当前位置:网站首页>经典论文-MobileNet V1论文及实践
经典论文-MobileNet V1论文及实践
2022-08-11 07:00:00 【uncle_ll】
2017-MobileNetV1
MobileNets: Effificient Convolutional Neural Networks for Mobile Vision Applications
MobileNets:用于移动视觉应用的高效卷积神经网络
- 作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
- 单位:Google
摘要
我们提出了一类有效的模型,称为MobileNets, 专注于移动端和嵌入式视觉应用程序。MobileNets基于流线型架构,使用深度可分离卷积(depth-wise separable convolutions)来构建轻量级的深度神经网络。引入了两个简单的全局超参数,可以有效地在延迟和准确性之间进行权衡。这些超参数允许模型构建器根据问题的约束条件为其应用程序选择合适大小的模型。另外,我们做了大量权衡资源和准确性的实验,并显示了与其他流行的ImageNet分类模型相比也具有强大的性能。然后,演示了MobileNets在广泛的应用程序和用例中的有效性,包括目标检测、细粒度分类、人脸属性和大规模地理定位。
1 简介
自从AlexNet[19]赢得图像网挑战,ILSVRC 2012[24]而普及了深度卷积神经网络以来,卷积神经网络已经在计算机视觉中无处不在。总的趋势是建立更深、更复杂的网络,以实现更高的精度[27,31,29,8]。然而,这些提高精度的进步并不一定会使网络在模型大小和速度方面更有效。在许多现实世界的应用程序中,如机器人技术、自动驾驶汽车和增强现实技术,识别任务需要在一个计算量有限的平台上及时执行。
本文描述了一种高效的网络架构和一组两个超参数,以建立非常小的、低延迟的模型,可以很容易地匹配移动和嵌入式视觉应用程序的设计要求。第2节回顾了以前在小模型方面的工作,第3节描述了MobileNet体系结构和两个超参数宽度乘法器和分辨率乘法器来定义更小和更有效的MobileNet。第4节描述了在ImageNet上的实验以及各种不同的应用程序和用例。第5节以总结和结论结束。

2 前期工作
在最近的文献中,人们对建立小型和高效的神经网络越来越感兴趣,例如[16,34,12,36,22]。许多不同的方法通常可以分为压缩预训练网络或直接训练小网络。本文提出了一类网络架构,它允许模型开发人员专门为其应用程序选择一个与资源限制(延迟、大小)相匹配的小网络。MobileNets主要关注于优化延迟,但也产生小型网络。许多关于小型网络的论文只关注规模,而不考虑预测速度。
MobileNets主要由[26]中最初引入的深度可分离卷积构建,随后在初始模型[13]中使用,以减少前几层的计算。Flattened 网络[16]建立了一个完全分解卷积的网络,并显示了分解网络的潜力。独立于本文,分解网络[34]引入了类似的分解卷积以及拓扑连接的使用。随后, Xception网络[3]演示了如何扩大深度可分离过滤器,以完成执行 Inception V3网络。另一个小型网络是Squeezenet[12],它使用bottleneck方法来设计一个非常小的网络。其他简化的计算网络包括结构变换网络[28]和替换全连接层的Fastfood[37]。
获取小型网络的另一种方法是收缩、分解或压缩预先训练好的网络。基于乘积量化[36]的压缩,哈希[2]和剪枝。在文献[5]中已经提出了向量量化和霍夫曼编码,此外,还提出了各种分解来加速预训练的网络[14,20]。另一种训练小网络的方法是蒸馏[9],它使用更大的网络来教更小的网络。它是对我们的方法的补充,并在第4节的一些用例中介绍。另一种新兴的方法是低比特网络[4,22,11]。
3 MobileNet网络架构
在本节中,首先描述MobileNet所构建的核心层,即深度可分离的滤波器。然后,描述MobileNet网络结构,并描述了两个模型收缩超参数宽度乘法器和分辨率乘法器。
3.1 深度可分离卷积
MobileNet模型是基于深度可分离卷积,这是一种因分解卷积的形式,它将一个标准卷积分解为深度卷积和一种称为逐点卷积的1×1卷积。对于MobileNet,深度卷积对每个输入通道应用一个滤波器,然后组合逐点卷积1×1的卷积来输出的深度卷积。标准卷积在一步中过滤并将输入组合到一组新的输出中。深度可分离卷积将其分为两层,一个单独的层用于过滤,一个单独的层用于组合。这种因式分解d 的方式大大减少了计算量和模型的大小。图2中的2(a)显示了标准卷积如何被分解为深度卷积2(b)和1×1逐点卷积2。
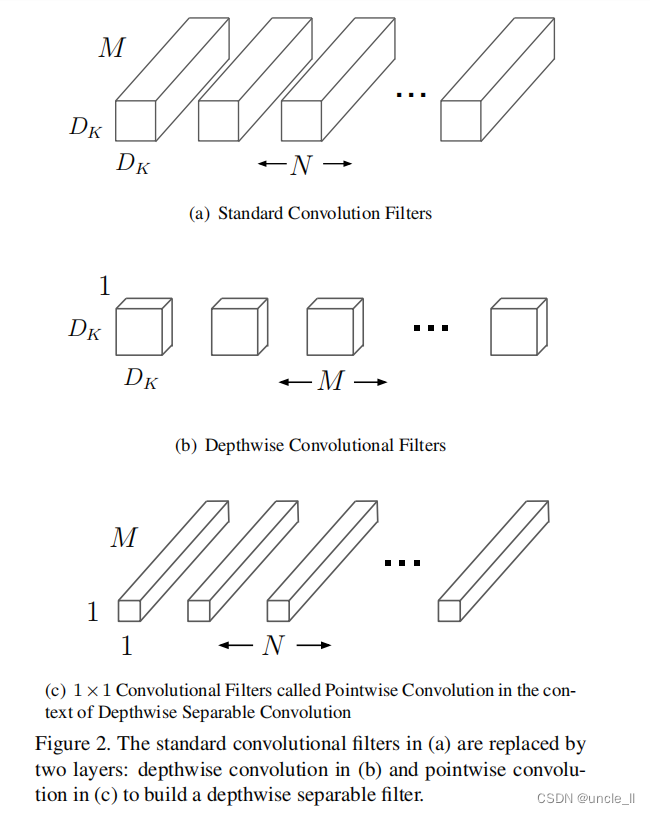
一个标准的卷积层以一个 D F × D F x M D_F×D_FxM DF×DFxM特征图F作为输入,然后产生一个 D G × D G × N D_G × D_G × N DG×DG×N
的特征图G, 其中 D F D_F DF是一个正方形输入特征图的空间宽度和高度,M为输入通道的数量(输入深度), D G D_G DG为正方形输出特征图的空间宽度和高度,N为输出通道的数量(输出深度)。
标准卷积层的参数化是由卷积核K大小确定的,总的参数为 D K × D K × M × N D_K×D_K×M×N DK×DK×M×N,其中 D K D_K DK是内核的空间维度,一般是平方的,M是输入通道和N是输出通道的数量如前面定义。
假设第一步和填充的标准卷积的输出特征映射计算为:

