当前位置:网站首页>【图像分类】2022-ResMLP
【图像分类】2022-ResMLP
2022-08-10 02:02:00 【說詤榢】
文章目录
【图像分类】2022-ResMLP
论文题目:ResMLP: Feedforward networks for image classification with data-efficient training
论文链接:https://arxiv.org/abs/2105.03404
论文代码:https://github.com/facebookresearch/deit
论文翻译:https://blog.csdn.net/u014546828/article/details/120730429
发表时间:2021年5月
引用:Touvron H, Bojanowski P, Caron M, et al. Resmlp: Feedforward networks for image classification with data-efficient training[J]. arXiv preprint arXiv:2105.03404, 2021.
引用数:87
1. 简介
1.1 摘要
研究内容:本文提出了基于多层感知器的图像分类体系结构 ResMLP。
方法介绍:它是一种简单的残差网络,它可以替代
(i) 一个线性层,其中图像小块在各个通道之间独立而相同地相互作用,以及
(ii)一个两层前馈网络,其中每个通道在每个小块之间独立地相互作用。
实验结论:当使用使用大量数据增强和选择性蒸馏的现代训练策略进行训练时,它在 ImageNet 上获得了惊人的准确性/复杂度折衷。
本文还在自监督设置中训练 ResMLP 模型,以进一步去除使用标记数据集的先验。
最后,通过将模型应用于机器翻译,取得了令人惊讶的良好结果。
1.2 介绍
综上所述,本文得到以下几点观察:
• 尽管很简单,ResMLP 在仅 ImageNet-1k 训练的情况下达到了惊人的准确性/复杂性,而不需要基于批处理或通道统计数据的归一化;
• 这些模型显著受益于蒸馏方法;与基于数据增强的自监督学习方法兼容,如 DINO [7];
• 在机器翻译的 WMT 基准测试中,与 seq2seq transformer 相比,seq2seq ResMLP 实现了具有竞争力的性能。
2. 网络
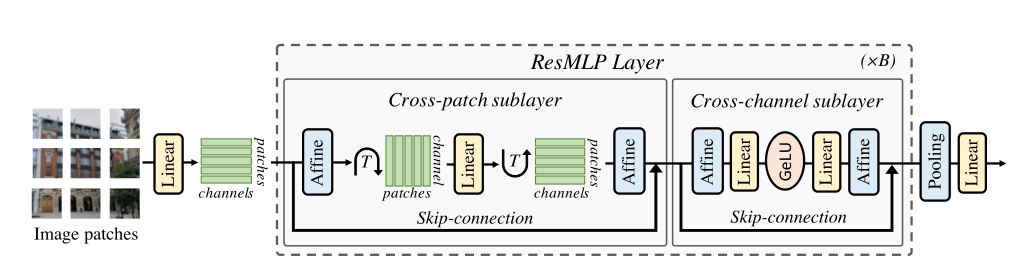
2.1 整体网络
ResMLP的网络结构如上图所示,网络的输入也是一系列的patch emmbeddings,模型的基本block包括一个linear层和一个MLP,其中linear层完成patchs间的信息交互,而MLP则是各个patch的channel间的信息交互(就是原始transformer中的FFN):
以图像 patch 为输入,将其投影为线性层,
ResMLP,以 N × N N×N N×N个不重叠的 patch 组成的网格作为输入,其中 patch 的大小通常等于 16 × 16 16×16 16×16。然后,这些 patches 独立通过一层线性层,形成一组 N 2 N^2 N2d维的embeddings。
然后通过两个残差操作依次更新其表示:
(i) 一个跨 patch 线性层,独立应用于所有通道;
