当前位置:网站首页>【图像分类】2022-ConvMixer ICLR
【图像分类】2022-ConvMixer ICLR
2022-08-10 02:02:00 【說詤榢】
【图像分类】2022-ConvMixer ICLR
论文题目:Patches Are All You Need?
论文链接:https://arxiv.org/abs/2201.09792
代码链接:https://github.com/locuslab/convmixer
发表时间:2022年1月
引用:Trockman A, Kolter J Z. Patches are all you need?[J]. arXiv preprint arXiv:2201.09792, 2022.
引用数:33
1. 简介
7行PyTorch代码实现的网络,就能在ImageNet上达到80%+的精度!
尽管卷积网络多年来一直是视觉任务的主导架构,但最近的实验表明,基于Transformer的模型,尤其是视觉Transformer(ViT),可能在某些设置下超过它们的性能。然而,由于变形金刚中自我注意层的二次运行时间,ViT需要使用补丁嵌入,将图像中的小区域组合成单个输入特征,以便应用于更大的图像尺寸。这就提出了一个问题:ViT的性能是由于固有的更强大的Transformer架构,还是至少部分地由于使用补丁作为输入表示?
在本文中,我们为后者提供了一些证据:具体地说,我们提出了ConvMixer,这是一个极其简单的模型,在精神上类似于ViT和更基本的MLP-Mixer,它直接操作补丁作为输入,分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。然而,相比之下,ConvMixer只使用标准的卷积来实现混合步骤。尽管它很简单,但我们表明,ConvMixer在类似的参数计数和数据集大小方面优于ViT、MLP-Mixer和它们的一些变体,此外还优于ResNet等经典视觉模型。
在本文中,作者探讨了一个问题:从根本上讲,视觉Transformer的强大性能是否可能更多地来自于这种基于patch的表示,而不是来自于Transformer结构本身?为了回答这一问题,作者提出了一个非常简单的卷积结构ConvMixer,
2. 网络
2.1 网络
ConvMixer 由一个 patch 嵌入层和一个简单的全卷积块的重复应用组成。该研究保持 patch 嵌入的空间结构,如下图 2 所示。patch 大小为 p 和嵌入维度为 h 的 patch 嵌入可以实现具有 c_in 输入通道、h 个输出通道、内核大小 p 和步长 p 的卷积:
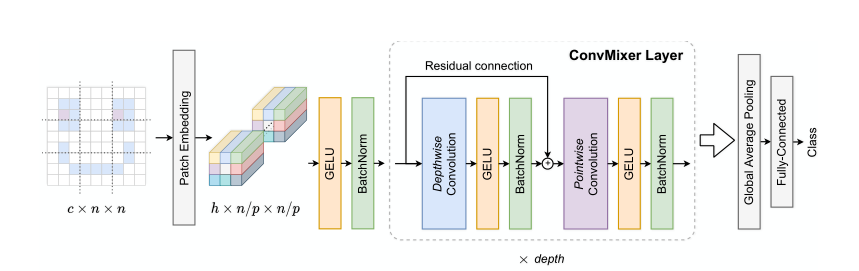
ConvMixer包括一个patch embedding层,然后重复应用一个简单的卷积块。模型结构图上图所示,像ViT一样,作者也同样运用了Patch Embedding层,Patch大小为 p p p,嵌入维数为 h h h,Patch Embedding层可以通过与输入通道为 C i n C_{in} Cin,输出通道为 h h h,kernel大小为 p p p,步长大小为 p p p的卷积来实现:
z 0 = B N ( σ { Conv c in → h ( X , stride = p , kernel_size = p ) } ) z_{0}=\mathrm{BN}\left(\sigma\left\{\operatorname{Conv}_{c_{\text {in }} \rightarrow h}(X, \text { stride }=p, \text { kernel\_size }=p)\right\}\right) z0=BN(σ{ Convcin →h(X, stride =p, kernel_size =p)})
ConvMixer模块由深度卷积(即,组数等于通道数 h h h的分组卷积)和逐点卷积(即,核大小为1 × 1的常规卷积)组成。每个卷积之后都有一个激活函数和BatchNorm:
z l ′ = B N ( σ { ConvDepthwise ( z l − 1 ) } ) + z l − 1 z l + 1 = B N ( σ { ConvPointwise ( z l ′ ) } ) \begin{aligned} z_{l}^{\prime} &=\mathrm{BN}\left(\sigma\left\{\text { ConvDepthwise }\left(z_{l-1}\right)\right\}\right)+z_{l-1} \\ z_{l+1} &=\mathrm{BN}\left(\sigma\left\{\text { ConvPointwise }\left(z_{l}^{\prime}\right)\right\}\right) \end{aligned} zl′zl+1=BN(σ{ ConvDepthwise (zl−1)})+zl−1=BN(σ{ ConvPointwise (zl′)})
在经过多个卷积块之后,作者应用了一个全局池化来获得大小为 h h h的特征向量,并将其传递给softmax分类器,输出分类结果。
Design parameters
ConvMixer的实例化依赖于四个参数:
- Patch Embedding的通道维度 h h h
- ConvMixer层的重复次数 d d d
- 控制模型中特征分辨率的patch大小 p p p
- depthwise卷积的卷积核大小k。
在后面的实例化中,作者将特定设置的ConvMixer表示为,其中 h 为通道维数, d 为卷积层的重复次数。