标准卷积的计算代价为:
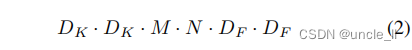
其中,计算代价以乘法的方式取决于输入通道数M,输出通道数N,核大小 D k × D k D_k×D_k Dk×Dk和特征映射大小 D F × D F D_F×D_F DF×DF。MobileNet模型解决了这些术语和它们之间的相互作用。首先,它使用深度可分离的卷积来打破输出通道的数量和内核的大小之间的相互作用。
标准的卷积运算具有基于卷积核对特征进行滤波和组合特征以产生新的表示形式的效果。过滤和组合步骤可以通过使用分解卷积分为两个步骤,可分离卷积可大大降低计算成本。
深度可分离卷积由两层组成:深度卷积和逐点卷积。使用深度卷积在每个输入通道(输入深度)上应用单个滤波器。逐点卷积,一个简单的1×1卷积,然后用来创建一个深度层输出的线性组合。MobileNets对这两层都使用了batchnorm和ReLU非线性。
每个输入通道(输入深度)有一个滤波器的深度卷积可以写为:

其中 ˆ K ˆK ˆK是大小为 D K × D K × M D_K×D_K×M DK×DK×M的深度卷积核,其中 ˆ K ˆK ˆK中的第m个滤波器应用于F中的第m个通道,以产生滤波输出特征图$ˆG4的第m个通道。深度卷积的计算代价为

深度卷积相对于标准卷积是非常有效的。但是,它只过滤输入通道,但它不结合它们来创建新的特性。因此,为了生成这些新特征,需要一个额外的层,通过1×1卷积计算深度卷积输出的线性组合。
深度卷积和1×1(逐点)卷积的组合被称为深度可分离卷积,它最初是在[26]中引入的。
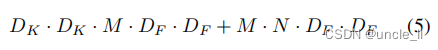
它是深度和1×1逐点卷积的和。
通过将卷积表示为两步组合的过程,得到了以下计算量的减少:
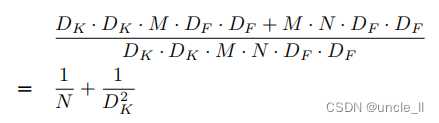
MobileNet使用3×3深度可分离卷积,其计算量比标准卷积少8到9倍,但精度降低幅度很小,如第4节所示。
空间维数中的附加因子分解,如[16,31],并不能节省太多额外的计算,因为在深度卷积中花费的计算很少。
3.2 网络结构与训练
MobileNet的结构是建立在前一节中提到的深度可分离卷积之上的,除了第一层,它是一个全卷积。通过用这样简单的术语来定义网络,能够很容易地探索网络拓扑来找到一个好的网络,在表1中定义了MobileNet架构。所有的层之后都有一个BatchNorm[13]和ReLU非线性激活,除了最后的全连接层,没有非线性,最后进入一个softmax层进行分类
在图3中,将具有规则的卷积、BatchNorm和ReLU非线性的层与深度卷积、1x1逐点卷积以及每个卷积层后的BatchNorm和ReLU非线性的层进行对比;在深度卷积和第一层中,均采用分层卷积来处理下采样。最终的平均池化将全连接层之前的空间分辨率降低到1。如果将深度卷积和逐点卷积作为独立的层话,MobileNet总共有28层。
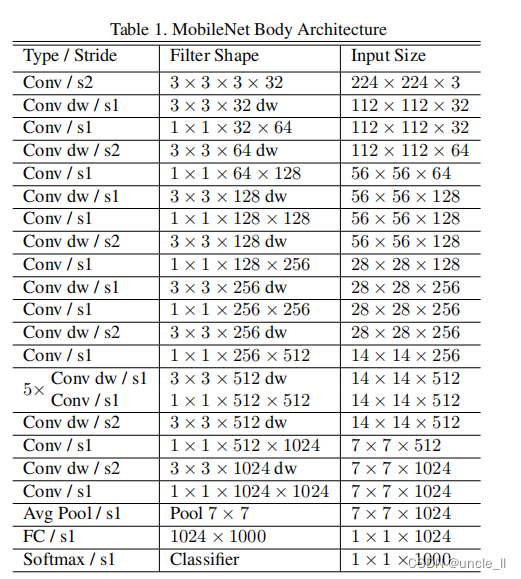

