Contrastive Learning(PairSupCon) \text{Pairwise Supervised Contrastive Learning(PairSupCon)} Pairwise Supervised Contrastive Learning(PairSupCon)。正如最近的一些研究工作所提及的,instance discrimination learning能够在没有任何明确指导的情况下将相似实例在表示空间中分组在附近。 PairSupCon \text{PairSupCon} PairSupCon利用这种隐含的分组作用,将同一类别的表示集合在一起,同时增强模型的语义entailment和contradiction推理能力。
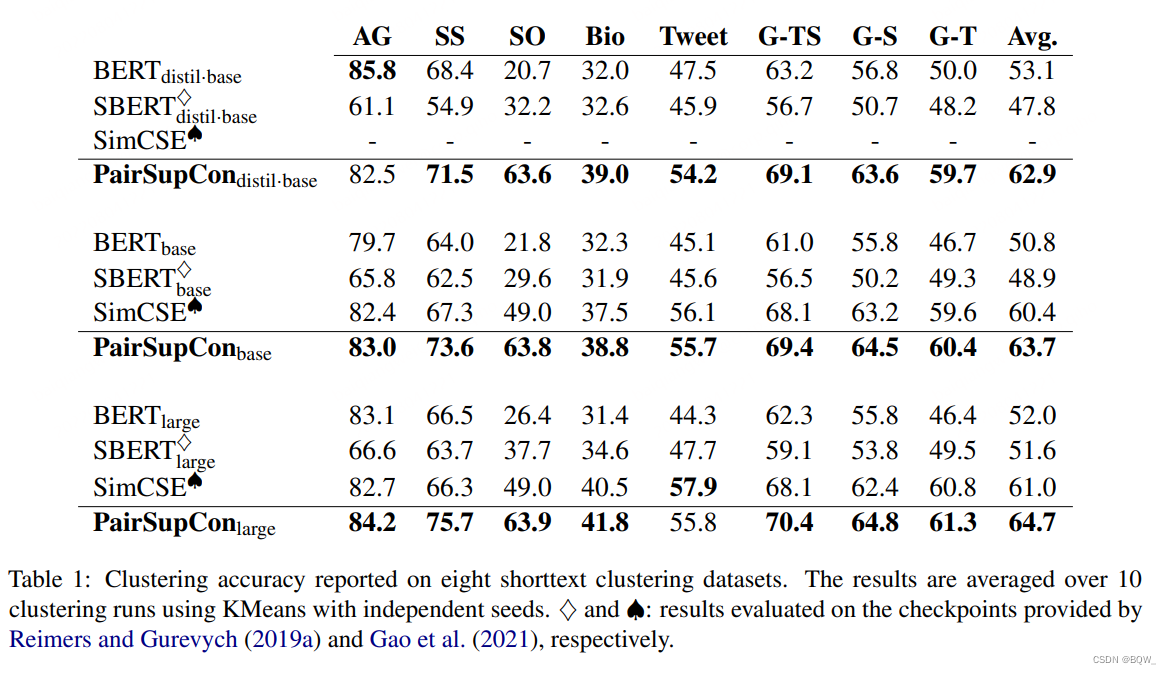
虽然先前的工作主要专注在语义相似度的两两评估上。在本文中,作者认为将高级语义概念编码至向量表示中也是一种重要的评估方面。先前在语义文本相似度任务 STS \text{STS} STS上表现最好的模型会导致类别语义结构嵌入的退化。另一方面,更好的捕获高层次的语义概念能够反过来促进在低级别语义entailment和contradiction推理的效果。这个假设与人类从上至下进行分类相一致。 PairSupCon \text{PairSupCon} PairSupCon在8个短文本聚类任务中实现了平均10%-13%的改善,并且在 STS \text{STS} STS任务上实现了5%-6%的改善。
二、方法
遵循 SBERT \text{SBERT} SBERT,采用 SNLI \text{SNLI} SNLI和 MNLI \text{MNLI} MNLI作为训练数据,并且为了方便将合并的数据称为 NLI \text{NLI} NLI。 NLI \text{NLI} NLI数据由标注的句子对组成,并且每个样本的形式为: (premise,hypothesis,label) \text{(premise,hypothesis,label)} (premise,hypothesis,label)。每个 premise \text{premise} premise句子都是从现有的文本源中选择的,并且每个 premise \text{premise} premise都会个各种人工标注的 hypothesis \text{hypothesis} hypothesis句子组成一对。每个 label \text{label} label都表示 hypothesis \text{hypothesis} hypothesis的类型以及分类关联的 premise \text{premise} premise和 hypothesis \text{hypothesis} hypothesis句子对的语义关系为三个类型: entailment \text{entailment} entailment、 contradiction \text{contradiction} contradiction和 neural \text{neural} neural。
先前的工作会在 NLI \text{NLI} NLI上独立优化siamese loss或者triplet loss。作者的目标是利用判别学习中的隐式分组效应来更好的捕获数据的高级类别语义结构,同时促进在低级别语义文本entailment和contradiction推荐目标的更好收敛。
1. 实例判别( Instance Discrimination \text{Instance Discrimination} Instance Discrimination)
