当前位置:网站首页>研发了 5 年的时序数据库,到底要解决什么问题?
研发了 5 年的时序数据库,到底要解决什么问题?
2022-08-11 07:56:00 【涛思数据TDengine】
作者:陶建辉|TDengine 创始人、核心开发
经常有人问我,为什么 2017 年在市场上已经有这么多时序数据库的背景之下,你还敢去开发一款新的时序数据库?为什么你的团队都 80 多人了,五年过去,还在埋头研发 TDengine 这一款产品?周末写篇博文,与大家分享一下我的想法。
时序数据库(Time Series Database)并不是一个新兴的概念。追溯其历史,1999 年问世的 RRDtool 应该是最早的专用时序数据库了。在著名的数据库排行网站 DB-engines 上面,时序数据库的逐步流行起始于 2015 年,而在过去的两年,时序数据库成为流行度最高的数据库。
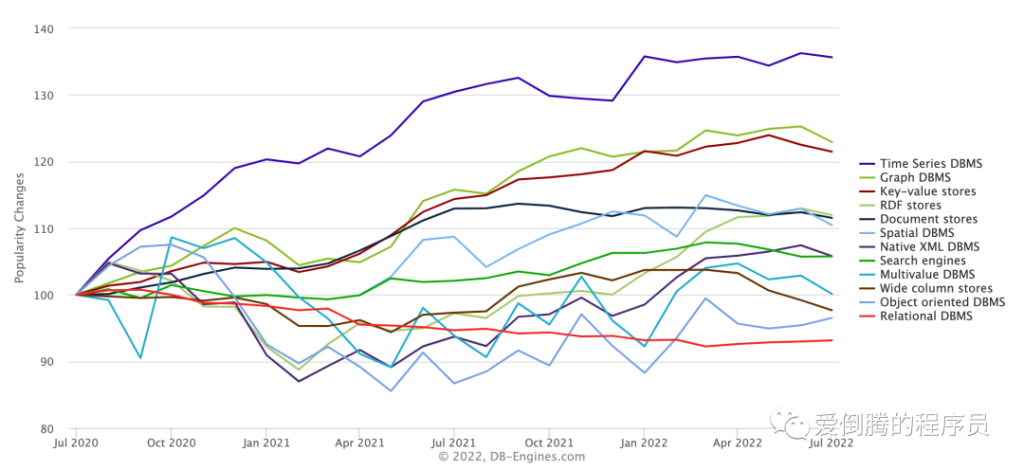
过去两年数据库发展趋势榜
2016 年底,我看到万物互联的时代已经到来,高效处理各种传感器、设备产生的时序数据将成为一重要的技术领域,因此就着手开发 TDengine 这个新的时序数据库系统,2017 年 6 月正式组建团队。
TDengine 面市以来,从 1.0 到 2.0,从核心功能开源到集群功能开源,得到了大量商业客户和社区用户的高度认可,全球安装的 TDengine 运行实例数已经超过 13 万,每天克隆源代码的人次都超过 1000,在全球开发者社区产生了一定的影响力。
刚开始创业的时候,我就进行了深入的思考:新的时序数据库还有生存空间吗?换句话说,现有的这些数据库对应用而言是不是已经足够好了?它们能满足业务需求吗?现在我也经常思考,时序数据库值得你死磕吗?今天我从技术的角度来分析一下这个问题,与大家分享。
1、可扩展性 / Scalability
由于 IT 基础设施的爆炸性增长和物联网(IoT)的出现,数据的规模正在迅速增长。一个现代的数据中心可能需要收集多达 1 亿个指标——从网络设备和服务器到虚拟机、容器和微服务的一切都在不断地发送时间序列数据。再比如,分布式电网中的每个智能电表每分钟至少产生一个数据点,而中国的智能电表,至少有十亿个。任何一台计算机都不可能处理这么多的数据,所以任何旨在处理时间序列数据的系统必须是可扩展的。
然而,许多市场领先的时序数据库并没有提供可扩展的解决方案。就拿 Prometheus 来说,它可以算是用于 Kubernetes 环境的时序数据库的一个事实标准,但它并没有提供分布式的设计,而必须依靠 Cortex、Thanos 或其他第三方工具来实现可扩展性。InfluxDB 有集群功能,但是只向企业客户提供,没有选择开源。
为了解决这个问题,很多开发者的选择是,在应用程序和时序数据库服务器(如 InfluxDB 或 Prometheus)之间部署一个代理服务器,来建立自己的可扩展的解决方案。然后根据时序 ID 的哈希值,将收集到的时序数据在多个时序数据库服务器之间分配。从数据写入角度看,这确实解决了可扩展性的问题。但对于查询,代理服务器必须合并来自每个底层节点的查询结果,而这是一个很大的技术挑战。对于一些查询,比如计算标准差,还不能只是合并结果,而是必须从每个节点检索原始数据。这意味着需要重写整个查询引擎,需要的工作量相当之大。
进一步,仔细研究一下 InfluxDB 和 TimeScaleDB 的设计,就会发现,它们的可扩展性实际上是相当有限的。它们将元数据存储在一个中心位置,每个时间序列总是会关联一组标签或标识。这意味着,如果你有 10 亿个时间序列,系统就需要存储 10 亿组标签。看出问题了吗?当你要聚合多个时间序列时,系统需要首先确定哪些时间序列符合标签过滤条件,而在一个很大的数据集中,这会导致很大的延迟。这就是所谓的时间序列数据库的 High-cardinality 问题。