仅仅用少量的Mult-Adds来定义网络是不够的,确保这些操作能够有效地实现也很重要。例如,非结构化稀疏矩阵操作通常不会比密集矩阵操作快,直到非常高的稀疏性。本文提出的模型结构几乎将所有的计算都放在密集的1×1卷积中。这可以用高度优化的一般矩阵乘法(GEMM)函数来实现。卷积通常是由GEMM实现的,但需要在内存中进行一个称为im2col的初始重新排序,以便将其映射到GEMM。例如,在Caffe软件包中就使用了这种方法,**1×1卷积不需要在内存中进行这种重新排序,可以直接用GEMM来实现,这是最优化的数值线性代数算法之一。 ** MobileNet将95%的计算时间花费在1×1卷积中,其中也有75%的参数,如表2所示。几乎所有的附加参数都是在全连接层中。
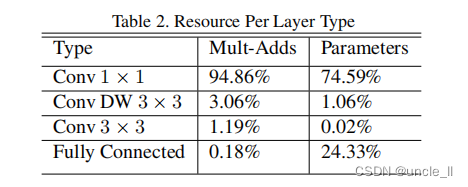
MobileNet模型在Tensorflow[1]中进行训练,使用类似于InceptionV3[31]中的RMSprop异步梯度下降算法。然而,与训练大型模型相反,本文使用较少的正则化和数据增强技术,因为小型模型在过拟合方面的问题较少。当训练MobileNets时,不使用side heads或label smooth标签平滑,并且通过限制在大型Inception训练[31]中使用的crop的大小来减少扭曲图像的数量。此外,我们发现在深度滤波器上放很少或没有权值衰减(l2正则化)是很重要的,因为它们的参数非常少, 对于下一节中的ImageNet基准,所有模型都使用相同的训练参数进行训练,而不考虑模型的大小。
3.3 宽度乘数:更细的模型
尽管基本的MobileNet架构已经很小且延迟也很低,但很多时候,一个特定的用例或应用程序可能需要模型更小、更快的模型。为了构造这些更小、计算成本更低的模型,引入了一个非常简单的参数α,称为宽度乘数。宽度乘数α的作用是在每一层均匀地瘦化一个网络。对于给定的层和宽度乘法器α,输入信道数M为αM,输出信道数N为αN。
与宽度乘积器α相结合的深度可分卷积的计算代价为:

其中,α∈(0,1]的典型设置为1, 0.75、0.5和0.25. α=1是基线网络,α<1是reduced MobileNets, 宽度乘数可以将计算成本和参数数二次降低约 α 2 α^2 α2。宽度乘数可以应用于任何模型结构,以定义一个新的更小的模型,具有合理的精度,延迟和尺寸权衡。它用于定义一个新的、需要从头开始进行训练的简化结构。
3.4 分辨率乘数:简化表达
降低神经网络计算成本的第二个超参数是分辨率乘数ρ。我们将此应用于输入图像,每一层的内部表示随后被相同的乘数减少。在实践中,通过设置输入分辨率来隐式地设置ρ。
现在可以将网络核心层的计算代价表示为具有宽度乘子α和分辨率乘子ρ的深度可分离卷积: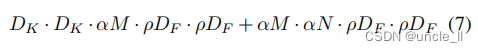
其中,ρ∈(0,1]通常被隐式设置,使网络的输入分辨率为224、192、160或128。ρ=1是基线MobileNets,ρ<1减少了MobileNets的计算量,分辨率乘数具有降低计算成本 ρ 2 ρ^2 ρ2的效果。
作为一个例子,可以看看MobileNet中的一个典型层,研究深度可分离卷积、宽度乘数和分辨率乘数是如何降低成本和参数的。表3显示了当架构收缩方法依次应用于层时,层的计算量和参数数量。第一行显示了一个完整卷积层的Mult-Adds参数,输入特征图大小为14×14×512,内核K大小为3×3×512×512。将在下一节中详细讨论资源和准确性之间的权衡。

4 实验
在本节中,首先研究了深度卷积的影响,以及通过减少网络的宽度而不是层数来进行收缩的选择。然后,展示了基于两个超参数:宽度乘数和分辨率乘数来减少网络的权衡,并将结果与一些流行的模型进行了比较。最后,研究了Mobile网应用于许多不同的应用。
4.1 模型选择
首先,展示具有深度可分离卷积的MobileNet与具有完全卷积的模型相比的结果。在表4中,可以看到,与完全卷积相比,使用深度可分离卷积在ImageNet上只会减少1%的准确率但极大地节省了大量的mult-adds操作和参数。接下来,展示**使用宽度乘数的较瘦模型和使用较少层的较浅模型的比较结果。**为了使MobileNet更浅,去掉了表1中特征尺寸为14×14×512的5层可分离滤波器。表5显示,在相似的计算和参数数量下,使MobileNets变瘦比使其变浅要好3%
4.2 模型缩小超参数
表6显示了使用宽度乘数α收缩MobileNet体系结构的准确性、计算量和大小权衡。精度会平稳下降直到α=0.25时。
表7显示了通过训练降低输入分辨率的MobileNets,对不同分辨率乘子的精度、计算量和大小上的权衡。精度在整个分辨率上平滑地下降。

图4显示了由宽度乘数α∈{1、0.75、0.5、0.25}和分辨率{224、192、160、128}的交叉乘积组成的16个模型的ImageNet精度和计算量之间的权衡。当模型在α=0.25时变得非常小时,结果是对数线性的跳跃。

图5显示了由宽度乘数α∈{1、0.75、0.5、0.25}和分辨率{224、192、160、128}组成的16个模型的图像精度和参数数量之间的权衡。
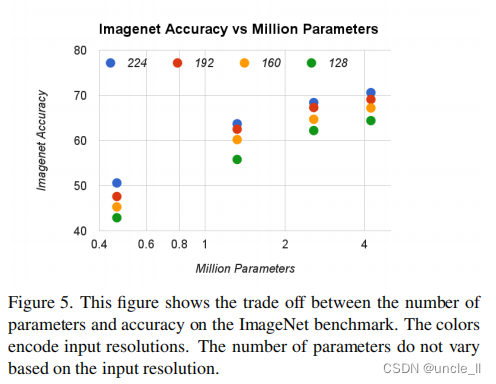
表8比较了完整的MobileNet与原来的GoogleNet[30]和VGG16[27]。MobileNet几乎和VGG16一样精确,但要小32倍,计算量要少27倍。它比GoogleNet更准确,但体积更小,计算量少了2.5倍以上。