(ii) 一个跨通道单层 MLP,独立应用于所有 patch 。
在网络的最后,patch 表示被平均池化,
并送入一个线性分类器。
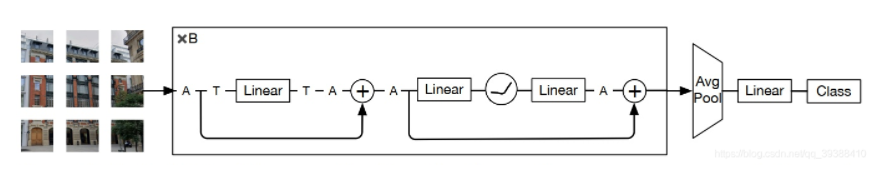
换个图也可以这么理解
2.2 Residual Multi-Perceptron Layer .
1) Aff操作(归一化操作)
ResMLP并
没有采用LayerNorm,而是采用了一种Affine transformation来进行norm,这种norm方式不需要像LayerNorm那样计算统计值来做归一化,而是直接用两个学习的参数α和β做线性变换:
self-attention 层的缺失使得训练更加稳定,允许用一个更简单的仿射变换替换层归一化,放射变换如公式 (1) 所示。其中 α \alpha α和 β \beta β是可学习的权向量。此操作仅对输入元素进行缩放和移动。
Aff α , β ( x ) = Diag ( α ) x + β \operatorname{Aff}_{\boldsymbol{\alpha}, \boldsymbol{\beta}}(\mathbf{x})=\operatorname{Diag}(\boldsymbol{\alpha}) \mathbf{x}+\boldsymbol{\beta} Affα,β(x)=Diag(α)x+β
与其他归一化操作相比,这个操作有几个优点:
- 首先,与 Layer Normalization 相比,它在推断时间上没有成本,因为它可以被相邻的线性层吸收。
- 其次,与 BatchNorm 和 Layer Normalization 相反, 操作符不依赖于批统计。
- 与 A f f Aff Aff更接近的算符是 Touvron et al. 引入的 LayerScale,带有额外的偏差项。
为方便起见,用 A f f ( X ) Aff(X) Aff(X)表示独立应用于矩阵 X 的每一列的仿射运算。
在每个残差块的开始 (“预归一化”) 和结束 (“后归一化”) 处应用 A f f Aff Aff算子,作为一种预规范化 A f f Aff Aff取代了 LayerNorm,而不使用通道统计。这里,初始化 α = 1, β = 0。作为后规范化, A f f Aff Aff类似于LayerScale
2) 流程
总的来说,本文的多层感知器将一组 N 2 N^2 N2d维的输入特征堆叠在一个 d × N 2 d\times N^2 d×N2矩阵X中,并输出一组 N 2 N^2 N2d维输出特征,堆叠在一个矩阵Y中,其变换集如 (3) 和 (4)。其中 A, B 和 C 是该层的主要可学习权矩阵。
Z = X + Aff ( ( A Aff ( X ) ⊤ ) ⊤ ) Y = Z + Aff ( C GELU ( B Aff ( Z ) ) ) \begin{array}{l} \mathbf{Z}=\mathbf{X}+\operatorname{Aff}\left(\left(\mathbf{A} \operatorname{Aff}(\mathbf{X})^{\top}\right)^{\top}\right) \\ \mathbf{Y}=\mathbf{Z}+\operatorname{Aff}(\mathbf{C} \operatorname{GELU}(\mathbf{B} \operatorname{Aff}(\mathbf{Z}))) \end{array} Z=X+Aff((AAff(X)⊤)⊤)Y=Z+Aff(CGELU(BAff(Z)))
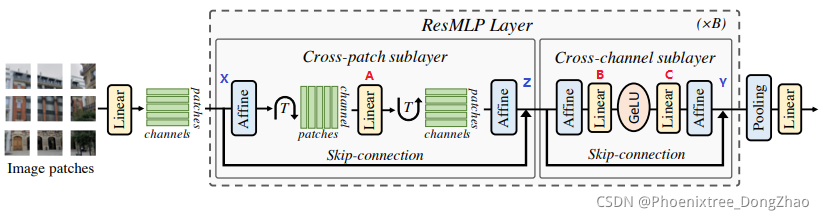
2.3 设计细节
ResMLP不像MLP-Mixer一样采用两个MLP,对于token mixing部分只是采用一个linear层。其实ResMLP的本意是将self-attention替换成MLP,而self-attention后面的FFN本身就是一个MLP,这样就和Google的MLP-Mixer一样了,但是最终实验发现替换self-attention的MLP中间隐含层的维度越大反而效果越差,索性就直接简化成a simple linear layer of size N × N;

2.4 总结
与 Vision Transformer 架构的差异:
ResMLP 体系结构与 ViT 模型密切相关。然而,ResMLP 与 ViT 不同,有几个简化:
• 无 self-attention 块:其被一个没有非线性的线性层所取代,
• 无位置 embedding:线性层隐式编码关于 embedding 位置的信息,
• 没有额外的 “class” tokens:只是在 patch embedding 上使用平均池化,
• 不基于 batch 统计的规范化:使用可学习的仿射运算符。
3. 代码
import torch
import torch.nn as nn
from functools import partial
from timm.models.vision_transformer import Mlp, PatchEmbed, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath
__all__ = [
'resmlp_12', 'resmlp_24', 'resmlp_36', 'resmlpB_24'
]
class Affine(nn.Module):
def __init__(self, dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones(dim))
self.beta = nn.Parameter(torch.zeros(dim))
def forward(self, x):
return self.alpha * x + self.beta
class layers_scale_mlp_blocks(nn.Module):
def __init__(self, dim, drop=0., drop_path=0., act_layer=nn.GELU, init_values=1e-4, num_patches=196):
super().__init__()
self.norm1 = Affine(dim)