那么应该如何解决这个问题呢?答案就是元数据处理的分布式设计。元数据不能存储在一个中心位置,否则它很快就会成为一个瓶颈。一个简单的解决方案是,使用分布式关系数据库来处理元数据,但是这会增加系统的复杂度,使得系统更难维护,成本也更高了。
TDengine 1.x 的设计就是将所有元数据存储在管理节点(mnode)上,所以它也有 High-cardinality 的问题。在 TDengine 2.x 中,我们做了一些改进,就是将标签值存储在每个虚拟节点(vnode)而不是中央管理节点上, 聚合查询速度有保证,但系统启动时间在时间线超过千万后不可忍受,没有完全解决这个业内的难题。
2、复杂性 / Complex
数据库是存储和分析数据的工具,但时序数据处理需要的可不仅仅是存储和分析。在一个典型的时序数据处理平台中,时序数据库总是要与支持流处理、缓存、数据订阅以及其他功能的工具集成,因此整个数据处理系统是有一定的复杂度的。
流式处理 / Stream Processing
时序数据就是一个流。为了更快地执行操作或者发现错误,我们需要在数据点到达系统时就进行分析和处理,所以流处理天然适合时序数据。流处理可以是时间驱动的,即在设定的时间间隔内产生新的结果(在时序数据库中一般称为连续查询),也可以是事件驱动的,即只要有新的数据点到达就产生新的结果。
InfluxDB、Prometheus、TimescaleDB 和 TDengine 都支持连续查询。这对于监控仪表盘是非常有用的,因为所有的图表都可以定期更新。但连续查询并不能满足所有的数据处理要求,就像 ETL,复杂事件处理,所以时序数据库需要支持事件驱动的流处理。
遗憾的是,目前市面上还没有哪款时序数据库支持。一般的方式是,将时序数据库与 Spark、Flink 或其他流处理工具集成,而这些工具并不是为时序数据处理设计的。这些工具很难处理时间序列数据集中的数百万甚至数十亿的流,即使它们能够胜任,也要以大量的计算资源为代价。
缓存 / Caching
对于很多时序数据应用,像应用性能监控,某个特定时间的数据值并不重要,这些应用只关注趋势。然而,物联网场景是个例外,应该特别注意。比如,一个车队管理系统总是要知道每辆卡车的当前位置。对于一个智能工厂,系统总是需要知道每个阀门的当前状态和每个电表的当前读数。
大多数时序数据库,包括 InfluxDB、TimescaleDB 和 Prometheus,本身都不能保证以最小的延迟返回时间序列中最新的数据点。为了使每个时间序列的当前值能够尽可能快地返回,没有高延迟,很多开发者选择将这些数据平台与 Redis 集成。当新的数据点到达系统时,它们必须被同时写入 Redis 以及数据库中。这种解决方案确实有效,但增加了系统的复杂性和运维成本。
TDengine 从其第一个版本开始就支持缓存了。在 TDengine 的很多用户案例中,Redis 可以完全从系统中移除,从而使整个数据平台的运行更加简单,成本更低。
数据订阅 / Data Subscription
消息队列在很多系统架构中有着重要的作用。传入的数据点首先被写入消息队列,然后被系统中的其他组件消费,包括数据库。消息队列中的数据通常会被保留一段指定的时间(比如 Kafka 中的 7 天)。这与时序数据库中的保留策略是一样的。某个角度上来看,存储的设计上,消息队列与时序数据库没有本质的区别。
大多数时序数据库写入数据的效率非常高,一秒钟可以达到数百万个数据点。这意味着,如果时序数据库能够提供数据订阅功能,它们可以完全取代消息队列,这就再次简化了系统的设计,进而降低了成本。
目前市场上仅仅 TDengine 提供数据订阅的功能,但现有版本订阅的性能不够,在大部分场景下,无法将 Kafka 这类软件从系统中剔除。
