当前位置:网站首页>【Mask2Former】 解决代码中一些问题
【Mask2Former】 解决代码中一些问题
2022-08-11 10:06:00 【宇宙爆肝锦标赛冠军】
取消终端输出网络结构
在运行 demo.py 时,终端会输出大量网络结构信息,影响调试代码。
需要在 Detectron2 中的 detectron2/utils/memory.py 中注释 log :
def wrapped(*args, **kwargs):
with _ignore_torch_cuda_oom():
return func(*args, **kwargs)
# Clear cache and retry
torch.cuda.empty_cache()
with _ignore_torch_cuda_oom():
return func(*args, **kwargs)
# Try on CPU. This slows down the code significantly, therefore print a notice.
logger = logging.getLogger(__name__)
# logger.info("Attempting to copy inputs of {} to CPU due to CUDA OOM".format(str(func))) # 会在终端打印出大量信息
new_args = (maybe_to_cpu(x) for x in args)
new_kwargs = {
k: maybe_to_cpu(v) for k, v in kwargs.items()}
return func(*new_args, **new_kwargs)
推理置信度设置
虽然官方的 Maks2Former 继承自 Detectron2 ,但是网络结构是重新编写的,也就是从图像输入到预测输出部分都是 Mask2Former 自己的网络代码,Detectron2 在网络返回预测结果之前做了非极大值抑制和置信度阈值筛选,但 Mask2Former 代码每次都输出 100 个实例,没有做阈值设定和非极大值抑制,效果就是很多实例 mask 重叠在一起,惨不忍睹。
修改 demo/predictor.py 中的 def run_on_image(self, image) 函数的以下内容:
if "instances" in predictions:
instances = predictions["instances"].to(self.cpu_device) # 类型: <class 'detectron2.structures.instances.Instances'>
# 取得分大于阈值的实例
instances_ = Instances(instances.image_size)
flag = False
for index in range(len(instances)):
print(instances[index].scores)
score = instances[index].scores[0]
if score > 0.75: # 置信度设置
if flag == False:
instances_ = instances[index]
flag = True
else:
instances_ = Instances.cat([instances_, instances[index]])
vis_output = visualizer.draw_instance_predictions(predictions=instances_)
预测实例存在多个轮廓
这里我将其中置信度大于一定的阈值的某个实例的 mask 单独输出,发现该实例存在不止一个轮廓,证明了误检的部分不是单独的实例,除了最大的那个轮廓,其他小轮廓是我们不需要的。
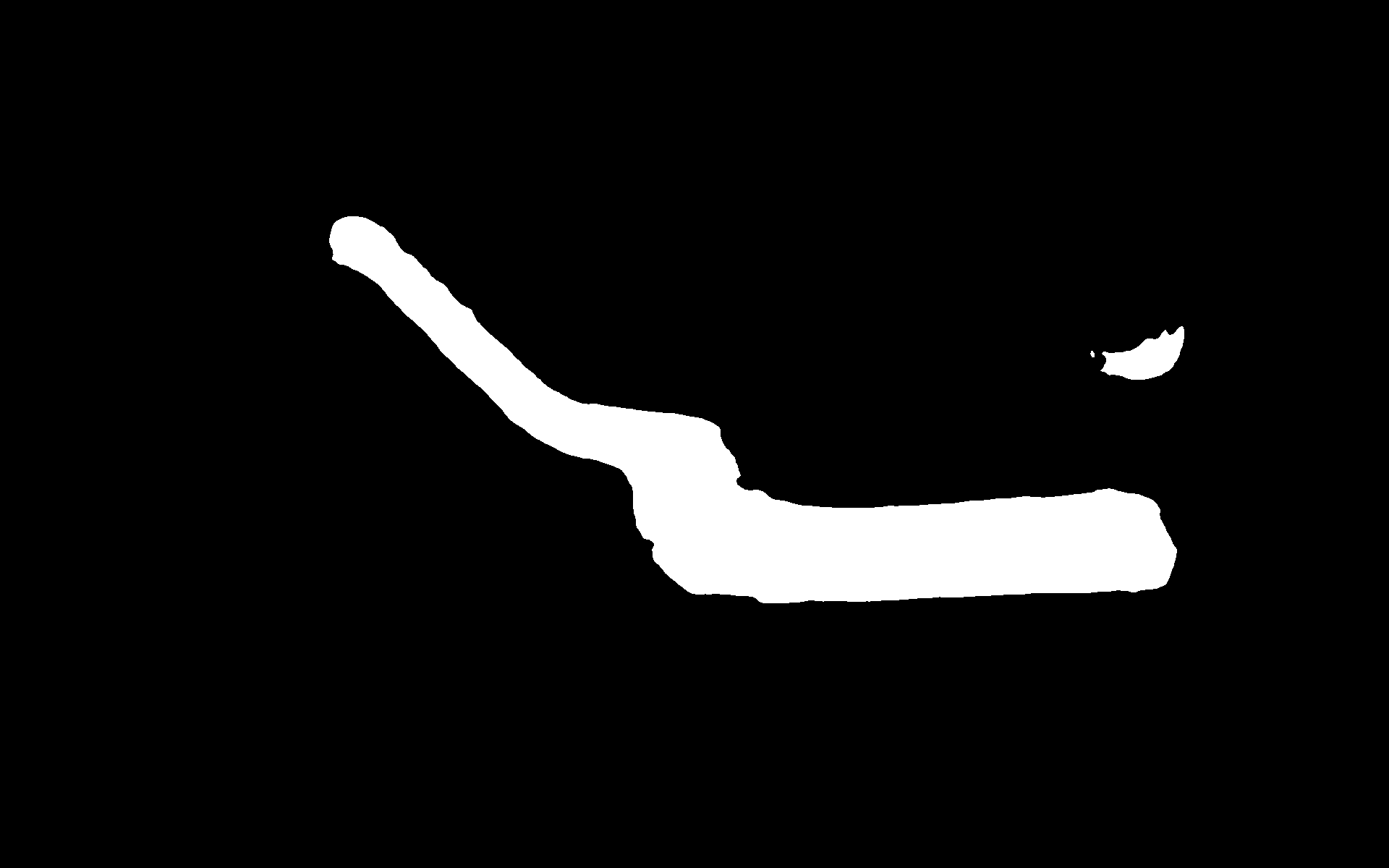
我选择对 mask 中的其他轮廓进行填充操作。instances[index].pred_masks = mask 这样无法对 Instances 对象的每个索引进行操作,只能对整个对象 pred_masks 进行赋值。在 Maks2Former 的 demo/predictor.py 中做修改:
if "instances" in predictions:
instances = predictions["instances"].to(self.cpu_device) # 类型: <class 'detectron2.structures.instances.Instances'>
# 取得分大于阈值的实例
instances_ = Instances(instances.image_size)
flag = False
for index in range(len(instances)):
score = instances[index].scores[0]
if score > 0.75:
print(instances.pred_masks.shape)
mask = torch.squeeze(instances[index].pred_masks).numpy()*255
import numpy as np