self.attn = nn.Linear(num_patches, num_patches)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = Affine(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(4.0 * dim), act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x).transpose(1, 2)).transpose(1, 2))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
class resmlp_models(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12, drop_rate=0.,
Patch_layer=PatchEmbed, act_layer=nn.GELU,
drop_path_rate=0.0, init_scale=1e-4):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=int(in_chans), embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList([
layers_scale_mlp_blocks(
dim=embed_dim, drop=drop_rate, drop_path=dpr[i],
act_layer=act_layer, init_values=init_scale,
num_patches=num_patches)
for i in range(depth)])
self.norm = Affine(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
for i, blk in enumerate(self.blocks):
x = blk(x)
x = self.norm(x)
x = x.mean(dim=1).reshape(B, 1, -1)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def resmlp_12(pretrained=False, dist=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=12,
Patch_layer=PatchEmbed,
init_scale=0.1, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_12_dist.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_12_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlp_24(pretrained=False, dist=False, dino=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=24,
Patch_layer=PatchEmbed,
init_scale=1e-5, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_dist.pth"
elif dino:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_dino.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlp_36(pretrained=False, dist=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=36,
Patch_layer=PatchEmbed,
init_scale=1e-6, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_36_dist.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_36_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlpB_24(pretrained=False, dist=False, in_22k=False, **kwargs):
model = resmlp_models(
patch_size=8, embed_dim=768, depth=24,
Patch_layer=PatchEmbed,
init_scale=1e-6, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_dist.pth"
elif in_22k:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_22k.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
from thop import profile
model = resmlp_12(num_classes=1000)
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops/1e9))
print("params:{:.3f}M".format(params/1e6))
参考资料
边栏推荐
- 2022.8.9 Exam arrangement and transformation--1200 questions solution
- 小菜鸟河北联通上岗培训随笔
- Will signal with different start time alignment
- one of the variables needed for gradient computation has been modified by an inplace
- 【8.8】代码源 - 【不降子数组游戏】【最长上升子序列计数(Bonus)】【子串(数据加强版)】
- what is eabi
- 实例048:数字比大小
- What makes training multi-modal classification networks hard?