2.2 总结
在本文中,作者提出了ConvMixer,这是一种非常简单的模型,它仅使用标准卷积就能独立地混合patch embedding的空间和通道信息。虽然ConvMixer不是为了最大化准确率或速度而设计的,但ConvMixer优于Vision Transformer和MLP-Mixer,并与ResNet、DeiT和ResMLP性能相当。
虽然在文章中,作者将ConvMixer的Patch Embedding层对标了ViT的Transformer中的Patch Embedding层,但是个人觉得,这个部分也可以是看成ResNet的Stem层,只不过下采样的程度比较大,然后后面都是卷积操作,所以就是一个纯卷积模型,只不过设计上因为没有像ResNet那样的多次下采样率,所以看起来和实现起来会更加简单,只需要用很少的代码就能实现。
3. 代码
import torch.nn as nn
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)
作者给出的代码
def ConvMixer(h,d,k,p,n):
S,C,A=Sequential,Conv2d,lambda x:S(x,GELU(),BatchNorm2d(h))
R=type('',(S,),{
'forward':lambda s,x:s[0](x)+x})
return S(A(C(3,h,p,p)),*[S(R(A(C(h,h,k,groups=h,padding=k//2))),A(C(h,h,1))) for i
in range(d)],AdaptiveAvgPool2d(1),Flatten(),Linear(h,n))
边栏推荐
猜你喜欢

mysql -sql编程
![[Kali Security Penetration Testing Practice Tutorial] Chapter 6 Password Attack](/img/ac/e944d81afc741c38dc775d71dc9014.png)
[Kali Security Penetration Testing Practice Tutorial] Chapter 6 Password Attack

中级xss绕过【xss Game】
将信号与不同开始时间对齐
Anchor_generators.py analysis of MMDetection framework

按钮倒计时提醒
![[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration](/img/5f/907057956658a19306da21c71185ea.png)
[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration

storage of data in memory

RESOURCE_EXHAUSTED: etcdserver: mvcc: database space exceeded

【二叉树-中等】1261. 在受污染的二叉树中查找元素
随机推荐
Screen 拆分屏幕
数据治理(五):元数据管理
what is a microcontroller or mcu
2020.11.22 Exam Goldbach Conjecture Solution
UXDB现在支持函数索引吗?
sqlmap dolog外带数据
FusionCompute产品介绍
mysql -sql编程
RESOURCE_EXHAUSTED: etcdserver: mvcc: database space exceeded
微生物是如何影响身体健康的
基于C51的中断控制
OpenCV图像处理学习一,加载显示修改保存图像相关函数
idea 删除文件空行
谷歌翻译器-谷歌翻译器软件批量自动翻译
P1564 Worship
翻译工具-翻译工具下载批量自动一键翻译免费
STM32F103驱动HCSR04超声波测距显示
2020.11.22考试哥德巴赫猜想题解
实操|风控模型中常用的这三种预测方法与多分类场景的实现
将信号与不同开始时间对齐