mask = np.array(mask, np.uint8) # 类型转换后才能输入查找轮廓
contours, hierachy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
areas = []
for cnt in contours:
areas.append(cv2.contourArea(cnt))
for cnt in contours:
if cv2.contourArea(cnt) < max(areas):
cv2.drawContours(mask, [cnt], contourIdx=-1, color=0, thickness=-1)
mask = torch.from_numpy(mask / 255).unsqueeze(0)
if flag == False:
instances_ = instances[index]
masks = mask
flag = True
else:
instances_ = Instances.cat([instances_, instances[index]])
masks = torch.cat((masks, mask), 0)
print(masks.shape)
instances_.pred_masks = masks
vis_output = visualizer.draw_instance_predictions(predictions=instances_)
预测模型返回筛选后实例
上面只是在绘制预测结果的进行了阈值筛选,在使用 Detectron2 框架下的评估脚本时,必须让模型返回筛选后的实例才行,否则还是返回 100 个实例,这样无法准确评估模型。
我将上面的脚本迁移到了 mask2former/maskformer_model.py 中,在脚本中设置自己需要的阈值即可,读者也可以自己添加一个阈值参数到配置文件中,然后在模型代码中读入这个阈值参数。具体代码实现如下:
def instance_inference(self, mask_cls, mask_pred):
# mask_pred is already processed to have the same shape as original input
image_size = mask_pred.shape[-2:]
# [Q, K]
scores = F.softmax(mask_cls, dim=-1)[:, :-1]
labels = torch.arange(self.sem_seg_head.num_classes, device=self.device).unsqueeze(0).repeat(self.num_queries, 1).flatten(0, 1)
# scores_per_image, topk_indices = scores.flatten(0, 1).topk(self.num_queries, sorted=False)
scores_per_image, topk_indices = scores.flatten(0, 1).topk(self.test_topk_per_image, sorted=False)
labels_per_image = labels[topk_indices]
topk_indices = topk_indices // self.sem_seg_head.num_classes
# mask_pred = mask_pred.unsqueeze(1).repeat(1, self.sem_seg_head.num_classes, 1).flatten(0, 1)
mask_pred = mask_pred[topk_indices]
# if this is panoptic segmentation, we only keep the "thing" classes
if self.panoptic_on:
keep = torch.zeros_like(scores_per_image).bool()
for i, lab in enumerate(labels_per_image):
keep[i] = lab in self.metadata.thing_dataset_id_to_contiguous_id.values()
scores_per_image = scores_per_image[keep]
labels_per_image = labels_per_image[keep]
mask_pred = mask_pred[keep]
result = Instances(image_size)
# mask (before sigmoid)
result.pred_masks = (mask_pred > 0).float()
result.pred_boxes = Boxes(torch.zeros(mask_pred.size(0), 4))