- 实例046:打破循环
- ArcGIS Advanced (1) - Install ArcGIS Enterprise and create an sde library
猜你喜欢

《GB39707-2020》PDF download
Open3D 泊松盘网格采样

数据库治理利器:动态读写分离

sqlmap dolog外带数据
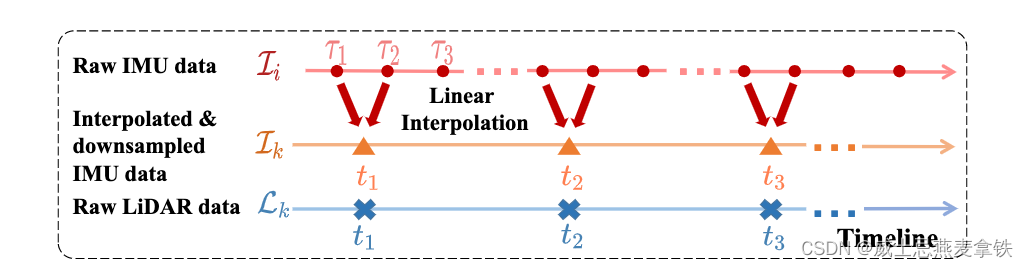
Robust Real-time LiDAR-inertial Initialization(实时鲁棒的LiDAR惯性初始化)论文学习
自动化测试中,测试数据与脚本分离以及参数化方法

How Microbes Affect Physical Health
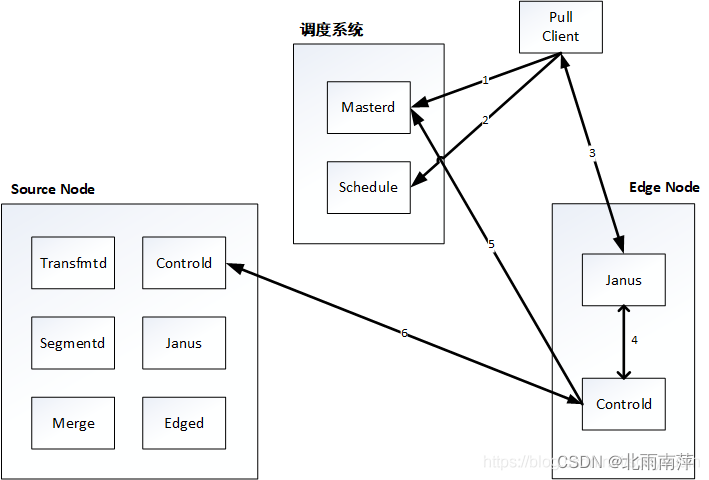
Janus actual production case
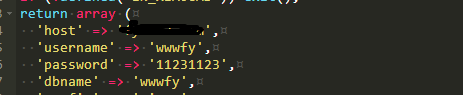
Pagoda server PHP+mysql web page URL jump problem
![[Kali Security Penetration Testing Practice Course] Chapter 9 Wireless Network Penetration](/img/7d/c621680ac73e2987f023a2e98e01df.png)
[Kali Security Penetration Testing Practice Course] Chapter 9 Wireless Network Penetration
随机推荐
2022.8.9考试排列变换--1200题解
自动化测试中,测试数据与脚本分离以及参数化方法
官宣出自己的博客啦
Golang nil的妙用
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
MySQL:日志系统介绍 | 错误日志 | 查询日志 | 二进制日志:bin-log数据恢复实践 | 慢日志查询
Screen 拆分屏幕
ArcGIS Advanced (1) - Install ArcGIS Enterprise and create an sde library
《GB39732-2020》PDF download
实例046:打破循环
如何让数据库中的数据同步
The 25th day of the special assault version of the sword offer
OpenCV图像处理学习二,图像掩膜处理
Data Governance (5): Metadata Management
将信号与不同开始时间对齐
谷歌翻译器-谷歌翻译器软件批量自动翻译
【机器学习】随机森林、AdaBoost、GBDT、XGBoost从零开始理解
QT模态对话框及非模态对话框学习
Redis - String|Hash|List|Set|Zset数据类型的基本操作和使用场景
2022.8.8考试游记总结