表9比较了使用宽度乘法器α=0.5降低的移动网络与和降低分辨率160×160。减少的移动网络比AlexNet[19]好4%,而比AlexNet小45×,计算量少9.4×。在相同大小和22×的计算下,它也比[12]好4%。

4.3 细粒度识别
我们在Stanford Dogs数据集[17]上进行细粒度识别。我们扩展了[18]的方法,并从网络中收集了一个比[18]更大但更嘈杂的训练集。使用嘈杂的网络数据来预训练一个细粒度的狗识别模型,然后在Stanford Dogs训练集上对模型进行微调。Stanford Dogs测试集的结果见表10。MobileNet几乎可以在大大减少计算和大小的情况下实现来自[18]的最先进的结果。

4.4 大规模定位
PlaNet[35]将确定一张照片在地球何处拍摄的任务作为一个分类问题。该方法将地球划分为一个地理单元网格,作为目标类,并在数百万张带有地理标记的照片上训练一个卷积神经网络。PlaNet已经被证明能够成功地定位各种各样的照片,并优于处理相同任务的Im2GPS[6,7]。
我们在相同的数据上使用MobileNet架构重新训练PlaNet。而基于Inception V3架构的完整PlaNet模型[31]有5200万个参数和57.4亿次mult-adds操作。MobileNet模型只有1300万参数,通常网络有300万,最后一层是1000万以及58万次mult-adds操作。如表11中所示,MobileNet版本与PlaNet相比,虽然更紧凑,但性能仅略有下降。但是,它的性能仍然大大优于Im2GPS。

4.5 人脸属性
MobileNet的另一个用例是使用未知或神秘的训练程序压缩大型系统。在一个人脸属性分类任务中,演示了MobileNet和蒸馏[9]之间的协同关系,这是一种用于深度网络的知识迁移技术。试图减少一个具有7500万参数和16亿Mult-Adds操作的大型人脸属性分类器。该分类器是在一个类似于YFCC100M[32]的多属性数据集上进行训练的。
我们使用MobileNet架构提取一个人脸属性分类器。蒸馏[9]的工作原理是训练分类器模拟更大模型的输出,而不是真实标签,从而能够从大型(潜在的无限)未标记数据集进行训练。结合了蒸馏训练的可伸缩性和MobileNet的简约参数化,终端系统不仅不需要正则化(例如重量衰减和早期停止),而且还表现出了增强的性能。从表12中可以明显看出,基于MobileNet的分类器对激进的模型收缩具有弹性:它实现了与内部属性相似的平均平均精度(MAP),而只消耗1%的Multi-Adds操作。

