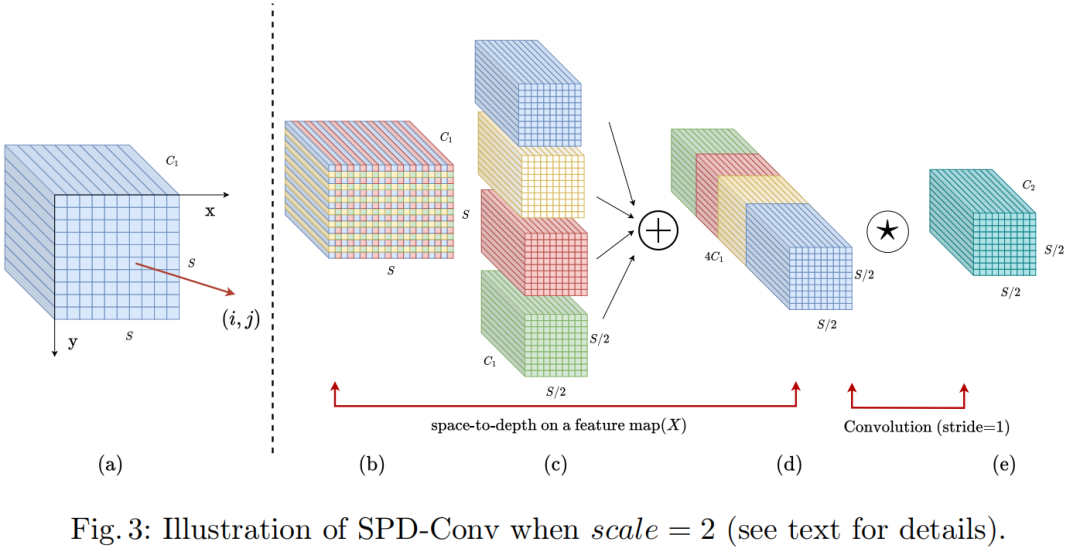
Convolutional Neural Networks (CNN) have achieved great success in many computer vision tasks such as image classification and object detection.However, their performance drops rapidly on tasks with low image resolution or small objects.
It is noted in this article that this stems from a flawed but common design in existing CNN architectures, namely the use of Stride convolutions and/or pooling layers, which lead to loss of fine-grained information and learning less efficient feature representations.To this end, this paper proposes a new CNN building block named SPD-Conv to replace each Stride Convolution layer and pooling layer(thus eliminating them entirely).
SPD-Conv from space to depth (SPD) layers and non-Stride convolution(Conv) layers and can be applied to most (if not all) CNN architectures.The authors explain this new design under the two most representative computer vision tasks: object detection and image classification.Then, a new CNN architecture is created by applying SPD-Conv to YOLOv5 and ResNet and empiricallyWe demonstrate that our method significantly outperforms state-of-the-art deep learning models, especially on tasks with low-resolution images and small objects.

Paper link:
https://arxiv.org/abs/2208.03641