当前位置:网站首页>数据库的索引和其底层数据结构
数据库的索引和其底层数据结构
2022-08-11 10:01:00 【最后一只三脚兽】
索引的CRUD
-- 查看索引
show index from 表名;
-- 创建索引
create index 索引名 on 表名(列名);
-- 删除索引
drop index 索引名 on 表名(列名);
创建和删除索引在大数据时都是极其耗时的操作,因为要用大量空间来创建(删除)对应的数据结构。因此大多数时候我们在创建表的最开始准备好索引
索引的数据结构
索引的存在是为了让数据查找的效率更高,因此我们需要一种合适的数据结构来保存这些数据
不合适的数据结构
谈到查找最快我们大多数人想法肯定是时间复杂度为O(1)的哈希表,但是哈希表虽然查询单个数据较快,查询范围数据时效率就达不到要求。
而二叉搜索树虽然查询单个数据和范围数据还可以,但是数据很有可能形成类似于单叉树的形式,这样的话时间复杂度就上升为了线性复杂度,同时搜索时的递归深度也是服务器无法接受的。
那么二叉搜索树升级以后的AVL树和红黑树又如何呢?AVL树和红黑树虽然避免了搜索可能的线性复杂度,但是在大量数据的堆砌下依旧会有很大的深度,在查询时会消耗大量空间。
在这个情况下B+树应运而生,了解B+树之前我们需要先了解一下B树(也有人写为B-树)
B树简单介绍
只是简单介绍B树的优势,不会具体深究插入删除的方式,节点内数据存储方式
B树是一个n叉树,且每个节点有多个数据,先上一个完整图:
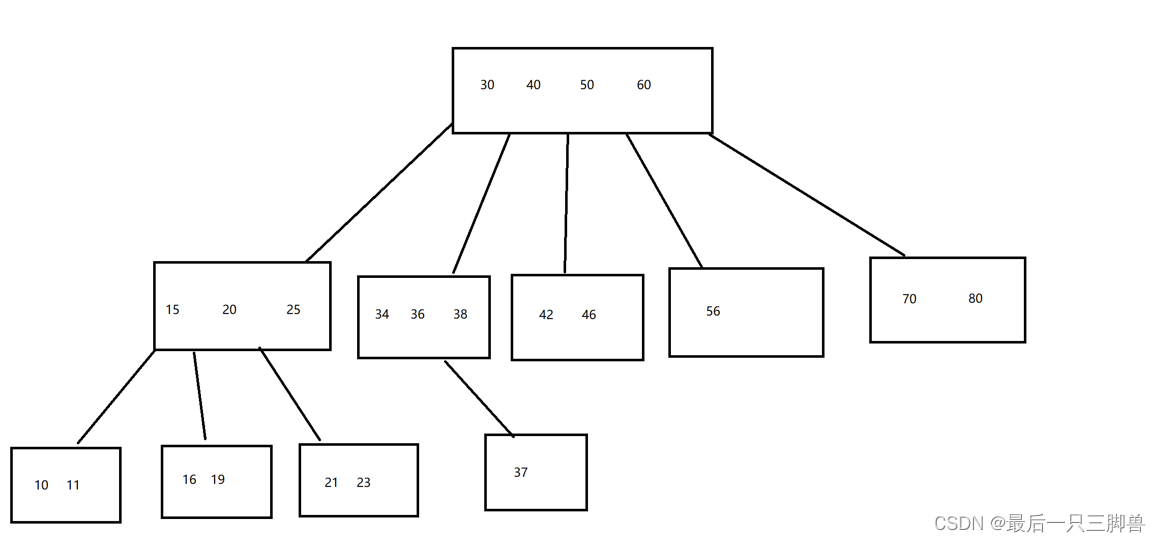
以父节点中的30和40为例,34、36、38属于30和40之间的数,因此就使用30和40范围的节点存储它们,一个节点有a个数,则它就有a+1个子节点。这就是B树内数据的存储方式
B+树简单介绍
介绍完了B树让我们来了解一下B+树的存储方式,并且分析为什么B+树如此受到数据库的青睐
B+树和B树一样也是一个n叉树,但与B树还有很大的不同,完整如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZSzG561F-1660093289930)(C:\Users\yang\AppData\Roaming\Typora\typora-user-images\image-20220809173241303.png)]](/img/4b/aed2636a7b487ffe7a0f54097e553d.png)
- B+树一个节点有a个数,则其子节点有a个
- 父节点中作为右边界的数会在子节点中再次出现,如上图根节点8~15之间作为右边界的15又一次存放在了子节点。
- 由于每次取边界其右的数到子节点,B+树的叶子节点就保存了所有的数。我们最后把叶子节点以链表形式连接起来。
了解了B+树的数据存储方式,让我们简单聊聊B+树的优势:
- 首先作为一个n叉树,它的深度相比于二叉树大大减少。
- B+树的叶子节点储存了所有数据,我们进行范围查找时只要找到一个数就可以直接通过链表遍历所需范围。
- 由于叶子节点存储了所有数据,我们的所有查找操作都可以放在叶子节点进行,而非叶子节点内我们只需要存放索引即可,索引所代表的数据全部存储在叶子节点中。由于索引只是一串数字,空间占用很小,这样查找大大减少了硬盘IO,这也是红黑树等树可望而不可即的!