4.6 目标检测
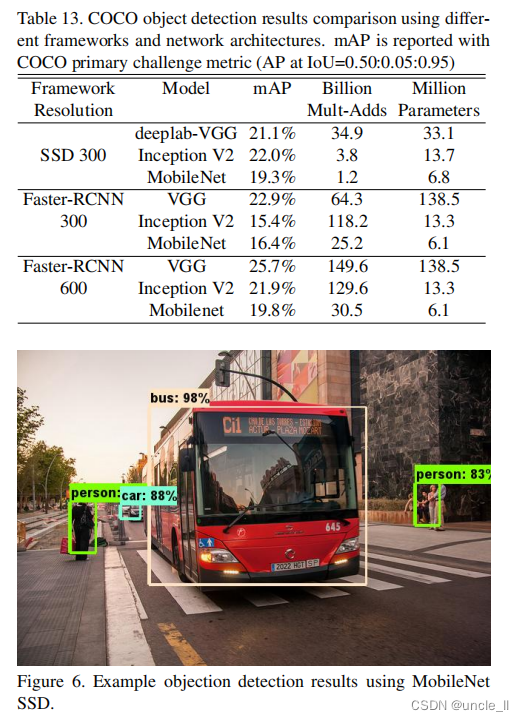
MobileNet也可以作为现代目标检测系统中有效的基础网络进行部署。基于最近赢得2016年COCO挑战[10]的工作,我们基于MobileNet进行的COCO数据目标检测训练的结果。在表13中,比较了MobileNet与VGG和Faster-RCNN[23]和SSD[21]框架进行了比较。在我们的实验中,SSD以300输入分辨率(SSD 300)进行评估,并将Faster-RCNN与300和600输入分辨率(Faster-RCNN 300,Faster-RCNN 600)进行了比较,Faster-RCNN模型评估每个图像的300个RPN建议框。模型在COCO训练+测试数据集上进行训练,不包括8k个微型图像,并对微型图像进行评估。对于这两种框架,MobileNet仅在计算复杂度和模型非常小的情况下获得了与其他网络相当的结果。
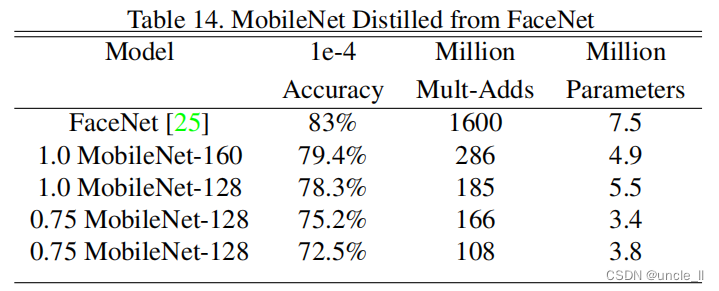
4.7 人脸Embeddings
FaceNet模型是一种最先进的人脸识别模型[25]。它基于triple loss损失构建人脸嵌入。为了建立一个移动端的FaceNet模型,我们使用蒸馏来最小化FaceNet和MobileNet对训练数据的平方差。对于非常小的MobileNet模型的结果见表14。
5 总结
我们提出了一种基于深度可分离卷积的新的模型体系结构,称为MobileNets。我们研究了一些导致有效模型的一些重要设计决策。然后,演示了如何使用宽度乘数和分辨率乘数来构建更小更快的移动网,通过权衡合理的精度来减少模型大小和延迟。然后,比较了不同的MobileNets网络和流行的模型,显示了优越的尺寸、速度和准确性的特点。最后,展示了MobileNets网络在应用于各种任务时的有效性。作为帮助采用和探索MobileNets的下一步,计划在TensorFlow中发布模型。
参考
M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al. Tensorflflow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflflow. org, 1, 2015. 4
W. Chen, J. T. Wilson, S. Tyree, K. Q. Weinberger, and Y. Chen. Compressing neural networks with the hashing trick. CoRR, abs/1504.04788, 2015.
F. Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357v2, 2016.
M. Courbariaux, J.-P. David, and Y. Bengio. Training deep neural networks with low precision multiplications. arXiv preprint arXiv:1412.7024, 2014.
S. Han, H. Mao, and W. J. Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. CoRR, abs/1510.00149, 2, 2015.
J. Hays and A. Efros. IM2GPS: estimating geographic information from a single image. In Proceedings of the IEEEInternational Conference on Computer Vision and Pattern Recognition, 2008. 7
J. Hays and A. Efros. Large-Scale Image Geolocalization. In J. Choi and G. Friedland, editors, Multimodal LocationEstimation of Videos and Images. Springer, 2014. 6, 7
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015. 1
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. 2, 7
J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. arXiv preprint arXiv:1611.10012, 2016. 7
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Quantized neural networks: Training neural networks with low precision weights and activations. arXivpreprint arXiv:1609.07061, 2016. 2
F. N. Iandola, M. W. Moskewicz, K. Ashraf, S. Han, W. J. Dally, and K. Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 1mb model size. arXivpreprint arXiv:1602.07360, 2016. 1, 6
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015. 1, 3, 7
M. Jaderberg, A. Vedaldi, and A. Zisserman. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014. 2
Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprintarXiv:1408.5093, 2014. 4
J. Jin, A. Dundar, and E. Culurciello. Flattened convolutional neural networks for feedforward acceleration. arXiv preprintarXiv:1412.5474, 2014. 1, 3
A. Khosla, N. Jayadevaprakash, B. Yao, and L. Fei-Fei. Novel dataset for fifine-grained image categorization. In FirstWorkshop on Fine-Grained Visual Categorization, IEEEConference on Computer Vision and Pattern Recognition, Colorado Springs, CO, June 2011. 6
J. Krause, B. Sapp, A. Howard, H. Zhou, A. Toshev, T. Duerig, J. Philbin, and L. Fei-Fei. The unreasonable effectiveness of noisy data for fifine-grained recognition. arXivpreprint arXiv:1511.06789, 2015. 6
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classifification with deep convolutional neural networks. In Advances in neural information processing systems, pages
1097–1105, 2012. 1, 6
V. Lebedev, Y. Ganin, M. Rakhuba, I. Oseledets, and V. Lempitsky. Speeding-up convolutional neural networks using fifine-tuned cp-decomposition. arXiv preprintarXiv:1412.6553, 2014. 2
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. Ssd: Single shot multibox detector. arXiv preprintarXiv:1512.02325, 2015. 7
M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi. Xnornet: Imagenet classifification using binary convolutional neural networks. arXiv preprint arXiv:1603.05279, 2016. 1, 2
S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015. 1
F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision andPattern Recognition, pages 815–823, 2015. 8
L. Sifre. Rigid-motion scattering for image classifification. PhD thesis, Ph. D. thesis, 2014. 1, 3
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 1, 6
V. Sindhwani, T. Sainath, and S. Kumar. Structured transforms for small-footprint deep learning. In Advances in Neural Information Processing Systems, pages 3088–3096, 2015. 1
C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261, 2016. 1
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015. 6
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015. 1, 3, 4, 7
B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland, D. Borth, and L.-J. Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016. 7
T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 4(2), 2012. 4
M. Wang, B. Liu, and H. Foroosh. Factorized convolutional neural networks. arXiv preprint arXiv:1608.04337, 2016. 1
T. Weyand, I. Kostrikov, and J. Philbin. PlaNet - Photo Geolocation with Convolutional Neural Networks. In EuropeanConference on Computer Vision (ECCV), 2016. 6, 7
J. Wu, C. Leng, Y. Wang, Q. Hu, and J. Cheng. Quantized convolutional neural networks for mobile devices. arXivpreprint arXiv:1512.06473, 2015. 1
Z. Yang, M. Moczulski, M. Denil, N. de Freitas, A. Smola, L. Song, and Z. Wang. Deep fried convnets. In Proceedingsof the IEEE International Conference on Computer Vision, pages 1476–1483, 2015. 1
实现
基于torch1.8版本实现
import os
import sys
import numpy as np
import pandas as pd
from typing import Any
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as f