作者利用 NLI \text{NLI} NLI的正样本对 (entailment) \text{(entailment)} (entailment)来优化实例级判别目标函数,其尝试将每个正样本对与其他的句子拉远。令 D = { ( x j , x j ′ ) , y j } j = 1 M \mathcal{D}=\{(x_j,x_j'),y_j\}_{j=1}^M D={(xj,xj′),yj}j=1M表示随机采样的minibatch,其中 y i = ± 1 y_i=\pm 1 yi=±1表示entailment或者contradiction。对于正样本对 ( x i , x i ′ ) (x_i,x_i') (xi,xi′)中的premise句子 x i x_i xi,这里的目标是将hypothesis句子 x i ′ x_i' xi′与同一个batch D \mathcal{D} D中的 2M-2 \text{2M-2} 2M-2个句子分开。具体来说,令 I = { i , i ′ } i M \mathcal{I}=\{i,i'\}_{i}^M I={ i,i′}iM表示 D \mathcal{D} D中的样本对应的索引,最小化下面的损失函数:
l ID i = − log exp ( s ( z i , z i ′ / τ ) ) ∑ j ∈ I ∖ i exp ( s ( z i , z j / τ ) (1) \mathcal{l}_{\text{ID}}^i=-\log\frac{\exp(s(z_i,z_{i'}/\tau))}{\sum_{j\in\mathcal{I}\setminus i}\exp(s(z_i,z_{j}/\tau)} \tag{1} lIDi=−log∑j∈I∖iexp(s(zi,zj/τ)exp(s(zi,zi′/τ))(1)
在上面的等式中, z j = h ( ψ ( x j ) ) z_j=h(\psi(x_j)) zj=h(ψ(xj))表示实体判断头的输出, τ \tau τ表示温度参数, s ( ⋅ ) s(\cdot) s(⋅)是cosine相似的,即 s ( ⋅ ) = z i ⊤ z i ′ / ∥ z i ∥ ∥ z i ′ ∥ s(\cdot)=z_i^\top z_{i'}/\parallel z_i\parallel\parallel z_{i'}\parallel s(⋅)=zi⊤zi′/∥zi∥∥zi′∥。等式(1)能够被解释了用于分类 z i z_i zi和 z i ′ z_i' zi′的分类损失函数的softmax。
类似地,对于hypothesis句子 x i ′ x_{i'} xi′,这里尝试从 D \mathcal{D} D中所有其他句子中判别premise句子 x i x_i xi。因此,定义对应的损失函数 l ID i ′ \mathcal{l}_{\text{ID}}^{i'} lIDi′为等式(1)中交换实例 x i ′ x_{i'} xi′和 x i x_i xi的角色。总的来说,最终的损失函数为平均 D \mathcal{D} D中的所有正样本。
L ID = 1 P M ∑ i = 1 M 1 y i = 1 ⋅ ( l ID i + l ID i ′ ) (2) \mathcal{L}_{\text{ID}}=\frac{1}{P_M}\sum_{i=1}^M\mathbb{1}_{y_i=1}\cdot(\mathcal{l}_{\text{ID}}^i+\mathcal{l}_{\text{ID}}^{i'}) \tag{2} LID=PM1i=1∑M1yi=1⋅(lIDi+lIDi′)(2)
这里, 1 ( ⋅ ) \mathbb{1}_{(\cdot)} 1(⋅)表示指示函数, P M P_M PM是 D \mathcal{D} D中的正样本数量。优化上面的损失函数不但有助于将类别语义信息隐含编码至向量表示中,也能够更好的促进成对语义推理能力。
2. 难负样本学习
等式(1)可以被重写为
l ID i = log ( 1 + ∑ j ≠ i , i ′ exp [ s ( z i , z j ) − s ( z i , z i ′ ) τ ] ) \mathcal{l}_{\text{ID}}^i=\log\Big(1+\sum_{j\neq i,i'}\exp[\frac{s(z_i,z_j)-s(z_i,z_{i'})}{\tau}] \Big) lIDi=log(1+j=i,i′∑exp[τs(zi,zj)−s(zi,zi′)])