结论:没有事件驱动的流处理、缓存和数据订阅这些功能,尽管时序数据库仍然可以工作,但开发人员不得不将其与其他工具集成,来实现所需的功能。这使得系统设计会相当复杂,需要更多资源,也更难维护。如果时序数据库内置了这些功能,整个系统架构就可以极大简化,运维成本也会大大降低。
3、云原生 / Cloud Native
云计算越来越流行,云计算最美妙最吸引人的地方在于它的弹性——存储资源和计算资源没有上限,而我们只需要为实际使用的资源付费。这也是所有应用程序,包括时序数据库,都在向云上转移的一个主要原因。
遗憾的是,大多数数据库只是“云就绪”(cloud-ready),而非云原生(cloud-native)。当你购买某些数据库供应商提供的云服务时,比如 TimescaleDB,你需要告诉系统你想要多少虚拟服务器(包括 CPU 和内存配置),以及多少存储。即使你没有运行任何查询,你仍然不得不为计算资源付费,如果你的数据规模增长了,你还需要决定是否购买更多资源。这种云解决方案,其实只是数据库服务提供商在转售云平台。
要充分利用云平台提供的优势,时序数据库必须是云原生的。为了实现这一点,时序数据库需要重新设计。这时候要重点考虑如下几点。
- 计算和存储分离:在容器化环境中,特定的容器可能在任何时候启动或关闭,但存储的数据是持久化的。传统的数据库设计无法应对这种情况,因为数据都存储在本地。此外,为了运行复杂的查询或执行批处理,需要动态地增加更多计算节点,以加快处理速度。
- 可伸缩性:系统必须能够根据负载和延迟要求,实现存储和计算资源的水平扩展或水平伸缩。对于计算资源来说,系统不难做出决定。但是存储资源就不一样了。要实现分布式数据库的伸缩,当数据实时写入,或者查询正在执行的时候,数据库的分片可能需要进行合并或分割。设计一个能够完成这一任务的系统并不容易。
- 自动化、可观测性:时序数据库的状态必须能与系统的其他组成部分一起被监控,所以一个好的时序数据库需要提供全面的可观测性。同时系统必须提供便于在 K8S 下自动化管理的接口,否则运营管理将变得复杂。
现在这个时候,任何新开发的时序数据库都必须是云原生的。虽然 TDengine 的设计从第一天起就是一个具有水平扩展、高可用、高可靠的的分布式架构,但目前的 2.x 还不能算为云原生数据库,因为它不支持存算分离,而且在云平台的部署和管理还较为欠缺。
4、方便易用 / Ease of use
尽管方便易用这个词有点主观,但是我们可以尝试在这里列出几点,从不同方面说说一个对开发者更友好的时序数据库应该做到哪些。
- 查询语言:因为 SQL 仍然是最流行的数据库查询语言,能支持 SQL,对开发者而言就没什么使用门槛了。另一方面,专用的查询语言需要开发者花费自己宝贵的时间来学习,还会增加向其他数据库迁移的成本。InfluxDB,OpenTSDB,Prometheus,RRDTool 等都不支持 SQL,但 TDengine 与 TimeScaleDB 支持 SQL。
- 交互式控制台:对开发者而言,使用一个交互式的控制台来管理运行的数据库或执行即席查询是最方便的。对于部署在云上的时序数据库也是如此。
- 示例代码:开发者往往不会花时间把整个文档通读一遍,而是直接学习如何使用某个特定的特性或 API。新的数据库必须用主流的编程语言提供示例代码,开发者只需要把这些代码复制粘贴到自己的应用中,如果需要的话再根据自己的具体情况稍加修改即可。
- 数据迁移工具:数据库管理系统需要提供一到多个方便高效的数据导入导出工具。源头和目标可能是一个文件、另一个数据库或者是远程数据中心中的一个副本。要迁移的数据可能是整个数据库,一组表,或者是一个指定时间段中的数据点。
技术的挑战