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
# 设置gpu参数
os.environ['CUDA_VISIABLE_DIVICES'] = '0'
# 设置网络超参数
batch_size = 256
num_works = 4
lr = 1e-4
epochs = 100
image_size = 224
# 加载数据
from torchvision import datasets
train_data = datasets.CIFAR10(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.CIFAR10(root='./', train=False, download=True, transform=data_transform)
# 准备数据
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_works, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_works)
# 查看数据
image, label = next(iter(train_loader))
print(image.shape, label.shape)
# plt.imshow(image[0][0], cmap='gray')
# 构建模型
class MobileNetV1(nn.Module):
def __init__(self, input_dim, num_classes=1000):
super().__init__()
def conv_bn(inp, output, stride):
return nn.Sequential(
nn.Conv2d(inp, output, 3, stride, 1, bias=False),
nn.BatchNorm2d(output),
nn.ReLU(inplace=True)
)
def conv_dw_pw(inp, output, stride):
return nn.Sequential(
# depth wise
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# point wise
nn.Conv2d(inp, output, 1, 1, 0, bias=False),
nn.BatchNorm2d(output),
nn.ReLU(inplace=True)
)
self.model = nn.Sequential(
conv_bn(input_dim, 32, 2),
conv_dw_pw(32, 64, 1),
conv_dw_pw(64, 128, 2),
conv_dw_pw(128, 128, 1),
conv_dw_pw(128, 256, 2),
conv_dw_pw(256, 256, 1),
conv_dw_pw(256, 512, 2),
conv_dw_pw(512, 512, 1),
conv_dw_pw(512, 512, 1),
conv_dw_pw(512, 512, 1),
conv_dw_pw(512, 512, 1),
conv_dw_pw(512, 512, 1),
conv_dw_pw(512, 1024, 2),
conv_dw_pw(1024, 1024, 1),
nn.AdaptiveAvgPool2d(1)
)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
# 模型初始化
model = MobileNetV1(3, 1000).cuda()
# 定义优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 记录
from torch.utils.tensorboard import SummaryWriter
writer1 = SummaryWriter('./runs/loss')
writer2 = SummaryWriter('./runs/acc')
# train和test过程
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_loader.dataset)
writer1.add_scalar('loss', train_loss, epoch)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
# 设置评估状态
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
# 不设置梯度
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
# 计算验证集的平均损失
val_loss = val_loss /len(test_loader.dataset)
writer1.add_scalar('loss', val_loss, epoch)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
# 计算准确率
acc = np.sum(gt_labels ==pred_labels)/len(pred_labels)
writer2.add_scalar('acc', acc, epoch)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
writer1.close()
writer2.close()
Epoch: 1 Training Loss: 0.542552
Epoch: 1 Validation Loss: 1.102596, Accuracy: 0.636600
Epoch: 2 Training Loss: 0.456910
Epoch: 2 Validation Loss: 1.116227, Accuracy: 0.637100
Epoch: 3 Training Loss: 0.394289
Epoch: 3 Validation Loss: 1.163121, Accuracy: 0.642500
Epoch: 4 Training Loss: 0.332055
Epoch: 4 Validation Loss: 1.204307, Accuracy: 0.635500
Epoch: 5 Training Loss: 0.282552
Epoch: 5 Validation Loss: 1.317173, Accuracy: 0.632500
Epoch: 6 Training Loss: 0.241465
Epoch: 6 Validation Loss: 1.304476, Accuracy: 0.644200
Epoch: 7 Training Loss: 0.212577
Epoch: 7 Validation Loss: 1.297210, Accuracy: 0.652200
Epoch: 8 Training Loss: 0.174558
Epoch: 8 Validation Loss: 1.427903, Accuracy: 0.629300
Epoch: 9 Training Loss: 0.162358
Epoch: 9 Validation Loss: 1.316071, Accuracy: 0.655200
Epoch: 10 Training Loss: 0.151313
Epoch: 10 Validation Loss: 1.385027, Accuracy: 0.652200
Epoch: 11 Training Loss: 0.134953
Epoch: 11 Validation Loss: 1.348235, Accuracy: 0.652200
Epoch: 12 Training Loss: 0.112869
Epoch: 12 Validation Loss: 1.455159, Accuracy: 0.647700
Epoch: 13 Training Loss: 0.100508
Epoch: 13 Validation Loss: 1.478256, Accuracy: 0.655700
Epoch: 14 Training Loss: 0.104845
Epoch: 14 Validation Loss: 1.470615, Accuracy: 0.651800
Epoch: 15 Training Loss: 0.092965
Epoch: 15 Validation Loss: 1.486673, Accuracy: 0.652200
Epoch: 16 Training Loss: 0.093700
Epoch: 16 Validation Loss: 1.480290, Accuracy: 0.657300
Epoch: 17 Training Loss: 0.091183
Epoch: 17 Validation Loss: 1.496931, Accuracy: 0.659100
Epoch: 18 Training Loss: 0.093449
Epoch: 18 Validation Loss: 1.545923, Accuracy: 0.655500
Epoch: 19 Training Loss: 0.089333
Epoch: 19 Validation Loss: 1.656608, Accuracy: 0.652300
Epoch: 20 Training Loss: 0.080280
Epoch: 20 Validation Loss: 1.691422, Accuracy: 0.637400
Epoch: 21 Training Loss: 0.076340
Epoch: 21 Validation Loss: 1.553575, Accuracy: 0.667200
Epoch: 22 Training Loss: 0.074090
Epoch: 22 Validation Loss: 1.529634, Accuracy: 0.669000
Epoch: 23 Training Loss: 0.063183
Epoch: 23 Validation Loss: 1.581277, Accuracy: 0.667900
Epoch: 24 Training Loss: 0.059101
Epoch: 24 Validation Loss: 1.594428, Accuracy: 0.666500
Epoch: 25 Training Loss: 0.064686
Epoch: 25 Validation Loss: 1.653475, Accuracy: 0.659600
Epoch: 26 Training Loss: 0.072094
Epoch: 26 Validation Loss: 1.603179, Accuracy: 0.666100
Epoch: 27 Training Loss: 0.061241
Epoch: 27 Validation Loss: 1.615846, Accuracy: 0.668100
Epoch: 28 Training Loss: 0.064317
Epoch: 28 Validation Loss: 1.692577, Accuracy: 0.665700
Epoch: 29 Training Loss: 0.065329
Epoch: 29 Validation Loss: 1.705178, Accuracy: 0.661300
Epoch: 30 Training Loss: 0.062401
Epoch: 30 Validation Loss: 1.679631, Accuracy: 0.657900
Epoch: 31 Training Loss: 0.056963
Epoch: 31 Validation Loss: 1.773723, Accuracy: 0.665400
Epoch: 32 Training Loss: 0.052961
Epoch: 32 Validation Loss: 1.673505, Accuracy: 0.675400
Epoch: 33 Training Loss: 0.061805
Epoch: 33 Validation Loss: 1.882510, Accuracy: 0.648500
Epoch: 34 Training Loss: 0.056032
Epoch: 34 Validation Loss: 1.658725, Accuracy: 0.671600
Epoch: 35 Training Loss: 0.045075
Epoch: 35 Validation Loss: 1.644350, Accuracy: 0.677000
Epoch: 36 Training Loss: 0.043535
Epoch: 36 Validation Loss: 1.666007, Accuracy: 0.677900