其可以被看作是对标准triplet loss的扩展,通过将minibatch内的 2M-2 \text{2M-2} 2M-2个样本作为负样本。然而,负样本是从训练数据中均匀采样的,其忽视了这些样本包含的信息量。理想情况下,应该将那些来自不同语义组但是映射接近的难负样本分开。虽然在 NLI \text{NLI} NLI中没有类别级的监督,但是可以通过下面的方法近似负样本的重要度。
l wID i = log ( 1 + ∑ j ≠ i , i ′ exp [ α j s ( z i , z j ) − s ( z i , z i ′ ) τ ] ) (3) \mathcal{l}_{\text{wID}}^i=\log\Big(1+\sum_{j\neq i,i'}\exp[\frac{\alpha_js(z_i,z_j)-s(z_i,z_{i'})}{\tau}] \Big) \tag{3} lwIDi=log(1+j=i,i′∑exp[ταjs(zi,zj)−s(zi,zi′)])(3)
这里, α j = exp ( S ( z i , z h ) / t a u ) 1 2 M − 2 ∑ k ≠ i , i ′ exp ( S ( z i , z k ) / τ ) \alpha_j=\frac{\exp(S(z_i,z_h)/tau)}{\frac{1}{2M-2}\sum_{k\neq i,i'}\exp(S(z_i,z_k)/\tau)} αj=2M−21∑k=i,i′exp(S(zi,zk)/τ)exp(S(zi,zh)/tau),其能够被解释为针对 z i z_i zi, z j z_j zj在所有 2 M − 2 2M-2 2M−2个负样本的相对重要度。该重要度是基于假设:难负样本是那些在表示空间上与 z i z_i zi更接近的样本。
3. Entailment and Contradiction Reasoning
实例判别损失函数主要是用于将正样本对从其他样本对中分离出来,但并没有明确的强制来判别contradiction和entailment。为了这个目的,联合优化成对entailment和contradiction推理目标函数。这里采用基于softmax的交叉熵损失函数来形成成对分类目标函数。令 u i = ψ ( x i ) u_i=\psi(x_i) ui=ψ(xi)代表句子 x i x_i xi的向量表示,对于每个标注的句子对 ( x i , x i ′ , y i ) (x_i,x_{i'},y_i) (xi,xi′,yi),最小化下面的损失函数
l C i = CE ( f ( u i , u i ′ , ∣ u i − u i ′ ∣ ) , y i ) (4) \mathcal{l}_{C}^i=\text{CE}(f(u_i,u_{i'},|u_i-u_{i'}|),y_i) \tag{4} lCi=CE(f(ui,ui′,∣ui−ui′∣),yi)(4)
这里 f f f表示线性分类头, CE \text{CE} CE是交叉熵损失函数。不同于先前的工作,本工作将neural样本对从原始训练集中移除,并专注在语义entailment和contradiction的二分类问题上。这样做的动机是:neural可以通过实例判别损失函数来捕获。因此,这里移除了neural样本对来 PairSupCon \text{PairSupCon} PairSupCon的两种损失函数的复杂性,并改善学习效率。
- 总的损失函数
L = ∑ i = 1 M l C i + β 1 y i = 1 ⋅ ( l wID i + l wID i ′ ) (5) \mathcal{L}=\sum_{i=1}^M \mathcal{l}_C^i+\beta\mathbb{1}_{y_i=1}\cdot(\mathcal{l}_{\text{wID}}^i+\mathcal{l}_{\text{wID}}^{i'}) \tag{5} L=i=1∑MlCi+β1yi=1⋅(lwIDi+lwIDi′)(5)