# Uncomment the following to get boxes from masks (this is slow)
# result.pred_boxes = BitMasks(mask_pred > 0).get_bounding_boxes()
# calculate average mask prob
mask_scores_per_image = (mask_pred.sigmoid().flatten(1) * result.pred_masks.flatten(1)).sum(1) / (result.pred_masks.flatten(1).sum(1) + 1e-6)
result.scores = scores_per_image * mask_scores_per_image
result.pred_classes = labels_per_image
# # 如果是实例分割,只保留大于阈值的
if self.instance_on:
import numpy as np
import cv2
instances_ = Instances(image_size)
instances = result.to(torch.device("cpu"))
flag = False
for index in range(len(instances)):
if instances[index].scores[0] > 0.9:
mask = torch.squeeze(instances[index].pred_masks).numpy()*255
mask = np.array(mask, np.uint8) # 类型转换后才能输入查找轮廓
contours, hierachy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
areas = []
for cnt in contours:
areas.append(cv2.contourArea(cnt))
for cnt in contours:
if cv2.contourArea(cnt) < max(areas):
cv2.drawContours(mask, [cnt], contourIdx=-1, color=0, thickness=-1)
mask = np.array(mask, np.float32)
mask = torch.from_numpy(mask / 255.0).unsqueeze(0)
if flag == False:
instances_ = instances[index]
masks = mask
flag = True
else:
instances_ = Instances.cat([instances_, instances[index]])
masks = torch.cat((masks, mask), 0)
instances_.pred_masks = masks
result = instances_
return result
边栏推荐
猜你喜欢
Oracle database use problems
神经网络参数如何确定的,神经网络参数个数计算
![[UE] 入坑](/img/18/a329706541e45eb0db4bf3f7f99973.png)
[UE] 入坑

同态加密简介HE
Primavera Unifier advanced formula usage sharing
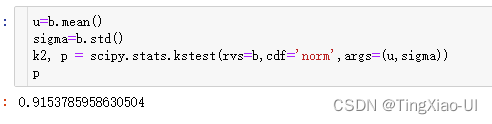
假设检验:正态性检验的那些bug——为什么对同一数据,normaltest和ktest会得到完全相反的结果?
疫情当前,如何提高远程办公的效率,远程办公工具分享
PowerMock for Systematic Explanation of Unit Testing

OAK-FFC Series Product Getting Started Guide

数字钱包红海角逐,小程序生态快速引入可助力占领智慧设备入口
随机推荐
数据库事务
【luogu CF1427F】Boring Card Game(贪心)(性质)
canvas图像阴影处理
php将form表单内容提交到数据库后中文变成??(问号)
MySQL表sql语句增删查改_修改_删除
深度神经网络与人脑神经网络哪些区域有一定联系?
Array, string, date notes [Blue Bridge Cup]
canvas图片操作
数据库 SQL 优化大总结之:百万级数据库优化方案
Network Models (DeepLab, DeepLabv3)
【Daily Question】640. Solving Equations
unity初级面试分享
单元测试系统化讲解之PowerMock
Primavera Unifier - AEM Form Designer Essentials
HStreamDB v0.9 released: Partition model extension, support for integration with external systems
A few days ago, Xiaohui went to Guizhou
算法---跳跃游戏(Kotlin)
Validate the execution flow of the interceptor
HDRP Custom Pass Shader 获取世界坐标和近裁剪平面坐标
基于卷积的神经网络系统,卷积神经网络毕业论文