Epoch: 37 Training Loss: 0.051126
Epoch: 37 Validation Loss: 1.714207, Accuracy: 0.672100
Epoch: 38 Training Loss: 0.054347
Epoch: 38 Validation Loss: 1.628756, Accuracy: 0.674000
Epoch: 39 Training Loss: 0.046926
Epoch: 39 Validation Loss: 1.661052, Accuracy: 0.674700
Epoch: 40 Training Loss: 0.049473
Epoch: 40 Validation Loss: 1.649359, Accuracy: 0.687500
Epoch: 41 Training Loss: 0.052907
Epoch: 41 Validation Loss: 1.650108, Accuracy: 0.684400
Epoch: 42 Training Loss: 0.048754
Epoch: 42 Validation Loss: 1.744841, Accuracy: 0.677700
Epoch: 43 Training Loss: 0.050814
Epoch: 43 Validation Loss: 1.673245, Accuracy: 0.683600
Epoch: 44 Training Loss: 0.040706
Epoch: 44 Validation Loss: 1.813371, Accuracy: 0.672600
Epoch: 45 Training Loss: 0.046347
Epoch: 45 Validation Loss: 1.720800, Accuracy: 0.680300
Epoch: 46 Training Loss: 0.039459
Epoch: 46 Validation Loss: 1.677644, Accuracy: 0.686300
Epoch: 47 Training Loss: 0.038748
Epoch: 47 Validation Loss: 1.794113, Accuracy: 0.670000
Epoch: 48 Training Loss: 0.037007
Epoch: 48 Validation Loss: 1.848523, Accuracy: 0.668700
Epoch: 49 Training Loss: 0.040037
Epoch: 49 Validation Loss: 1.804912, Accuracy: 0.674400
Epoch: 50 Training Loss: 0.038721
Epoch: 50 Validation Loss: 1.715275, Accuracy: 0.689200
Epoch: 51 Training Loss: 0.039992
Epoch: 51 Validation Loss: 1.801695, Accuracy: 0.671300
Epoch: 52 Training Loss: 0.039914
Epoch: 52 Validation Loss: 1.691090, Accuracy: 0.683200
Epoch: 53 Training Loss: 0.035851
Epoch: 53 Validation Loss: 1.692445, Accuracy: 0.692500
Epoch: 54 Training Loss: 0.032450
Epoch: 54 Validation Loss: 1.677598, Accuracy: 0.692100
Epoch: 55 Training Loss: 0.042038
Epoch: 55 Validation Loss: 1.776169, Accuracy: 0.673200
Epoch: 56 Training Loss: 0.037488
Epoch: 56 Validation Loss: 1.752145, Accuracy: 0.683700
Epoch: 57 Training Loss: 0.038894
Epoch: 57 Validation Loss: 1.721822, Accuracy: 0.683900
Epoch: 58 Training Loss: 0.045965
Epoch: 58 Validation Loss: 1.726646, Accuracy: 0.694800
Epoch: 59 Training Loss: 0.028319
Epoch: 59 Validation Loss: 1.672058, Accuracy: 0.700900
Epoch: 60 Training Loss: 0.027599
Epoch: 60 Validation Loss: 1.717727, Accuracy: 0.698900
Epoch: 61 Training Loss: 0.029994
Epoch: 61 Validation Loss: 1.676433, Accuracy: 0.695300
Epoch: 62 Training Loss: 0.035561
Epoch: 62 Validation Loss: 1.759827, Accuracy: 0.684600
Epoch: 63 Training Loss: 0.033197
Epoch: 63 Validation Loss: 1.749903, Accuracy: 0.693200
Epoch: 64 Training Loss: 0.031044
Epoch: 64 Validation Loss: 1.795904, Accuracy: 0.693800
Epoch: 65 Training Loss: 0.030796
Epoch: 65 Validation Loss: 1.743078, Accuracy: 0.688700
Epoch: 66 Training Loss: 0.034064
Epoch: 66 Validation Loss: 1.723591, Accuracy: 0.691700
Epoch: 67 Training Loss: 0.031070
Epoch: 67 Validation Loss: 1.715376, Accuracy: 0.696200
Epoch: 68 Training Loss: 0.033009
Epoch: 68 Validation Loss: 1.800107, Accuracy: 0.692200
Epoch: 69 Training Loss: 0.031370
Epoch: 69 Validation Loss: 1.707125, Accuracy: 0.700900
Epoch: 70 Training Loss: 0.030852
Epoch: 70 Validation Loss: 1.685999, Accuracy: 0.702800
Epoch: 71 Training Loss: 0.028473
Epoch: 71 Validation Loss: 1.732791, Accuracy: 0.697500
Epoch: 72 Training Loss: 0.039392
Epoch: 72 Validation Loss: 1.700891, Accuracy: 0.698900
Epoch: 73 Training Loss: 0.027731
Epoch: 73 Validation Loss: 1.695288, Accuracy: 0.699700
Epoch: 74 Training Loss: 0.024269
Epoch: 74 Validation Loss: 1.760297, Accuracy: 0.694400
Epoch: 75 Training Loss: 0.022800
Epoch: 75 Validation Loss: 1.713674, Accuracy: 0.698300
Epoch: 76 Training Loss: 0.022720
Epoch: 76 Validation Loss: 1.760442, Accuracy: 0.698500
Epoch: 77 Training Loss: 0.024492
Epoch: 77 Validation Loss: 1.793320, Accuracy: 0.700000
Epoch: 78 Training Loss: 0.024060
Epoch: 78 Validation Loss: 1.711711, Accuracy: 0.704400
Epoch: 79 Training Loss: 0.021388
Epoch: 79 Validation Loss: 1.719663, Accuracy: 0.703800
Epoch: 80 Training Loss: 0.028990
Epoch: 80 Validation Loss: 1.796706, Accuracy: 0.697200
Epoch: 81 Training Loss: 0.025605
Epoch: 81 Validation Loss: 1.716452, Accuracy: 0.704000
Epoch: 82 Training Loss: 0.030471
Epoch: 82 Validation Loss: 1.837791, Accuracy: 0.701600
Epoch: 83 Training Loss: 0.030337
Epoch: 83 Validation Loss: 1.726494, Accuracy: 0.703300
Epoch: 84 Training Loss: 0.030966
Epoch: 84 Validation Loss: 1.693119, Accuracy: 0.707400
Epoch: 85 Training Loss: 0.027364
Epoch: 85 Validation Loss: 1.655064, Accuracy: 0.712800
Epoch: 86 Training Loss: 0.024018
Epoch: 86 Validation Loss: 1.644200, Accuracy: 0.709800
Epoch: 87 Training Loss: 0.019428
Epoch: 87 Validation Loss: 1.693605, Accuracy: 0.705800
Epoch: 88 Training Loss: 0.020505
Epoch: 88 Validation Loss: 1.687958, Accuracy: 0.713800
Epoch: 89 Training Loss: 0.023152
Epoch: 89 Validation Loss: 1.728888, Accuracy: 0.711500
Epoch: 90 Training Loss: 0.024781
Epoch: 90 Validation Loss: 1.808021, Accuracy: 0.701900
Epoch: 91 Training Loss: 0.022800
Epoch: 91 Validation Loss: 1.739466, Accuracy: 0.707900
Epoch: 92 Training Loss: 0.027215
Epoch: 92 Validation Loss: 1.729207, Accuracy: 0.709000
Epoch: 93 Training Loss: 0.020297
Epoch: 93 Validation Loss: 1.739426, Accuracy: 0.709900
Epoch: 94 Training Loss: 0.021358
Epoch: 94 Validation Loss: 1.711817, Accuracy: 0.708100
Epoch: 95 Training Loss: 0.022679
Epoch: 95 Validation Loss: 1.677134, Accuracy: 0.714900
Epoch: 96 Training Loss: 0.028576
Epoch: 96 Validation Loss: 1.729768, Accuracy: 0.714400
Epoch: 97 Training Loss: 0.022231
Epoch: 97 Validation Loss: 1.688242, Accuracy: 0.719900
Epoch: 98 Training Loss: 0.020768
Epoch: 98 Validation Loss: 1.756792, Accuracy: 0.709500
Epoch: 99 Training Loss: 0.024385
Epoch: 99 Validation Loss: 1.798574, Accuracy: 0.705400