上面我总结了目前市场上时序数据库(Time Series Database)几大亟待解决的问题,包括 Scalability,Complex,Cloud Native 与 Ease of Use。这些问题,从技术上来看,都是硬骨头,否则早被厂商解决了。有问题,那就有机会。2016 年底,我就是由于研究后,发现 InfluxDB,TimeScaleDB,Prometheus,OpenTSDB 等有各种不足,才开始决定进入这个行业的。5 年多过去,我带领 TDengine 团队力图去解决这些问题,版本从最开始的 1.0,到 1.6,到 2.0、2.6,团队从 5 个人发展到了 80 多人,专职研发都已经超过 50 人。TDengine 与很多时序数据库相比,是一不错的产品,但遗憾的是,上述的问题还只是部分的解决。
作为一个坚信技术能改变世界的创始人,不解决这些问题难以入眠,难以证明自己以及整个团队的技术实力。因此在 2021 年 6 月,我决定正式启动 TDengine 3.0 的研发,投入了公司最大的资源,让所有研发同学专心新版本的研发,以解决上述技术难题为目标。TDengine 3.0 不仅要瞄准未来,成为一个云原生时序数据库,它还需要能支持 100 亿条时间线,100 个节点,让其具备极强的水平扩展和伸缩能力,彻底解决业内的“High Cardinality”问题。内置的流式计算、数据订阅、缓存等功能在时序数据场景下,要能完胜 Spark,Kafka,Redis 等通用场景下的工具。最终的目标就是降低时序数据处理系统的总拥有成本,帮助用户挖掘出数据的价值,让最终用户成功;而且让开发者用的顺手、用的放心,让开发者成功。
一年多过去,TDengine 的研发同学没日没夜的设计、编码和测试,TDengine 3.0 终于可以揭开面纱。我们决定在 8 月 13 日召开 TDengine 开发者大会,为大家详细揭秘 TDengine 3.0 的核心设计,并将 3.0 正式发布,在 GitHub 上公开其核心源代码。我们还邀请了业内的很多技术专家、投资人,以及我们的用户,共同奉上一整天的精彩分享。
8 月 13 日,我在 TDengine 开发者大会上等你。
边栏推荐
猜你喜欢
通过记账,了解当月收支情况
Distributed Lock-Redission - Cache Consistency Solution
XXL-JOB 分布式任务调度中心搭建

The growth path of a 40W test engineer with an annual salary, which stage are you in?

tf.cast(),reduce_min(),reduce_max()
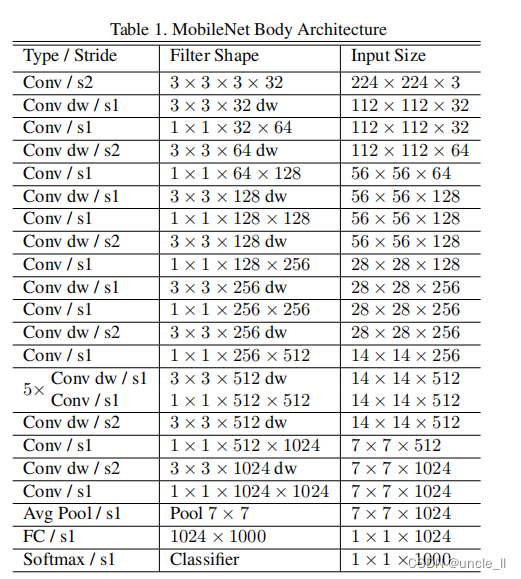
经典论文-MobileNet V1论文及实践
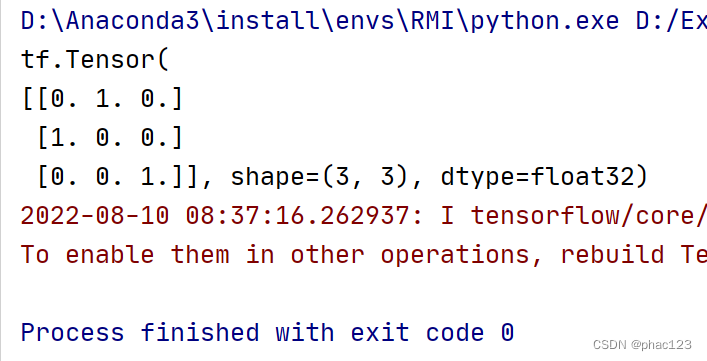
One-hot in TF
软件测试常用工具的用途及优缺点比较(详细)
1046 punches (15 points)
CSDN21天学习挑战赛——封装(06)
随机推荐
opengauss创建用户权限问题
通过记账,了解当月收支情况
FPGA 20个例程篇:11.USB2.0接收并回复CRC16位校验
快速幂,逆元的求解
关于架构的认知
C语言操作符详解
Four operations in TF
2.1 - Gradient Descent
1061 True or False (15 points)
JUC并发编程
One-hot in TF
go 操作MySQL之mysql包
麒麟V10系统打包Qt免安装包程序
测试用例很难?有手就行
[Recommender System]: Overview of Collaborative Filtering and Content-Based Filtering
为什么会没有内存了呢
go sqlx 包
装饰器模式:Swift 实现
流式结构化数据计算语言的进化与新选择
1.1-Regression