虽然我们在这里并不谈B+树的插入效率,但我们能够直观感受到其数据插入和删除的困难,但如开始所说数据库更多需要的还是查找效率,这种交换是值得的,但如果是插入删除极其频繁的数据库则不应该使用索引。
边栏推荐
猜你喜欢

HDRP shader to get shadows (Custom Pass)
单元测试系统化讲解之PowerMock
Primavera P6 Professional 21.12 登录异常案例分享
pycharm cancel msyql expression highlighting
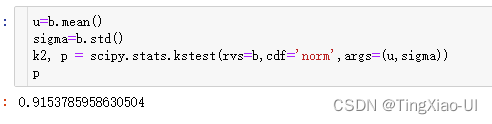
假设检验:正态性检验的那些bug——为什么对同一数据,normaltest和ktest会得到完全相反的结果?
训练一个神经网络要多久,神经网络训练时间过长
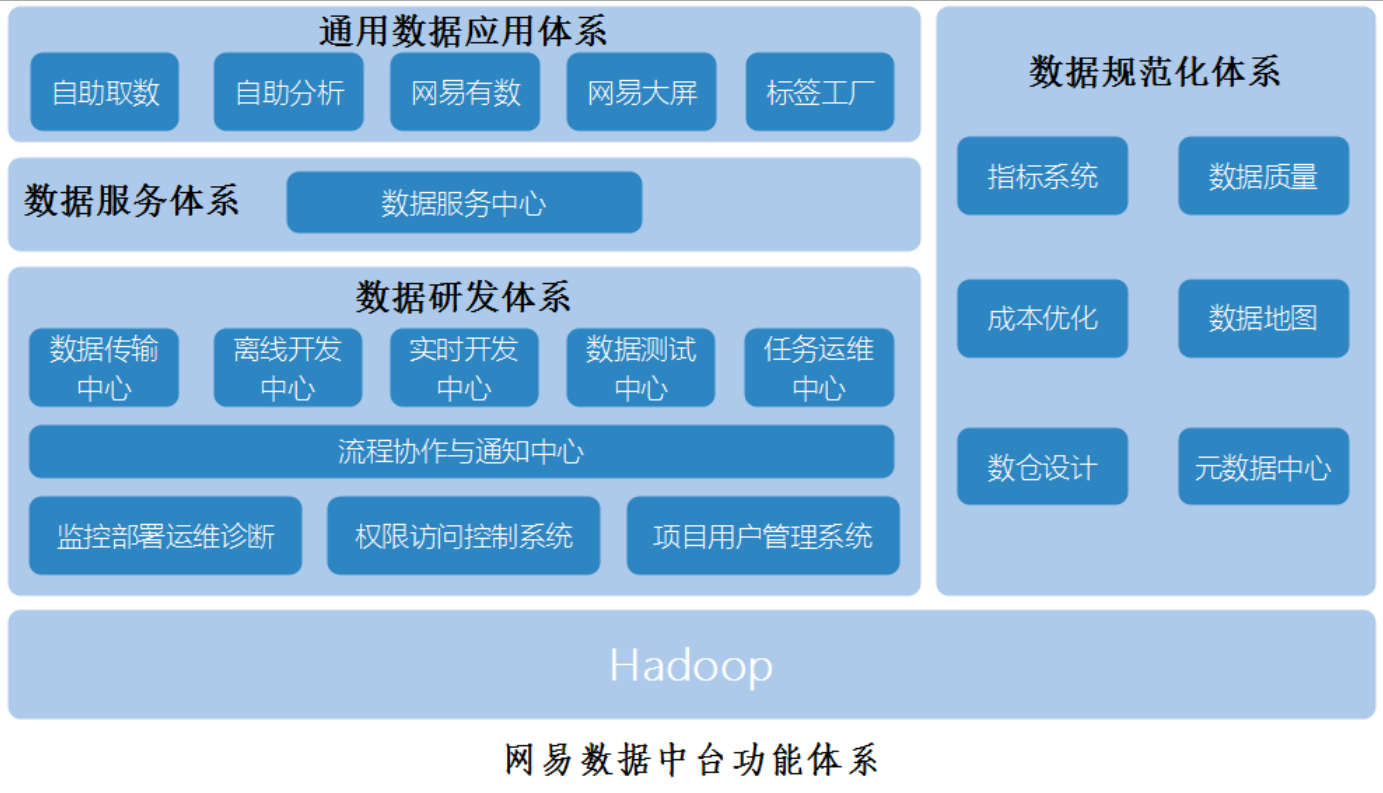
数据中台方案分析和发展方向

Software custom development - the advantages of enterprise custom development of app software
Oracle database use problems
华为WLAN技术:AC/AP 实验
随机推荐
A few days ago, Xiaohui went to Guizhou
收集awr
MySQL数据库基础_常用数据类型_表设计
1002 A+B for Polynomials
浮点型在内存中的存储
MySQL表sql语句增删查改_修改_删除
【luogu CF1427F】Boring Card Game(贪心)(性质)
logstash/filebeat只接收最近一段时间的数据
Database Basics
mindspore中MindDataset读取mindrecord文件问题
神经网络图怎么分析,画神经网络结构图
神经网络需要的数学知识,神经网络的数学基础
How to use QTableWidget
爬虫封装成api
Primavera Unifier -AEM 表单设计器要点
卷积神经网络梯度消失,神经网络中梯度的概念
数字钱包红海角逐,小程序生态快速引入可助力占领智慧设备入口
同态加密简介HE
HStreamDB v0.9 released: Partition model extension, support for integration with external systems
Primavera Unifier 自定义报表制作及打印分享