参考
边栏推荐
猜你喜欢


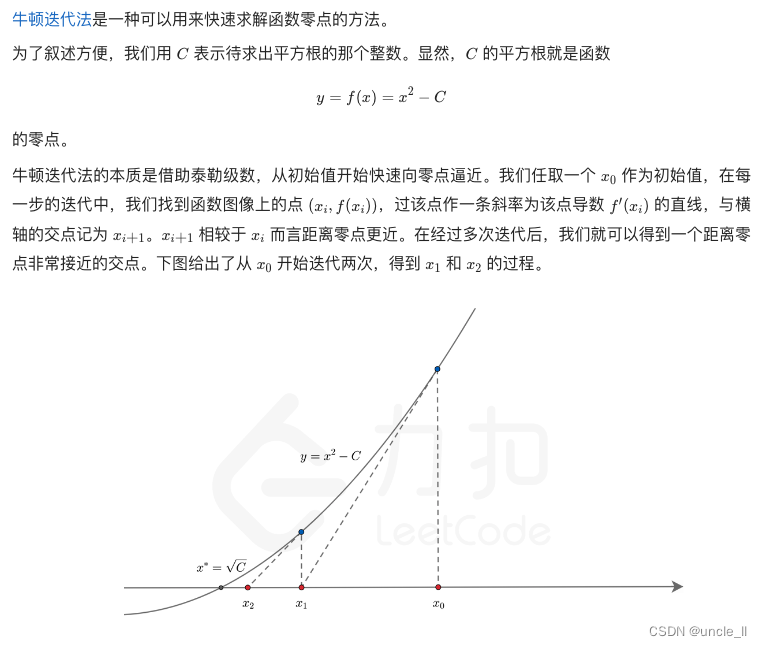


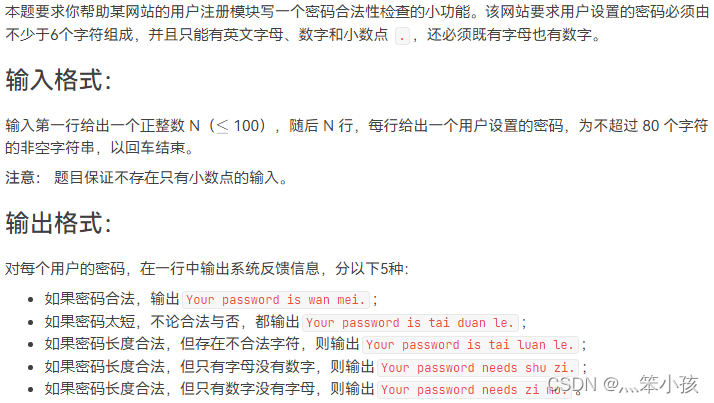
随机推荐
3.1-分类-概率生成模型
1106 2019数列 (15 分)
easyrecovery15数据恢复软件收费吗?功能强大吗?
机器学习总结(二)
TF中使用softmax函数;
Two startup methods and differences of Service
求职简历这样写,轻松搞定面试官
线程交替输出(你能想出几种方法)
DDR4内存条电路设计
【Pytorch】nn.PixelShuffle
C语言每日一练——Day02:求最小公倍数(3种方法)
为什么我使用C#操作MySQL进行中文查询失败
从何跟踪伦敦金最新行情走势?
1071 小赌怡情 (15 分)
1051 Multiplication of Complex Numbers (15 points)
The growth path of a 40W test engineer with an annual salary, which stage are you in?
matplotlib
Conditional statements in TF; where()
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
prometheus学习5altermanager