其中, l C i \mathcal{l}_C^i lCi和 l wID i \mathcal{l}_{\text{wID}}^i lwIDi, l wID i ′ \mathcal{l}_{\text{wID}}^{i'} lwIDi′由等式(4)和等式(3)定义。在等式(5)中, β \beta β是一个平衡超参。
三、实验

边栏推荐
- 友邦人寿可观测体系设计与落地
- 请问下在datastream中用flinkcdc怎么设置jdbc的参数useSSL=false呀
- 【OpenCV】-物体的凸包
- Interview Question 04.12. Summation Path-dfs+Auxiliary Array Method
- 我们用48h,合作创造了一款Web游戏:Dice Crush,参加国际赛事
- 小分子PEG CAS:1352814-07-3生物素-PEG6-丙酸叔丁酯
- Introduction to 3 d games beginners essential 】 【 modeling knowledge
- 瑞吉外卖学习笔记4
- MSE 治理中心重磅升级-流量治理、数据库治理、同 AZ 优先
- redis 事件
猜你喜欢
三星Galaxy Watch5产品图片流出 非Pro表款亦有蓝宝石加持
QoS服务质量七交换机拥塞管理
IoU、GIoU、DIoU、CIoU四种损失函数总结

DefaultSelectStrategy NIOEventLoop执行策略

选择是公有云还或是私有云,这很重要吗?
Redis command---key chapter (super complete)
redis.exceptions.DataError: Invalid input of type: ‘dict‘. Convert to a byte, string or number first
MySQL安装步骤

魔方电池如何“躺赢”?解锁荣威iMAX8 EV“头等舱”安全密码
AIRIOT答疑第8期|AIRIOT的金字塔服务体系是如何搞定客户的?
随机推荐
MySql主要性能指标说明
入门:人脸专集2 | 人脸关键点检测汇总(文末有相关文章链接)
[教你做小游戏] 只用几行原生JS,写一个函数,播放音效、播放BGM、切换BGM
网络拓扑管理
2816. 判断子序列(双指针)
今日份bug,点击win10任务栏视窗动态壁纸消失的bug,暂未发现解决方法。
剑指 Offer 27. 二叉树的镜像(翻转二叉树)
多种深度模型实现手写字母MNIST的识别(CNN,RNN,DNN,逻辑回归,CRNN,LSTM/Bi-LSTM,GRU/Bi-GRU)
[Image segmentation] Image segmentation based on cellular automata with matlab code
【OpenCV】-物体的凸包
pytorch使用Dataloader加载自己的数据集train_X和train_Y
CEO对今天的CIO们真正的要求是什么?
弘玑Cyclone与风变科技达成战略合作:优势互补聚焦数字化人才培养
工业基础类—利用xBIM提取IFC几何数据
servlet映射路径匹配解析
剖析Framework面试—>>>冲击Android高级职位
Keras deep learning combat (17) - image segmentation using U-Net architecture
西安凯新(CAS:2408831-65-0)Biotin-PEG4-Acrylamide 特性
基于 RocksDB 实现高可靠、低时延的 MQTT 数据持久化
含有PEG 间隔基和一个末端伯胺基团(CAS:1006592-62-6)化学试剂